There are no items in your cart
Add More
Add More
| Item Details | Price | ||
|---|---|---|---|

If you’ve spent time working with machine learning projects, you know the struggles: models that work perfectly on a laptop collapse in production, workflows turn into unreadable scripts, and sharing your results with teammates is a nightmare. That’s where ZenML comes in—offering a unified, open-source MLOps framework to help you orchestrate, automate, and scale end-toend machine learning workflows. In this guide, we’ll take a deep dive into ZenML, from its fundamental architecture to complex, real-world uses. Expect code, visuals, practical examples, and an expert eye toward making this the most thorough ZenML resource you’ll find.
ZenML is an open-source MLOps framework that acts like the nervous system of your machine learning lifecycle. It structures and automates the entire ML workflow—so you don’t need to worry about spaghetti-code pipelines, missing dependencies, or lost experiment results. Instead, your code, models, and metadata are versioned, modular, and instantly reproducible, whether you’re running locally, on Kubernetes, or in a multi-cloud environment.
But ZenML is much more than just a pipeline runner. It’s the result of years of frustration in the ML world, distilled into a tool designed for both code-first engineers and team-driven collaboration. The framework’s guiding philosophy is "keep ML workflows zen"—organized, traceable, and robust enough for real-world deployment, audit, and improvement.
High-level block diagram showing how ZenML fits into the ML lifecycle, with labeled pipeline steps and integrations (e.g., orchestrator, step, artifact store, experiment tracker, deployment, monitoring, serving, cloud providers).
Let’s peel back the layers and see how ZenML is built for scale and flexibility.
Example:
You can create one pipeline for experimentation (fast local runs, basic metrics), and another for production (with data validation, monitoring, A/B testing, and CI/CD triggers), all using the same steps and logic.
Every step does one thing—like transforming data, training a model, evaluating metrics, or serving predictions. Steps are decorated Python functions, making them testable, reusable, and easy to document.
Steps:
Artifacts—like datasets, feature matrices, model binaries, and results—are the physical outputs of your steps. The artifact store is a versioned, pluggable storage backend supporting local disks, cloud storage (S3, GCS, Azure), and even advanced filesystems such as MinIO.
ZenML ensures:
The ZenML "stack" is your configuration hub. It connects pipeline code to real infrastructure, specifying:
Diagram showing a ZenML pipeline: steps, stack, artifact store, experiment tracker, orchestrator, with arrows showing flow and dependencies.
First things first: let’s get ZenML running in your environment.
pip install zenml
zenml init
This command scaffolds your project to make it ZenML-aware, creating an internal .zenml folder with all config and metadata.
First Run:
Fire up your ZenML dashboard to explore runs, stacks, and more
zenml up
Visit localhost:8237 for the dashboard UI.
Let’s build a pipeline that ingests numbers, multiplies them, and outputs the result:
from zenml.pipelines import pipeline
from zenml.steps import step
# Step to load a number
@step
def load_num() -> int:
return 10
# Step to square the number
@step
def square(num: int) -> int:
return num * num
# Define a simple math pipeline
@pipeline
def simple_math_pipeline(load_num, square):
n = load_num()
result = square(n)
return result
pipeline_instance = simple_math_pipeline(load_num=load_num(), square=square())
pipeline_instance.run()Features to note:
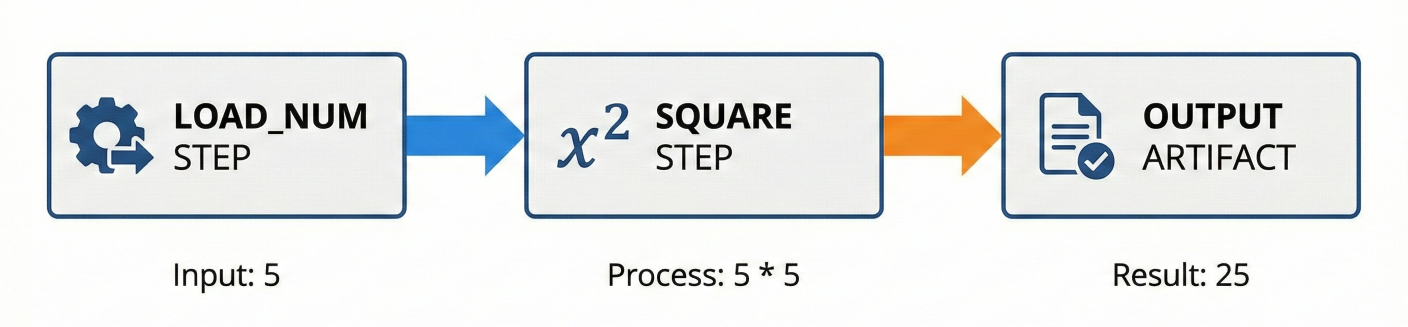
Pipeline illustration for the math example: load_num step -> square step -> output artifact.
