There are no items in your cart
Add More
Add More
| Item Details | Price | ||
|---|---|---|---|

Amazon Bedrock stands as the cornerstone of AWS's generative AI strategy, revolutionizing how organizations build, deploy, and scale intelligent applications. As enterprises increasingly recognize the transformative potential of generative AI, the need for a robust, secure, and accessible platform has never been more critical. AWS Bedrock emerges as the solution that bridges the gap between cutting-edge AI capabilities and enterprise-grade implementation.
This comprehensive guide explores every facet of AWS Bedrock, from its fundamental architecture to advanced implementation strategies, providing intermediate cloud and AI practitioners with the knowledge needed to harness its full potential.
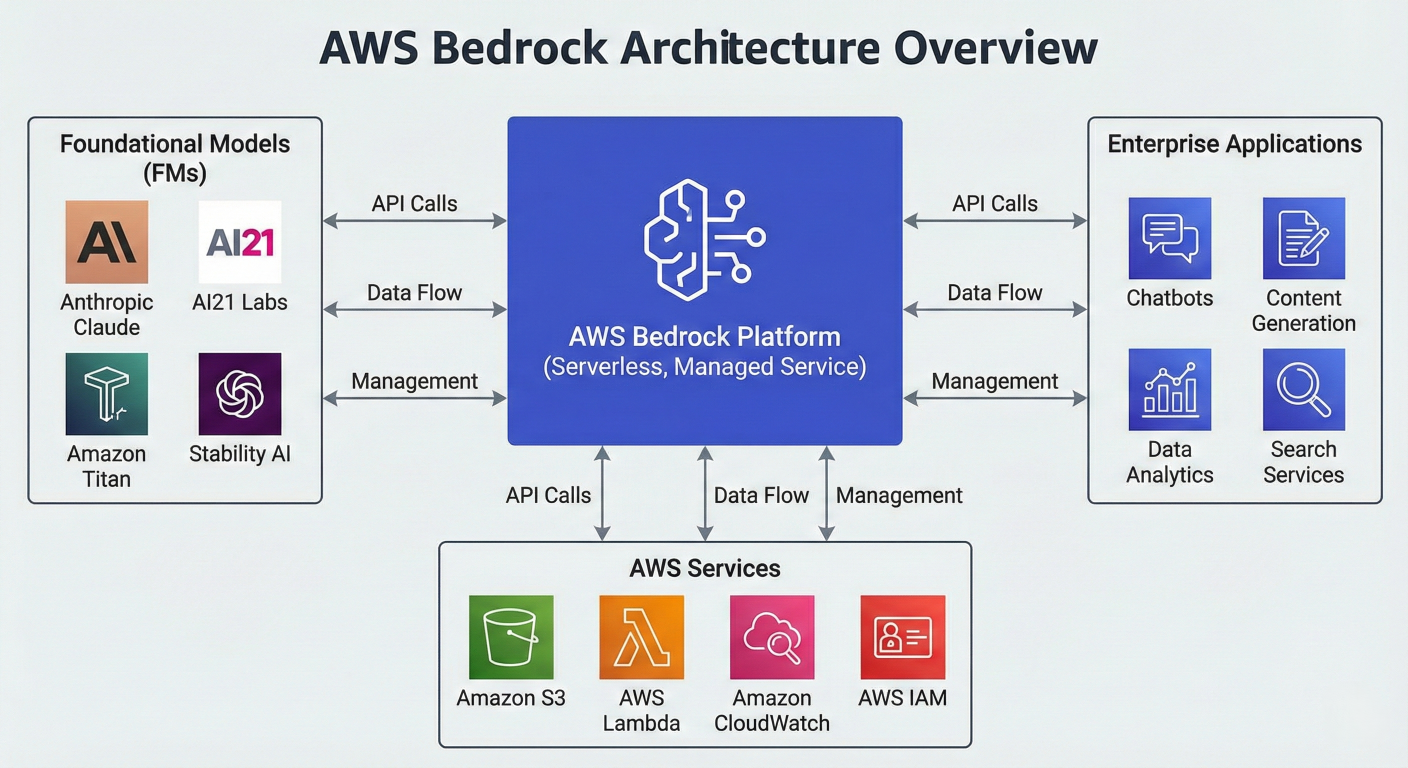
AWS Bedrock Architecture Overview Diagram showing central platform connecting multiple foundational models, AWS services, and enterprise applications
Amazon Bedrock is a fully managed service that provides access to high-performing foundation models (FMs) from leading AI companies through a unified API. Rather than building and maintaining complex AI infrastructure, organizations can leverage pre-trained models for tasks including text generation, image creation, conversational AI, and document analysis.
The service operates as a middleware layer between applications and foundation models, handling infrastructure scaling, security, and model management automatically. When applications send requests like "Generate a marketing email" or "Analyze this document," Bedrock routes them to the selected model and returns generated results seamlessly.
Simplicity and Accessibility: Bedrock eliminates the complexity traditionally associated with AI model deployment. Organizations no longer need specialized AI infrastructure teams or deep machine learning expertise to integrate sophisticated generative AI capabilities.
Model Choice and Flexibility: The platform provides access to multiple foundation models from different providers, allowing teams to experiment, compare, and switch between models based on performance requirements and use cases.
Enterprise-Grade Security: Built on AWS's security foundation, Bedrock ensures data remains private with encryption in transit and at rest, while maintaining compliance with industry standards including SOC, GDPR, FedRAMP High, and HIPAA eligibility.
Seamless Integration: Native integration with existing AWS services creates powerful end-toend solutions without requiring extensive custom development.
Cost Optimization: Pay-per-use pricing models eliminate upfront infrastructure investments, while provisioned throughput options provide predictable costs for production workloads.
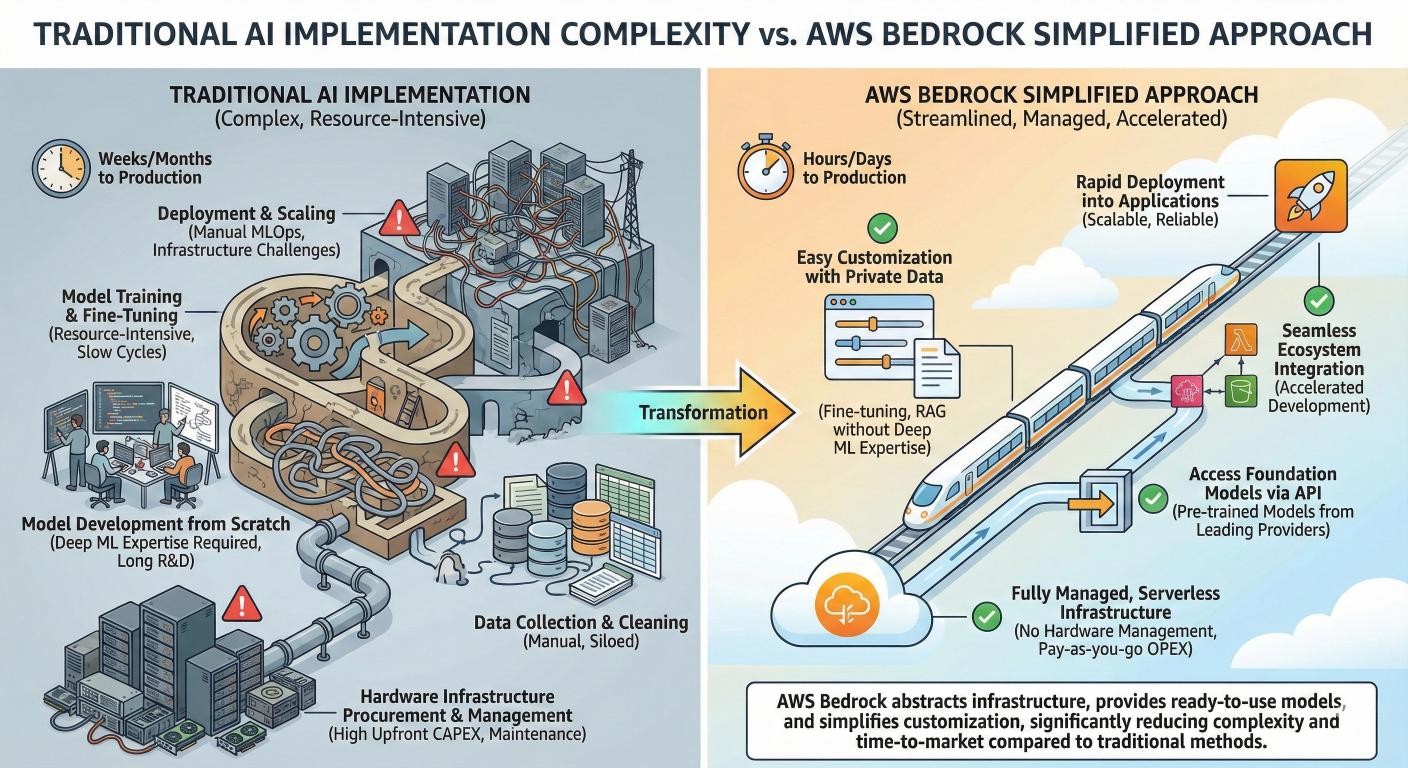
Comparison diagram showing traditional AI implementation complexity vs. AWS Bedrock simplified approach
AWS Bedrock supports an extensive ecosystem of foundation models from leading AI providers, creating a competitive marketplace that benefits users through innovation and choice.