ZenML pipelines aren’t just for toy projects—real ML workflows involve multiple steps, dynamic branching, data validation, metrics aggregation, and sometimes multiple models.
Let’s expand with more realistic steps:
Example: Full ML Pipeline for Image Classification
Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the industry's standard dummy text ever since the 1500s, when an unknown printer took a galley of type and scrambled it to make a type specimen book.
You can swap out individual steps (e.g., change preprocess logic, switch model type) without rewriting the rest, reusing code across projects and teams.
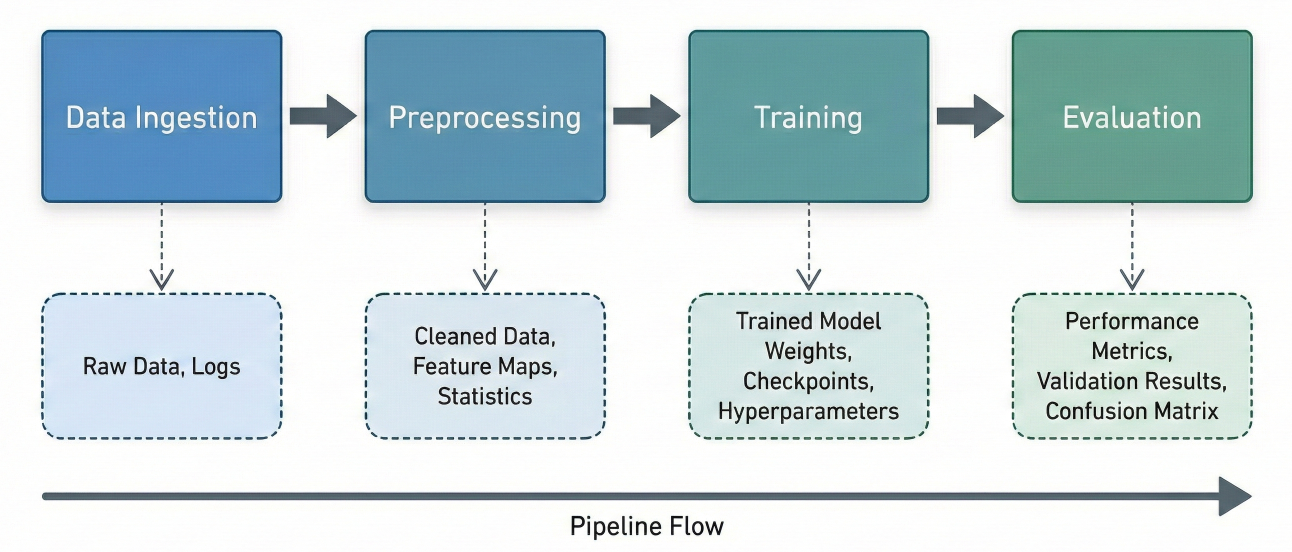
Block diagram of a typical ML pipeline: Data Ingestion → Preprocessing → Training → Evaluation steps, each producing tracked artifacts.
Running code locally is fast, but fragile. Real-world workloads quickly outgrow your laptop. ZenML abstracts away the backend, so today’s experiment becomes tomorrow’s cloud job— with a swap of the orchestrator in your stack config.
Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the industry's standard dummy text ever since the 1500s, when an unknown printer took a galley of type and scrambled it to make a type specimen book.
No code changes, no drama
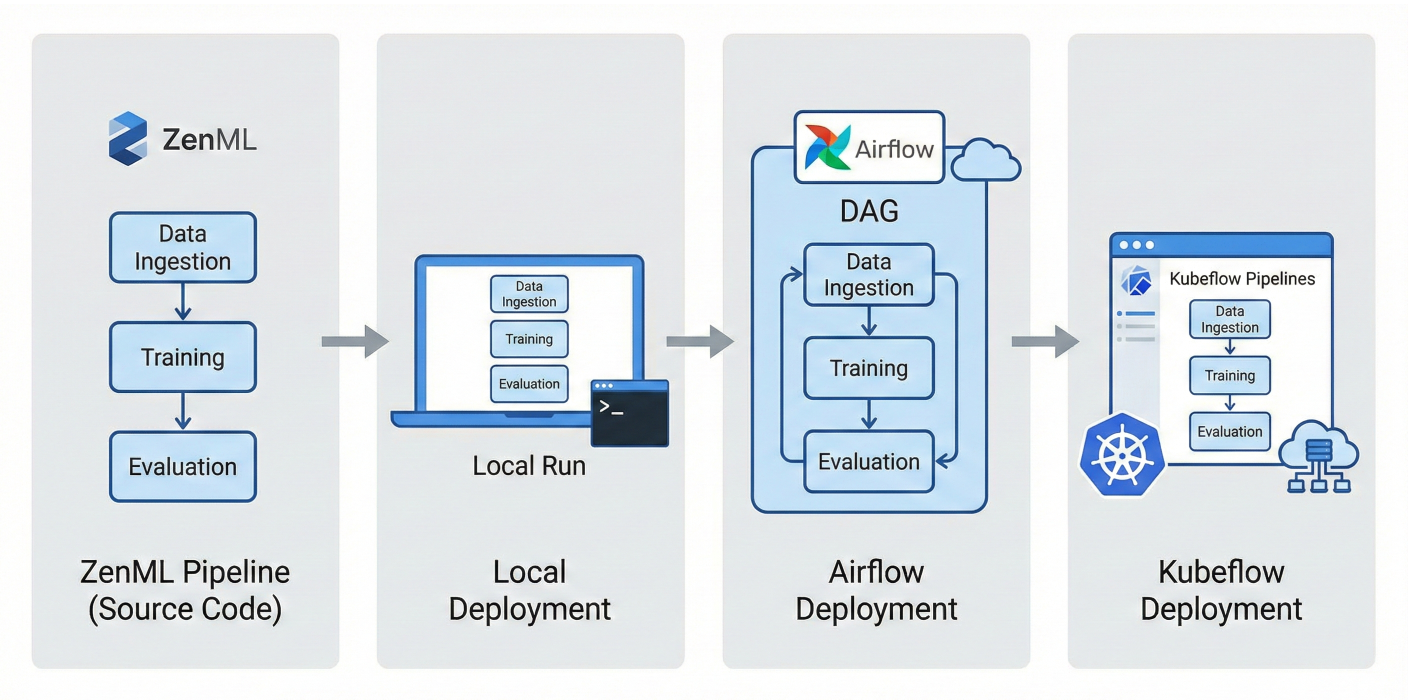
ZenML pipeline deployment illustration: showing the same pipeline deployed locally, then on Airflow, then on Kubeflow.
For every pipeline run:
The result? You always know, for every model version:
Lineage tracking diagram: Data Source → Preprocessing Artifact → Training Step Artifact → Model Artifact, all versioned with metadata.
ZenML has native experiment tracking, but also plugs in with:
Code snippet: MLflow Integration
from zenml.integrations.mlflow.steps import mlflow_tracking_step
@pipeline
def my_pipeline(..., mlflow_tracking):
...
mlflow_tracking(...)
Just add the tracker to your stack, call the tracking step, and all key info gets logged.
A reproducible ML system means you can:
ZenML nails this by:
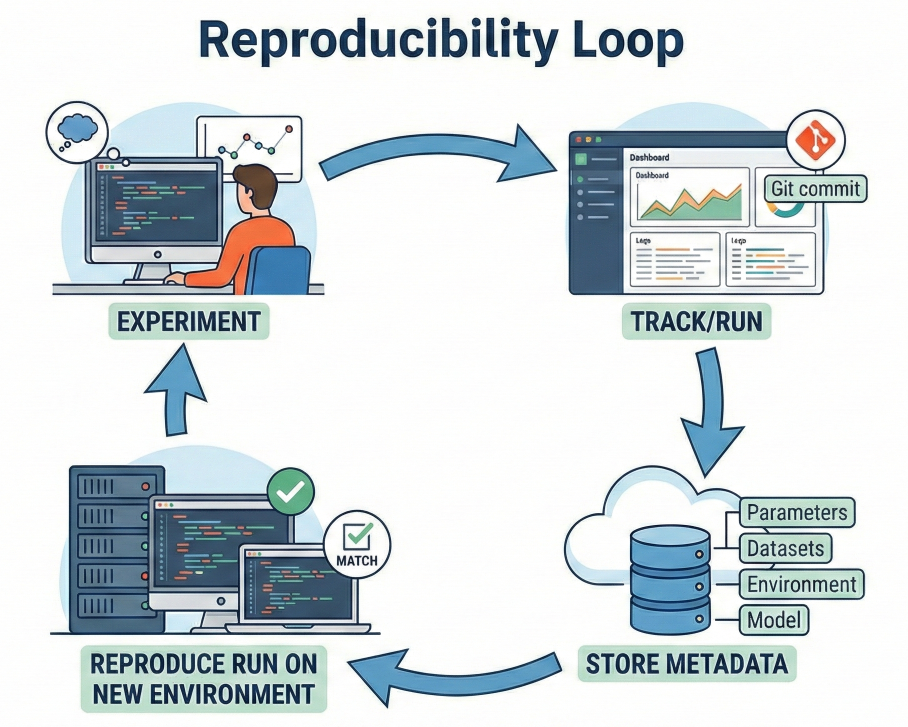
Diagram: ‘Reproducibility loop’ showing experiment, track/run, store metadata, reproduce run on new environment
ZenML is not an island—it’s built to work with the best tools in the industry:
You can extend ZenML with your own flavors and integrations by developing plug-ins. See the ZenML docs for creating custom orchestrators, artifact stores, and more.