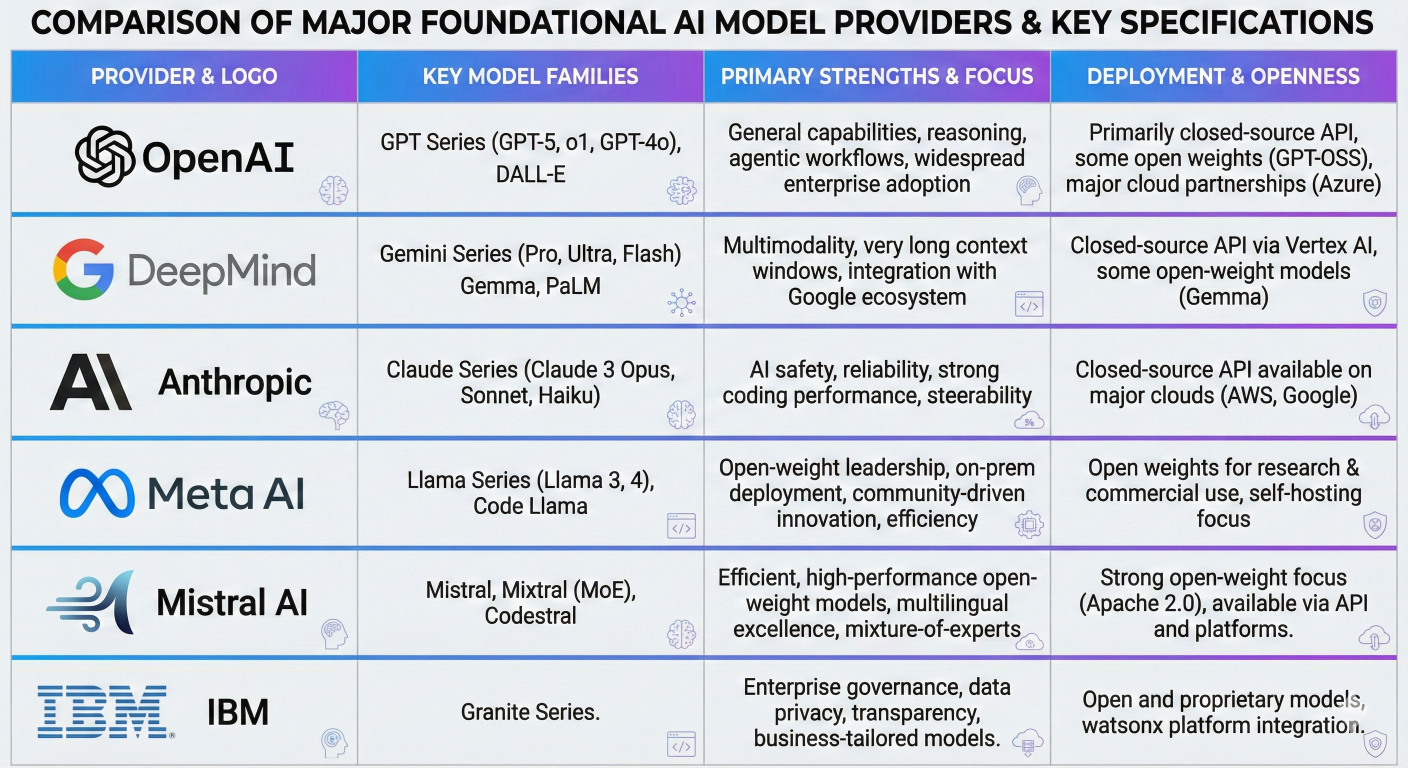
Visual grid showing logos and key specifications of all supported foundational model providers
Before using any foundation model, organizations must request access through the AWS console:
1. Navigate to Model Access: In the Bedrock console, access the "Model Access" section
2. Select Required Models: Choose specific models needed for your use case
3. Submit Access Request: Provide justification and intended use cases
4. Approval Process: AWS reviews requests, typically approving within 24-48 hours
5. Enable Models: Once approved, models become available for inference
The model switching process is designed for flexibility and experimentation:
# Example: Switching between different models
import boto3
import json
bedrock_runtime = boto3.client('bedrock-runtime', region_name='us-east-1')
# Using Claude 3 Sonnet
claude_response = bedrock_runtime.invoke_model(
modelId='anthropic.claude-3-sonnet-20240229-v1:0',
body=json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 1000,
"messages": [{"role": "user", "content": "Explain quantum computing"}]
})
)
# Switching to Titan Text
titan_response = bedrock_runtime.invoke_model(
modelId='amazon.titan-text-express-v1',
body=json.dumps({
"inputText": "Explain quantum computing",
"textGenerationConfig": {
"maxTokenCount": 1000,
"temperature": 0.7
}
})
)
Each model uses a unique identifier following the pattern provider.model-name-version:
This systematic approach ensures version control and backward compatibility while allowing seamless upgrades to newer model versions.
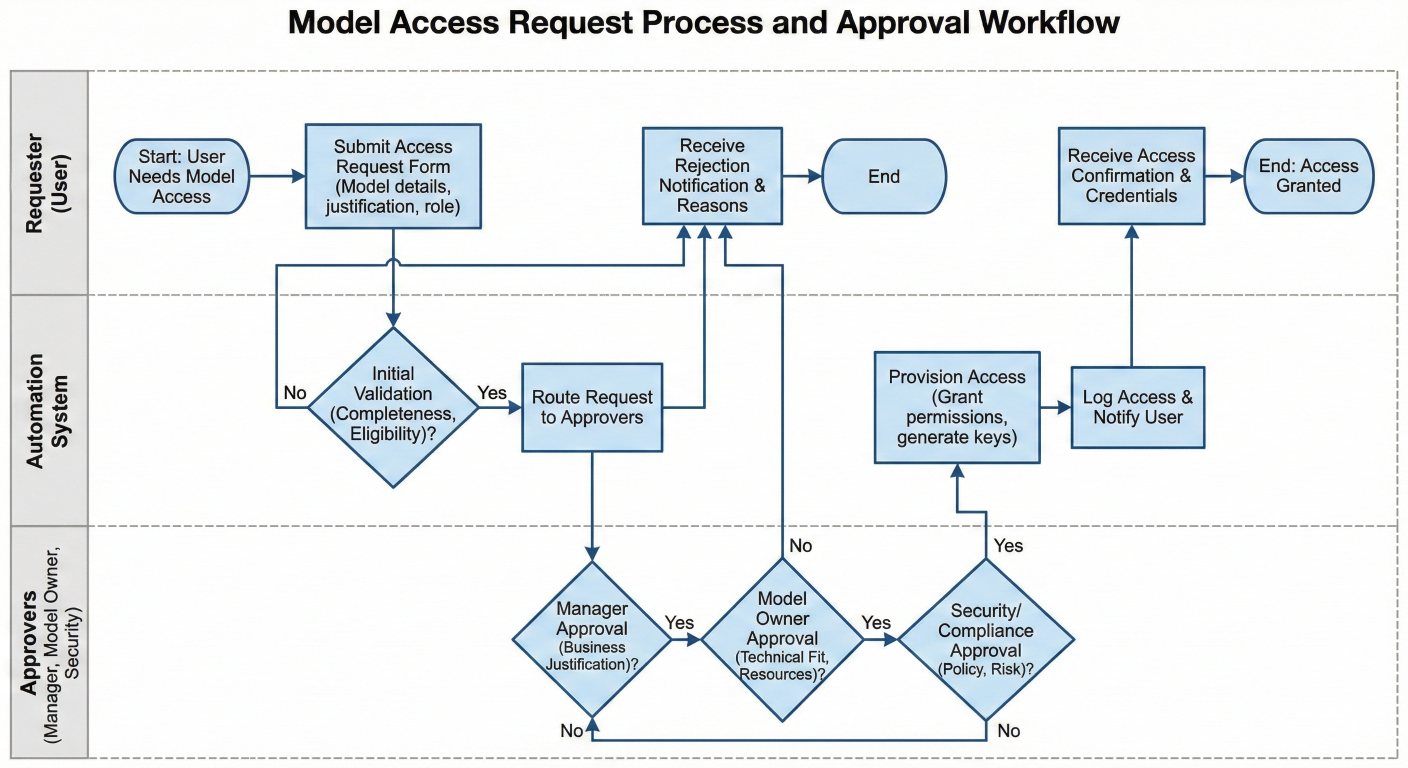
Flowchart showing the model access request process and approval workflow
Retrieval Augmented Generation represents a paradigm shift in how AI systems access and utilize information. Rather than relying solely on training data, RAG enables models to dynamically retrieve relevant information from external knowledge sources.
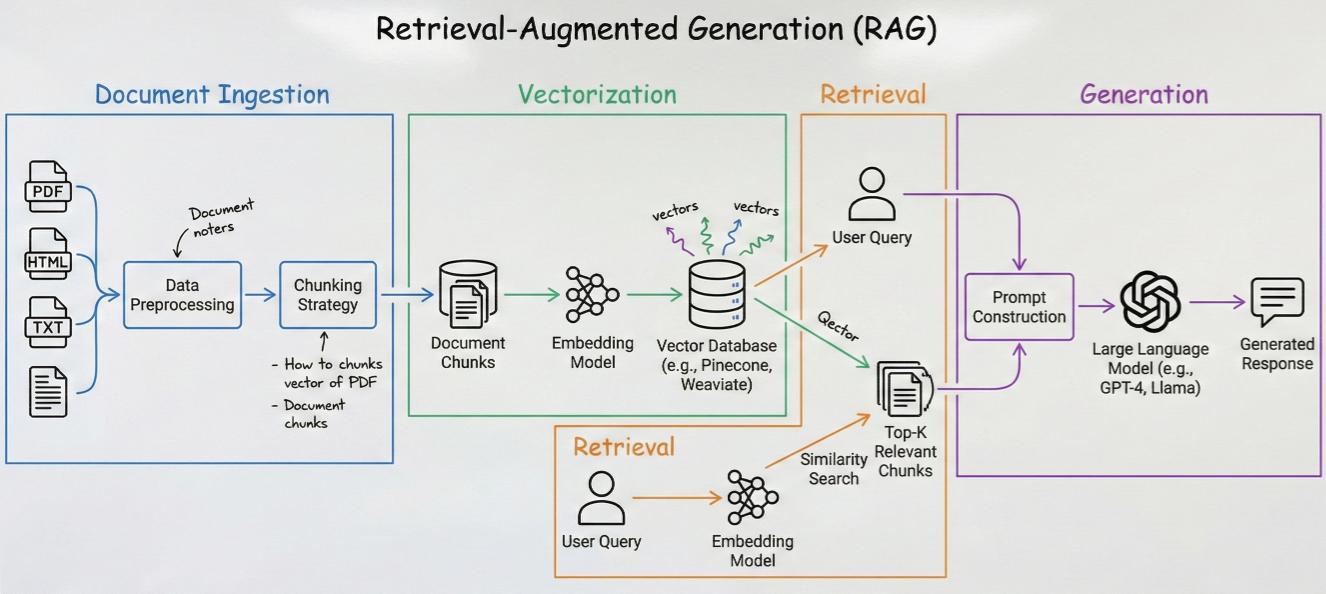
Detailed RAG workflow diagram showing document ingestion, vectorization, retrieval, and generation phases
Amazon Bedrock Knowledge Bases provides a fully managed RAG solution that automates the entire pipeline from data ingestion to response generation. The system handles:
# Supported embedding models and their specifications
embedding_models = {
'amazon.titan-embed-text-v1': {
'dimensions': 1536,
'vector_type': 'floating-point',
'max_input_tokens': 8192
},
'amazon.titan-embed-text-v2': {
'dimensions': [256, 512, 1024],
'vector_type': ['floating-point', 'binary'],
'languages': 'multilingual'
},
'cohere.embed-english-v3': {
'dimensions': 1024,
'vector_type': ['floating-point', 'binary'],
'specialty': 'english-optimized'
},
'cohere.embed-multilingual-v3': {
'dimensions': 1024,
'vector_type': ['floating-point', 'binary'],
'specialty': 'multilingual-support'
}
}
import boto3
import json
# Initialize Bedrock clients
bedrock_agent_runtime = boto3.client('bedrock-agent-runtime')
bedrock_runtime = boto3.client('bedrock-runtime')
def create_knowledge_base_rag(query, knowledge_base_id):
"""
Implement RAG using Bedrock Knowledge Base
"""
try:
# Retrieve relevant documents
retrieval_response = bedrock_agent_runtime.retrieve(
knowledgeBaseId=knowledge_base_id,
retrievalQuery={'text': query},
retrievalConfiguration={
'vectorSearchConfiguration': {
'numberOfResults': 5,
'overrideSearchType': 'HYBRID'
}
}
)
# Extract retrieved context
context_docs = []
for result in retrieval_response['retrievalResults']:
context_docs.append({
'content': result['content']['text'],
'source': result['location']['s3Location']['uri'],
'score': result['score']
})
# Combine context for prompt augmentation
context_text = "\n\n".join([doc['content'] for doc in context_docs])
# Create augmented prompt
augmented_prompt = f"""
Context Information:
{context_text}
Based on the above context, please answer the following question:
{query}
If the context doesn't contain relevant information, please state that clearly.
"""
# Generate response using foundation model
response = bedrock_runtime.invoke_model(
modelId='anthropic.claude-3-sonnet-20240229-v1:0',
body=json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 1000,
"messages": [{
"role": "user",
"content": augmented_prompt
}]
})
)
# Parse and return response with citations
response_body = json.loads(response['body'].read())
generated_text = response_body['content'][0]['text']
return {
'answer': generated_text,
'sources': [doc['source'] for doc in context_docs],
'retrieval_scores': [doc['score'] for doc in context_docs]
}
except Exception as e:
print(f"RAG implementation error: {e}")
return None
# Example usage
query = "What are the key benefits of cloud migration?"
knowledge_base_id = "ABCDEFGH12" # Your knowledge base ID
result = create_knowledge_base_rag(query, knowledge_base_id)
import boto3
import json
def advanced_rag_with_citations(query, knowledge_base_id, model_id="anthropic.claude-3-sonnet-20240229-v1:0"):
"""
Advanced RAG implementation with automatic citation and response generation
"""
try:
response = bedrock_agent_runtime.retrieve_and_generate(
input={'text': query},
retrieveAndGenerateConfiguration={
'type': 'KNOWLEDGE_BASE',
'knowledgeBaseConfiguration': {
'knowledgeBaseId': knowledge_base_id,
'modelArn': f'arn:aws:bedrock:us-east-1::foundation-model/{model_id}',
'retrievalConfiguration': {
'vectorSearchConfiguration': {
'numberOfResults': 10,
'overrideSearchType': 'HYBRID'
}
},
'generationConfiguration': {
'promptTemplate': {
'textPromptTemplate': '''
You are a helpful AI assistant. Use the following context to answer the user's question.
Always cite your sources using the format [Source: filename].
Context:
$search_results$
Question: $query$
Answer:'''
}
}
}
}
)
return {
'answer': response['output']['text'],
'citations': response['citations'],
'session_id': response.get('sessionId')
}
except Exception as e:
print(f"Advanced RAG error: {e}")
return None
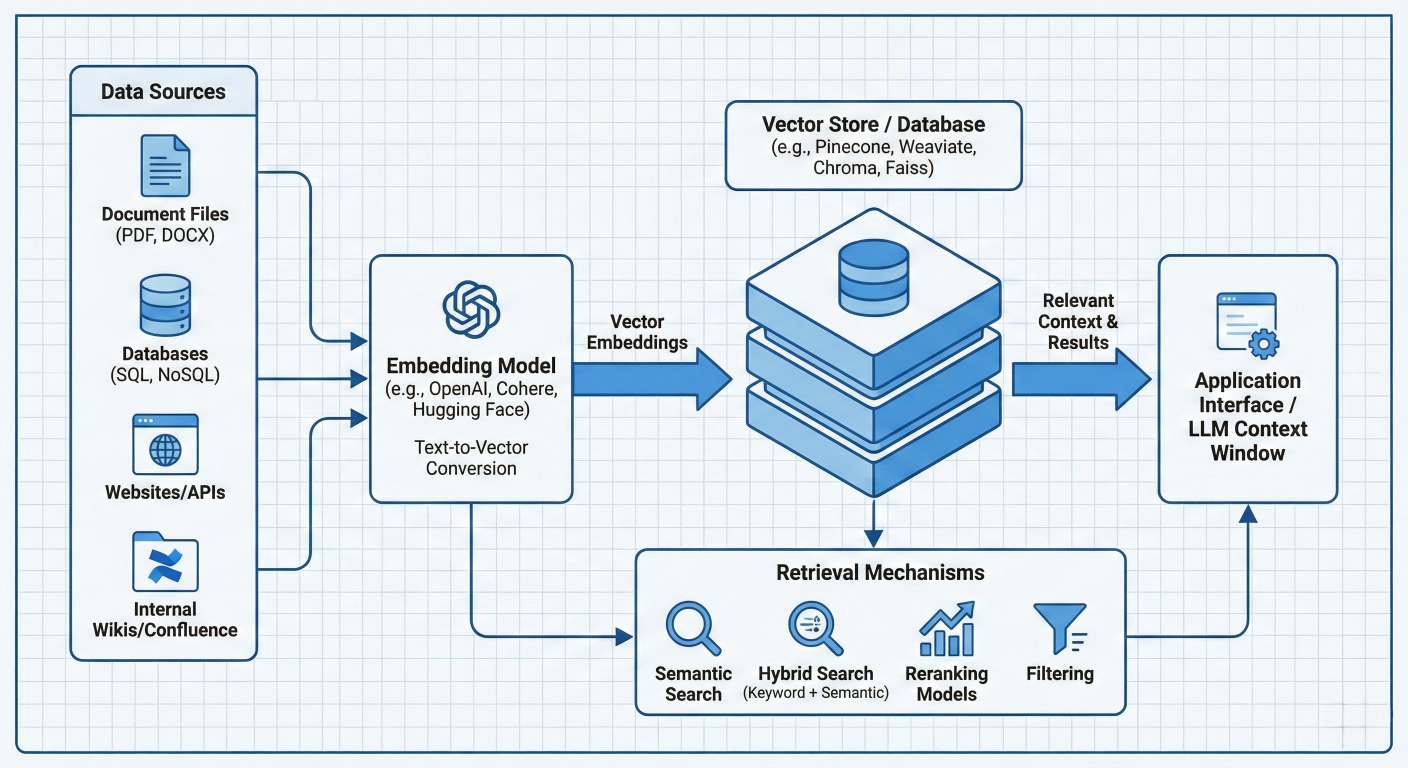
Architecture diagram showing Knowledge Base components including data sources, vector stores, embedding models, and retrieval mechanisms
Beyond unstructured documents, Bedrock Knowledge Bases supports structured data sources through Natural Language to SQL capabilities:
def structured_data_rag(query, knowledge_base_id):
"""
RAG implementation for structured data sources using NL2SQL
"""
try:
# Query structured data source
response = bedrock_agent_runtime.retrieve_and_generate(
input={'text': query},
retrieveAndGenerateConfiguration={
'type': 'KNOWLEDGE_BASE',
'knowledgeBaseConfiguration': {
'knowledgeBaseId': knowledge_base_id,
'modelArn': 'arn:aws:bedrock:us-east-1::foundation-model/anthropic.claude-3-sonnet-20240229-v1:0',
'retrievalConfiguration': {
'vectorSearchConfiguration': {
'numberOfResults': 5
}
}
}
}
)
return response['output']['text']
except Exception as e:
return f"Structured data RAG error: {e}"
# Example: Querying transactional data
query = "What were the top-selling products in Q3 2024?"