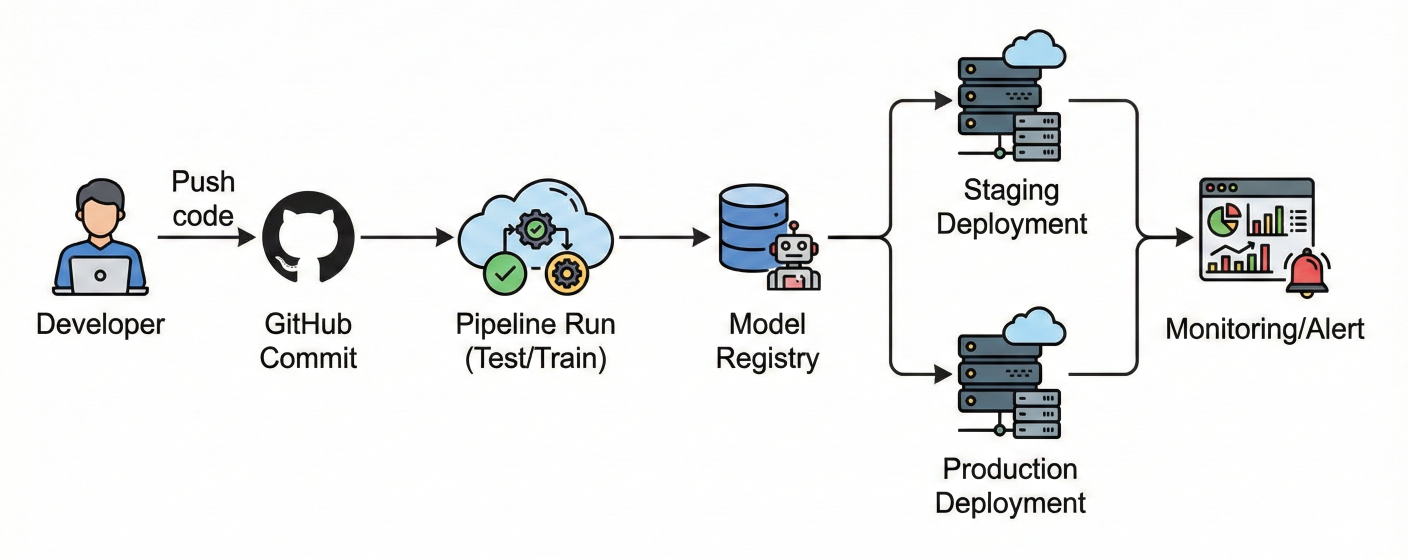
CI/CD pipeline diagram: GitHub commit → Pipeline run (test/train) → Model registry → Staging/production deployment → Monitoring/alert
ZenML empowers you to:
ZenML isn’t just a tool—it's an MLOps superpower. It eliminates pipeline spaghetti, builds bulletproof reproducibility, supercharges your collaboration, and sets you (and your team) up for ML deployment success. Whether you’re already scaling AI models in production, or just want to bring order to your ML chaos, ZenML is the toolkit designed for teams who want to do MLOps right.
Download ZenML, initialize your first pipeline, plug in your favorite tools, and experience what growing, scalable ML pipelines should feel like!

{{AUTHOR}}
 Launch your Graphy
Launch your Graphy