result = structured_data_rag(query, "structured-kb-id")
Amazon Bedrock Agents represent sophisticated AI systems capable of reasoning through complex, multi-step workflows while orchestrating interactions with various tools and data sources. Unlike simple chatbots, agents can plan tasks, make decisions, invoke functions, and adapt their approach based on intermediate results.
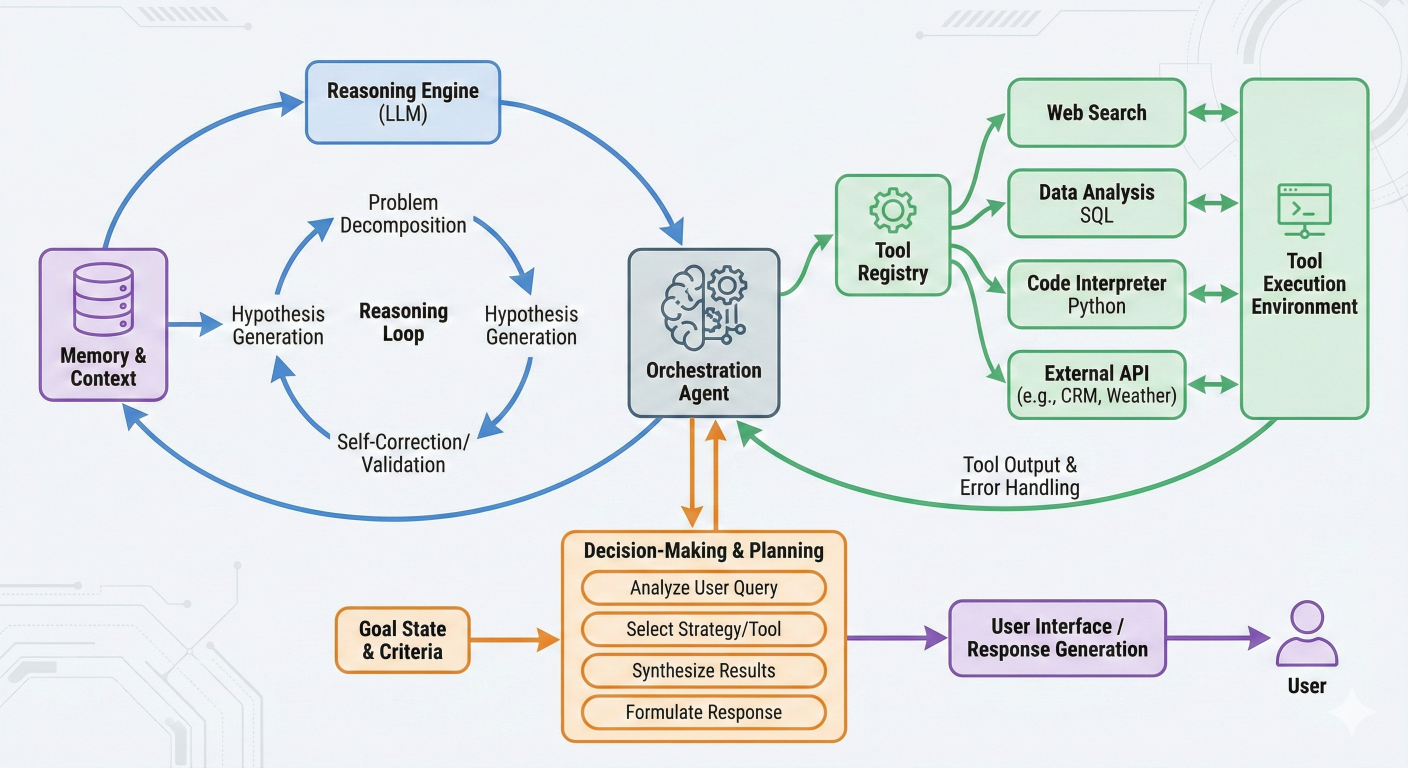
Comprehensive agent orchestration diagram showing reasoning loops, tool interactions, and decision-making processes
The default orchestration strategy follows a reasoning-action-observation loop:
1. Reasoning: Agent analyzes the current situation and decides next steps
2. Acting: Agent invokes appropriate tools or provides responses
3. Observation: Agent processes results and determines if task completion is achieved
For advanced use cases requiring specific workflow logic:
import json
import boto3
def custom_orchestrator_lambda(event, context):
"""
Custom orchestration logic for Bedrock Agents
"""
agent_id = event.get('agent', {}).get('agentId')
session_id = event.get('sessionId')
action_event = event.get('actionEvent')
# Custom orchestration logic based on state
if action_event == 'START':
# Initialize workflow
instructions = {
'action': 'INVOKE_MODEL',
'modelInvocationInput': {
'text': 'Analyze the user request and determine the required actions.'
}
}
elif action_event == 'TOOL_RESULT':
# Process tool results and determine next steps
tool_results = event.get('toolResults', [])
# Implement custom decision logic
if all_tasks_complete(tool_results):
instructions = {
'action': 'FINISH',
'finalResponse': {
'text': format_final_response(tool_results)
}
}
else:
instructions = {
'action': 'INVOKE_TOOL',
'toolInvocationInput': determine_next_tool(tool_results)
}
return {
'messageVersion': event['messageVersion'],
'response': {
'sessionState': update_session_state(event),
'orchestrationPlan': instructions
}
}
def all_tasks_complete(tool_results):
"""Check if all required tasks have been completed"""
required_tasks = ['data_retrieval', 'analysis', 'report_generation']
completed_tasks = [result['taskType'] for result in tool_results]
return all(task in completed_tasks for task in required_tasks)
def determine_next_tool(tool_results):
"""Determine the next tool to invoke based on current results"""
# Implementation depends on specific use case
pass
Action Groups serve as the primary mechanism for agents to interact with external systems and perform concrete actions:
import boto3
import json
def create_agent_action_group():
"""
Create an action group for Bedrock Agent
"""
bedrock_agent = boto3.client('bedrock-agent')
# OpenAPI schema defining available functions
api_schema = {
"openapi": "3.0.1",
"info": {
"title": "Customer Management API",
"version": "1.0.0"
},
"paths": {
"/customer/{customer_id}": {
"get": {
"summary": "Retrieve customer information",
"parameters": [{
"name": "customer_id",
"in": "path",
"required": True,
"schema": {"type": "string"}
}],
"responses": {
"200": {
"description": "Customer information retrieved successfully"
}
}
}
},
"/order": {
"post": {
"summary": "Create a new order",
"requestBody": {
"required": True,
"content": {
"application/json": {
"schema": {
"type": "object",
"properties": {
"customer_id": {"type": "string"},
"items": {"type": "array"},
"total_amount": {"type": "number"}
}
}
}
}
}
}
}
}
}
# Create action group
response = bedrock_agent.create_agent_action_group(
agentId='AGENT123456',
agentVersion='DRAFT',
actionGroupName='CustomerManagement',
description='Handles customer-related operations and order management',
actionGroupExecutor={
'lambda': 'arn:aws:lambda:us-east-1:123456789012:function:CustomerManagementFunction'
},
apiSchema={
'payload': json.dumps(api_schema)
},
actionGroupState='ENABLED'
)
return response['agentActionGroup']
# Lambda function handling action group invocations
def customer_management_lambda(event, context):
"""
Lambda function for customer management action group
"""
function_name = event['function']
parameters = {p['name']: p['value'] for p in event.get('parameters', [])}
if function_name == 'get_customer':
customer_id = parameters.get('customer_id')
customer_data = retrieve_customer_from_database(customer_id)
response_body = {
'TEXT': {
'body': json.dumps({
'customer': customer_data,
'status': 'success'
})
}
}
elif function_name == 'create_order':
order_details = create_order_in_system(parameters)
response_body = {
'TEXT': {
'body': json.dumps({
'order_id': order_details['id'],
'status': 'created',
'confirmation': order_details['confirmation_number']
})
}
}
return {
'messageVersion': event['messageVersion'],
'response': {
'actionGroup': event['actionGroup'],
'function': function_name,
'functionResponse': {
'responseBody': response_body
}
}
}
def retrieve_customer_from_database(customer_id):
"""Retrieve customer data from database"""
# Implementation would connect to actual database
return {
'id': customer_id,
'name': 'John Doe',
'email': 'john@example.com',
'status': 'active'
}
def create_order_in_system(order_details):
"""Create order in order management system"""
# Implementation would interact with order system
return {
'id': 'ORDER-12345',
'confirmation_number': 'CONF-67890'
}Multi-Agent Collaboration
For scenarios requiring external processing outside AWS Lambda:
def return_of_control_handler(event, context):
"""
Handle return of control action groups
"""
action_group = event['actionGroup']
function_name = event['function']
parameters = event.get('parameters', [])
# Return control to calling application
return {
'messageVersion': event['messageVersion'],
'response': {
'actionGroup': action_group,
'function': function_name,
'functionResponse': {
'responseState': 'REPROMPT',
'responseBody': {
'TEXT': {
'body': json.dumps({
'message': 'External processing required',
'action_needed': 'approve_transaction',
'parameters': parameters
})
}
}
}
}
}
Advanced scenarios may require multiple specialized agents working together:
def create_multi_agent_system():
"""
Create a system with multiple collaborating agents
"""
# Data Analysis Agent
data_agent_config = {
'agentName': 'DataAnalysisAgent',
'instruction': '''You are a data analysis specialist. Your role is to:
1. Process and analyze datasets
2. Generate statistical insights
3. Create data visualizations
4. Provide recommendations based on data findings''',
'foundationModel': 'anthropic.claude-3-sonnet-20240229-v1:0'
}
# Report Generation Agent
report_agent_config = {
'agentName': 'ReportGenerationAgent',
'instruction': '''You are a report generation specialist. Your role is to:
1. Compile analysis results into comprehensive reports
2. Format content for different audiences
3. Ensure consistency and clarity
4. Generate executive summaries''',
'foundationModel': 'anthropic.claude-3-sonnet-20240229-v1:0'
}
# Supervisor Agent orchestrating collaboration
supervisor_config = {
'agentName': 'SupervisorAgent',
'instruction': '''You coordinate multiple specialist agents to complete complex tasks.
Delegate work appropriately and synthesize results from different agents.''',
'foundationModel': 'anthropic.claude-3-opus-20240229-v1:0'
}
return [data_agent_config, report_agent_config, supervisor_config]
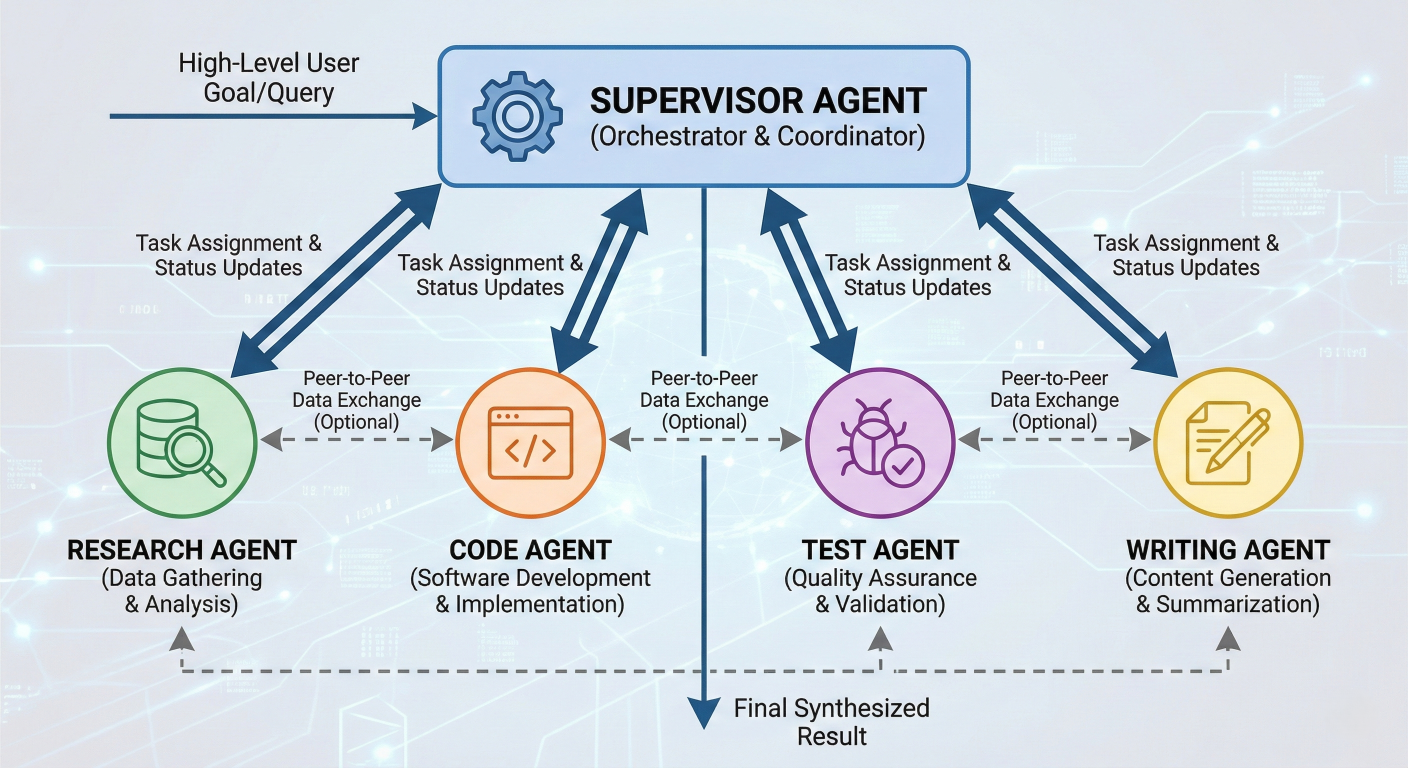
Multi-agent collaboration diagram showing different specialized agents working together under supervisor coordination
AWS Bedrock provides multiple approaches to customize foundation models for specific use cases and domains:
Fine-tuning: Adjusts model parameters using domain-specific training data to improve performance on particular tasks.
Continued Pre-training: Extends model training on domain-specific corpora to enhance knowledge in particular areas.
Prompt Engineering: Optimizes input prompts to improve model responses without modifying parameters.
Supported Models for Fine-tuning:
Fine-tuning Workflow:
# Conceptual AWS Bedrock fine-tuning example
import boto3
import json
def create_fine_tuning_job():
"""
Create a fine-tuning job for model customization
"""
bedrock_client = boto3.client('bedrock')
# Prepare training data format
training_data_format = {
"prompt": "Analyze the following customer feedback:",
"completion": "Based on the feedback analysis, the customer sentiment is positive with specific appreciation for product quality and customer service responsiveness."
}
# Create custom model job
response = bedrock_client.create_model_customization_job(
jobName='CustomerSentimentAnalysis-v1',
customModelName='CustomSentimentAnalyzer',
roleArn='arn:aws:iam::123456789012:role/BedrockCustomizationRole',
baseModelIdentifier='amazon.titan-text-express-v1',
trainingDataConfig={
's3Uri': 's3://my-training-bucket/sentiment-training-data.jsonl'
},
validationDataConfig={
's3Uri': 's3://my-training-bucket/sentiment-validation-data.jsonl'
},
outputDataConfig={
's3Uri': 's3://my-output-bucket/custom-model-artifacts/'
},
hyperParameters={
'epochCount': '3',
'batchSize': '4',
'learningRate': '0.00001'
}
)
return response['jobArn']
# Monitor fine-tuning progress
def monitor_customization_job(job_arn):
"""
Monitor the progress of model customization
"""
bedrock_client = boto3.client('bedrock')
response = bedrock_client.get_model_customization_job(
jobIdentifier=job_arn
)
job_status = response['status']
training_metrics = response.get('trainingMetrics', {})
validation_metrics = response.get('validationMetrics', {})
return {
'status': job_status,
'training_loss': training_metrics.get('trainingLoss'),
'validation_loss': validation_metrics.get('validationLoss')
}
Training Data Preparation:
def prepare_training_data():
"""
Prepare training data in the required JSONL format
"""
training_examples = [
{
"prompt": "Classify the sentiment of this review: The product exceeded my expectations with excellent build quality.",
"completion": "Positive sentiment - The customer expresses satisfaction and appreciation for product quality."
},
{
"prompt": "Classify the sentiment of this review: Delivery was delayed and customer service was unresponsive.",
"completion": "Negative sentiment - The customer experienced service issues and poor communication."
},
{
"prompt": "Analyze customer feedback: The interface is intuitive but loading times could be improved.",
"completion": "Mixed sentiment - Positive feedback on usability with constructive criticism on performance."
}
]
# Save as JSONL file
with open('training_data.jsonl', 'w') as f:
for example in training_examples:
f.write(json.dumps(example) + '\n')
return 'training_data.jsonl'
Provisioned Throughput ensures consistent performance and predictable costs for production workloads:
Throughput Options:
def configure_provisioned_throughput():
"""
Set up provisioned throughput for custom or base models
"""
bedrock_client = boto3.client('bedrock')
# For custom models (no commitment)
custom_model_throughput = bedrock_client.create_provisioned_model_throughput(
provisionedModelName='CustomerAnalyzer-Provisioned',
modelArn='arn:aws:bedrock:us-east-1:123456789012:custom-model/CustomerSentimentAnalyzer.12345',
modelUnits=2,
clientRequestToken='unique-request-token-123'
)
# For base models (with commitment)
base_model_throughput = bedrock_client.create_provisioned_model_throughput(
provisionedModelName='Claude-Production-Provisioned',
modelArn='arn:aws:bedrock:us-east-1::foundation-model/anthropic.claude-3-sonnet-20240229-v1:0',
modelUnits=10,
commitmentDuration='OneMonth',
clientRequestToken='unique-request-token-456'
)
return {
'custom_model_arn': custom_model_throughput['provisionedModelArn'],
'base_model_arn': base_model_throughput['provisionedModelArn']
}
# Using provisioned throughput
def invoke_provisioned_model(provisioned_model_arn, prompt):
"""
Invoke model using provisioned throughput
"""
bedrock_runtime = boto3.client('bedrock-runtime')
response = bedrock_runtime.invoke_model(
modelId=provisioned_model_arn,
body=json.dumps({
"inputText": prompt,
"textGenerationConfig": {
"maxTokenCount": 500,
"temperature": 0.7
}
})
)
result = json.loads(response['body'].read())
return result[0]['outputText']
def calculate_model_units_needed(expected_requests_per_minute, avg_tokens_per_request):
"""
Calculate required model units based on usage patterns
"""
# Example calculation for Titan Text model
# 1 Model Unit = 2000 input tokens/min + 800 output tokens/min
input_tokens_per_minute = expected_requests_per_minute * avg_tokens_per_request['input']
output_tokens_per_minute = expected_requests_per_minute * avg_tokens_per_request['output']
input_units_needed = input_tokens_per_minute / 2000
output_units_needed = output_tokens_per_minute / 800
# Take the maximum as the limiting factor
required_units = max(input_units_needed, output_units_needed)
# Add 20% buffer for peak loads
recommended_units = int(required_units * 1.2) + 1
return {
'calculated_units': required_units,
'recommended_units': recommended_units,
'monthly_cost_estimate': recommended_units * 468 # Example pricing
}
# Usage example
usage_pattern = {
'input': 150, # Average input tokens per request
'output': 300 # Average output tokens per request
}
units_calculation = calculate_model_units_needed(100, usage_pattern)
print(f"Recommended model units: {units_calculation['recommended_units']}") 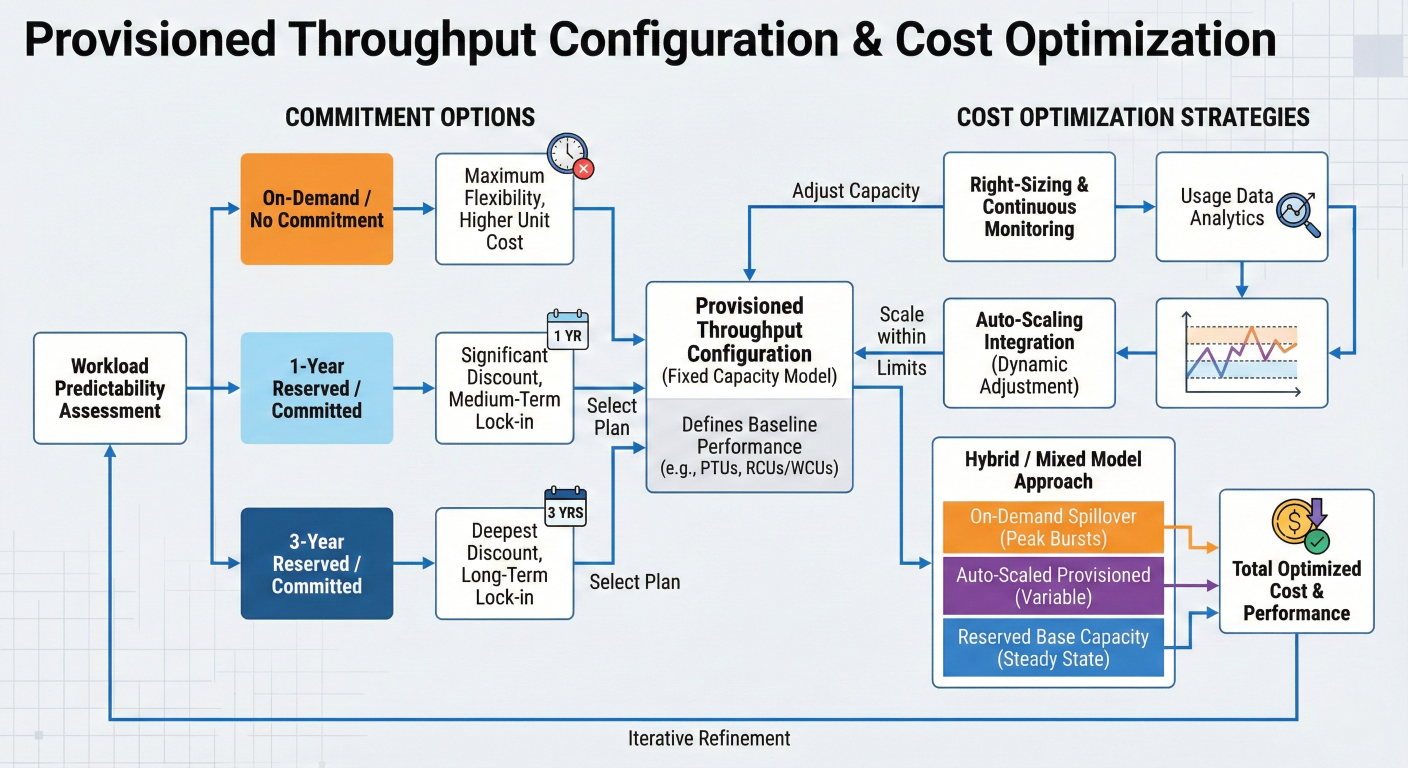
Provisioned throughput configuration diagram showing different commitment options and cost optimization strategies
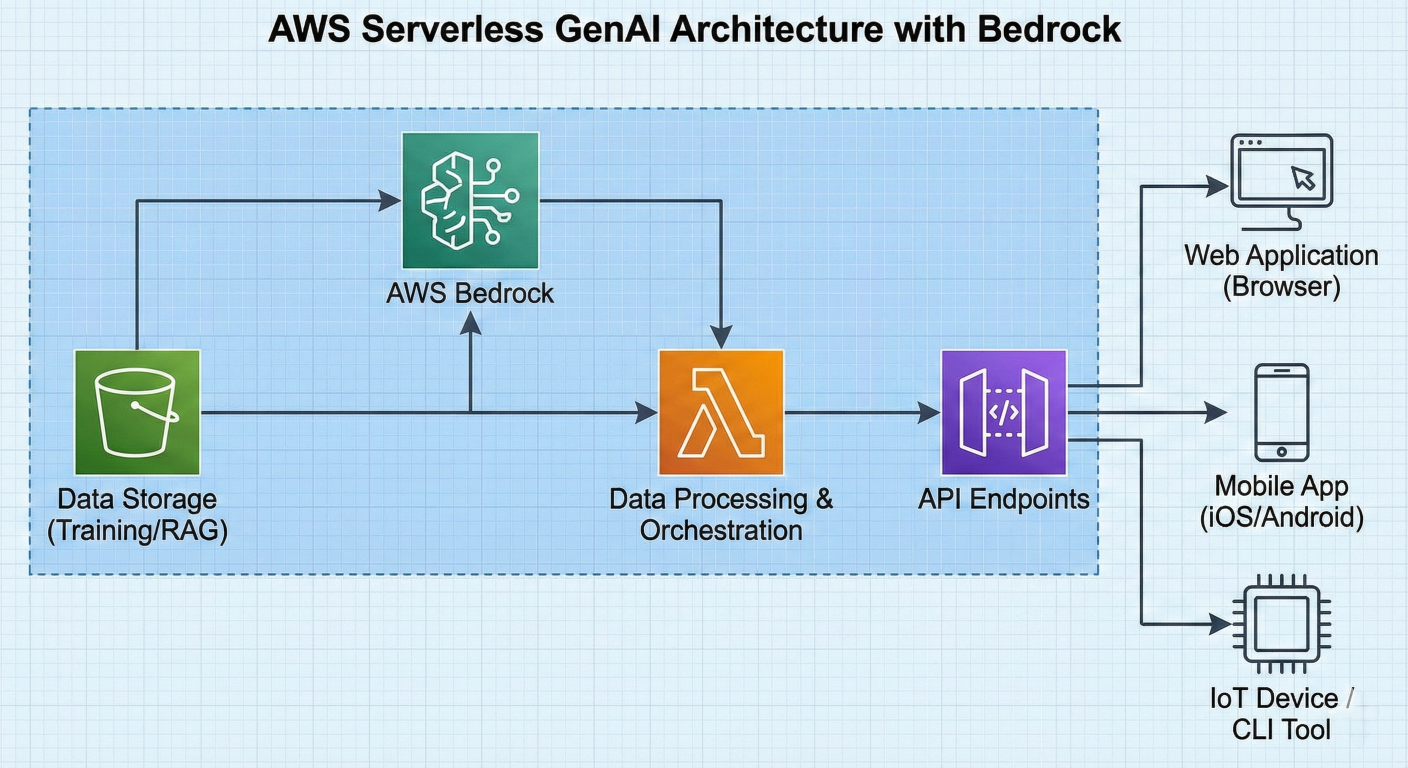
Comprehensive architecture diagram showing AWS Bedrock at the center, connected to S3 for data storage, Lambda for processing, API Gateway for endpoints, and various clients
A comprehensive Bedrock-based architecture typically involves multiple AWS services working together to create robust, scalable generative AI applications:
Core Architecture Components:
1. API Gateway: Serves as the entry point for client applications
2. AWS Lambda: Handles business logic and orchestration 3. Amazon Bedrock: Provides AI model inference capabilities
4. Amazon S3: Stores documents, training data, and application assets
5. Amazon CloudWatch: Monitors performance and provides logging
6. IAM Roles: Manages security and access control
import boto3
import json
from botocore.exceptions import ClientError
class BedrockRAGApplication:
"""
Complete RAG application integrating multiple AWS services
"""
def __init__(self):
self.bedrock_runtime = boto3.client('bedrock-runtime')
self.bedrock_agent_runtime = boto3.client('bedrock-agent-runtime')
self.s3_client = boto3.client('s3')
def lambda_handler(self, event, context):
"""
Main Lambda handler for API Gateway requests
"""
try:
# Parse request
http_method = event['httpMethod']
path = event['path']
body = json.loads(event.get('body', '{}'))
if path == '/query' and http_method == 'POST':
return self.handle_query_request(body)
elif path == '/upload' and http_method == 'POST':
return self.handle_document_upload(body)
else:
return self.create_response(404, {'error': 'Not found'})
except Exception as e:
return self.create_response(500, {'error': str(e)})
def handle_query_request(self, request_body):
"""
Process user queries using RAG
"""
query = request_body.get('query')
knowledge_base_id = request_body.get('knowledge_base_id')
if not query or not knowledge_base_id:
return self.create_response(400, {'error': 'Missing required parameters'})
# Implement RAG workflow
rag_result = self.execute_rag_pipeline(query, knowledge_base_id)
# Log interaction for monitoring
self.log_interaction(query, rag_result)
return self.create_response(200, {
'answer': rag_result['answer'],
'sources': rag_result['sources'],
'confidence_score': rag_result.get('confidence', 0.0)
})
def execute_rag_pipeline(self, query, knowledge_base_id):
"""
Execute complete RAG pipeline
"""
try:
# Step 1: Retrieve relevant documents
retrieval_response = self.bedrock_agent_runtime.retrieve(
knowledgeBaseId=knowledge_base_id,
retrievalQuery={'text': query},
retrievalConfiguration={
'vectorSearchConfiguration': {
'numberOfResults': 5,
'overrideSearchType': 'HYBRID'
}
}
)
# Step 2: Process retrieved results
context_documents = []
for result in retrieval_response['retrievalResults']:
context_documents.append({
'content': result['content']['text'],
'source': result['location']['s3Location']['uri'],
'confidence': result['score']
})
# Step 3: Generate response using context
response = self.generate_contextual_response(query, context_documents)
return {
'answer': response,
'sources': [doc['source'] for doc in context_documents],
'confidence': sum(doc['confidence'] for doc in context_documents) / len(context_documents)
}
except ClientError as e:
raise Exception(f"RAG pipeline error: {e}")
def generate_contextual_response(self, query, context_docs):
"""
Generate response using retrieved context
"""
context_text = "\n\n".join([f"Source: {doc['source']}\nContent: {doc['content']}"
for doc in context_docs])
prompt = f"""
You are an AI assistant that provides accurate answers based on the provided context.
Context Information:
{context_text}
User Question: {query}
Instructions:
1. Answer the question based solely on the provided context
2. If the context doesn't contain sufficient information, state this clearly
3. Include source references in your response
4. Be concise but comprehensive
Answer:
"""
# Invoke Bedrock model
response = self.bedrock_runtime.invoke_model(
modelId='anthropic.claude-3-sonnet-20240229-v1:0',
body=json.dumps({
'anthropic_version': 'bedrock-2023-05-31',
'max_tokens': 1000,
'temperature': 0.2,
'messages': [{
'role': 'user',
'content': prompt
}]
})
)
# Parse response
response_body = json.loads(response['body'].read())
return response_body[0]['text']
# Handle document uploads
def handle_document_upload(self, request_body):
"""
Handle document uploads to S3 and trigger knowledge base sync
"""
try:
document_content = request_body.get('content')
file_name = request_body.get('filename')
bucket_name = request_body.get('bucket')
# Upload to S3
self.s3_client.put_object(
Bucket=bucket_name,
Key=f"documents/{file_name}",
Body=document_content,
ContentType='application/pdf'
)
# Trigger knowledge base synchronization
return self.create_response(200, {
'message': 'Document uploaded successfully',
's3_location': f's3://{bucket_name}/documents/{file_name}'
})
except Exception as e:
return self.create_response(500, {'error': f'Upload failed: {e}'})
# Log interactions for monitoring
def log_interaction(self, query, result):
"""
Log interactions for monitoring and analytics
"""
import logging
logger = logging.getLogger()
logger.setLevel(logging.INFO)
log_entry = {
'timestamp': context.aws_request_id if 'context' in globals() else 'unknown',
'query': query,
'sources_count': len(result.get('sources', [])),
'confidence': result.get('confidence', 0.0)
}
logger.info(json.dumps(log_entry))
# Create standardized API Gateway response
def create_response(self, status_code, body):
"""
Create standardized API Gateway response
"""
return {
'statusCode': status_code,
'headers': {
'Content-Type': 'application/json',
'Access-Control-Allow-Origin': '*',
'Access-Control-Allow-Methods': 'GET, POST, PUT, DELETE',
'Access-Control-Allow-Headers': 'Content-Type, Authorization'
},
'body': json.dumps(body)
}
# Deployment configuration
def create_infrastructure():
"""
Infrastructure as Code for Bedrock RAG application
"""
cloudformation_template = {
"AWSTemplateFormatVersion": "2010-09-09",
"Resources": {
"BedrockExecutionRole": {
"Type": "AWS::IAM::Role",
"Properties": {
"AssumeRolePolicyDocument": {
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Principal": {"Service": "lambda.amazonaws.com"},
"Action": "sts:AssumeRole"
}]
},
"ManagedPolicyArns": [
"arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole"
],
"Policies": [{
"PolicyName": "BedrockAccess",
"PolicyDocument": {
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"bedrock:InvokeModel",
"bedrock:InvokeModelWithResponseStream"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"bedrock:Retrieve",
"bedrock:RetrieveAndGenerate"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject"
],
"Resource": "arn:aws:s3:::*/*"
}
]
}
}]
}
},
"RAGLambdaFunction": {
"Type": "AWS::Lambda::Function",
"Properties": {
"FunctionName": "BedrockRAGHandler",
"Runtime": "python3.9",
"Handler": "lambda_function.lambda_handler",
"Role": {"Fn::GetAtt": ["BedrockExecutionRole", "Arn"]},
"Code": {"ZipFile": "# Lambda function code would go here"},
"Timeout": 300,
"MemorySize": 1024
}
},
"APIGateway": {
"Type": "AWS::ApiGateway::RestApi",
"Properties": {
"Name": "BedrockRAGAPI",
"Description": "API for Bedrock RAG application"
}
}
}
}
return cloudformation_template
# Architecture for complex agent-based workflows
def create_agent_based_workflow():
"""
Architecture for complex agent-based workflows
"""
# Multi-step workflow using agents
workflow_config = {
"workflow_steps": [
{
"step": "document_analysis",
"agent": "DocumentAnalysisAgent",
"action_groups": ["document_parser", "content_extractor"],
"knowledge_bases": ["document_kb"]
},
{
"step": "data_processing",
"agent": "DataProcessingAgent",
"action_groups": ["data_validator", "transformation_engine"],
"dependencies": ["document_analysis"]
},
{
"step": "report_generation",
"agent": "ReportGenerationAgent",
"action_groups": ["template_engine", "formatting_tools"],
"dependencies": ["data_processing"]
}
]
}
return workflow_config
# Agent coordination Lambda
def agent_coordinator_lambda(event, context):
"""
Coordinate multiple agents for complex workflows
"""
workflow_id = event['workflow_id']
current_step = event['current_step']
# Determine next agent to invoke
next_agent = determine_next_agent(workflow_id, current_step)
if next_agent:
# Invoke next agent
bedrock_agent_runtime = boto3.client('bedrock-agent-runtime')
response = bedrock_agent_runtime.invoke_agent(
agentId=next_agent['agent_id'],
agentAliasId=next_agent['alias_id'],
sessionId=workflow_id,
inputText=event['input_data']
)
return process_agent_response(response, workflow_id)
else:
return finalize_workflow(workflow_id)
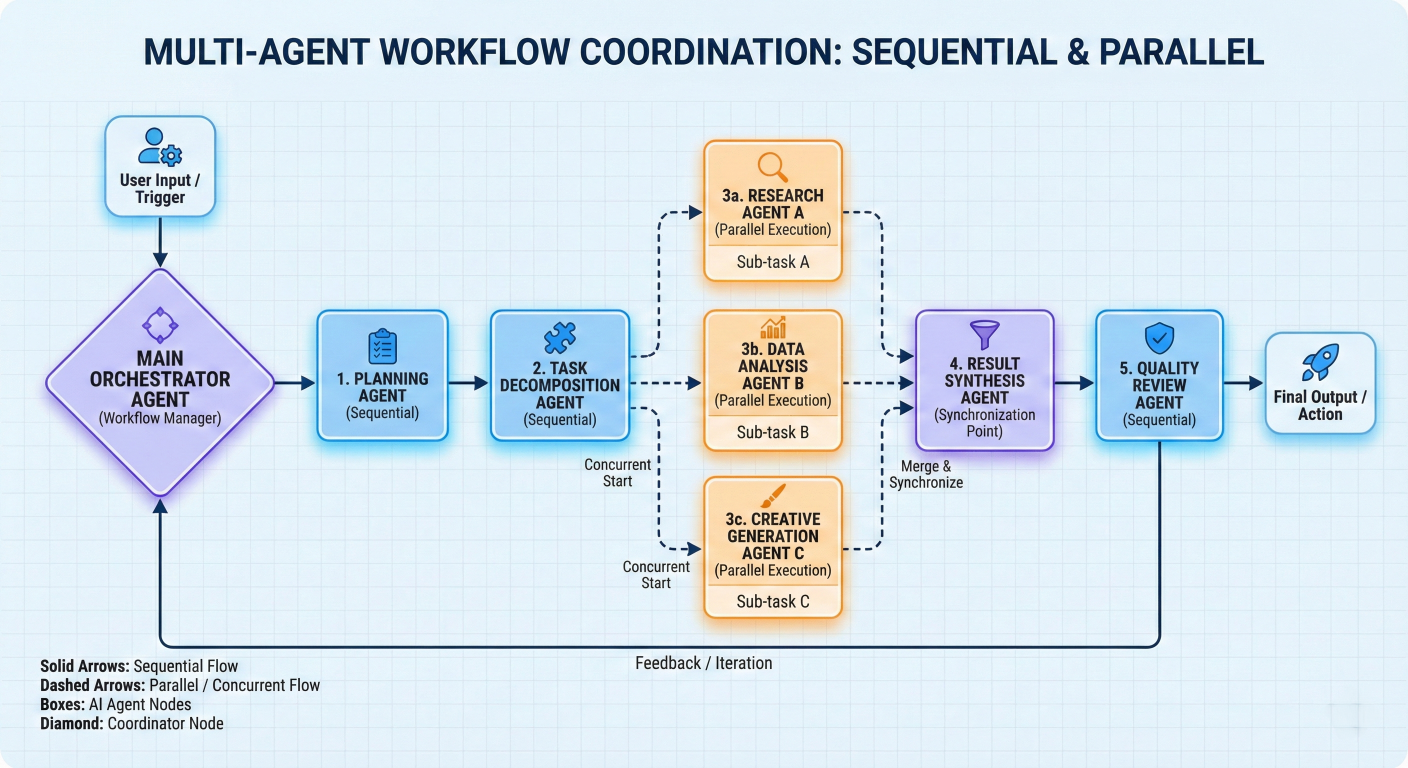
Agent workflow coordination diagram showing multiple agents working in sequence and parallel
# Comprehensive examples for invoking different Bedrock models import boto3 import json from botocore.exceptions import ClientError class BedrockModelInvoker: """ Comprehensive examples for invoking different Bedrock models """ def __init__(self, region_name='us-east-1'): self.bedrock_runtime = boto3.client('bedrock-runtime', region_name=region_name) def invoke_claude_model(self, prompt, model_version='sonnet'): """ Invoke Anthropic Claude models with proper formatting """ model_map = { 'haiku': 'anthropic.claude-3-haiku-20240307-v1:0', 'sonnet': 'anthropic.claude-3-sonnet-20240229-v1:0', 'opus': 'anthropic.claude-3-opus-20240229-v1:0' } model_id = model_map.get(model_version, model_map['sonnet']) request_body = { "anthropic_version": "bedrock-2023-05-31", "max_tokens": 1000, "temperature": 0.7, "messages": [ { "role": "user", "content": prompt } ] } try: response = self.bedrock_runtime.invoke_model( modelId=model_id, body=json.dumps(request_body) ) response_body = json.loads(response['body'].read()) return response_body['content'][0]['text'] except ClientError as e: return f"Error invoking Claude: {e}" def invoke_titan_model(self, prompt, max_tokens=512): """ Invoke Amazon Titan text models """ request_body = { "inputText": prompt, "textGenerationConfig": { "maxTokenCount": max_tokens, "temperature": 0.7, "topP": 0.9, "stopSequences": ["User:", "Assistant:"] } } try: response = self.bedrock_runtime.invoke_model( modelId='amazon.titan-text-express-v1', body=json.dumps(request_body) ) response_body = json.loads(response['body'].read()) return response_body['results'][0]['outputText'] except ClientError as e: return f"Error invoking Titan: {e}" # BedrockModelInvoker class with multiple model invocations def invoke_llama_model(self, prompt, system_prompt="You are a helpful assistant."): """ Invoke Meta Llama models with system prompts """ formatted_prompt = f"""<|begin_of_text|><|start_header_id|>system<|end_header_id|> {system_prompt}<|eot_id|><|start_header_id|>user<|end_header_id|> {prompt}<|eot_id|><|start_header_id|>assistant<|end_header_id|>""" request_body = { "prompt": formatted_prompt, "max_gen_len": 512, "temperature": 0.7, "top_p": 0.9 } try: response = self.bedrock_runtime.invoke_model( modelId='meta.llama3-70b-instruct-v1:0', body=json.dumps(request_body) ) response_body = json.loads(response['body'].read()) return response_body['generation'] except ClientError as e: return f"Error invoking Llama: {e}" def invoke_with_streaming(self, prompt, model_id='anthropic.claude-3-sonnet-20240229-v1:0'): """ Invoke model with streaming response for real-time output """ request_body = { "anthropic_version": "bedrock-2023-05-31", "max_tokens": 1000, "messages": [{"role": "user", "content": prompt}] } try: response = self.bedrock_runtime.invoke_model_with_response_stream( modelId=model_id, body=json.dumps(request_body) ) # Process streaming response full_response = "" for event in response['body']: chunk = json.loads(event['chunk']['bytes']) if 'delta' in chunk: if 'text' in chunk['delta']: full_response += chunk['delta']['text'] print(chunk['delta']['text'], end='', flush=True) return full_response except ClientError as e: return f"Streaming error: {e}" # Usage examples if __name__'__main__': invoker = BedrockModelInvoker() # Test different models prompt = "Explain the benefits of cloud computing in 3 paragraphs." print("Claude Response:") claude_response = invoker.invoke_claude_model(prompt) print(claude_response) print("\nTitan Response:") titan_response = invoker.invoke_titan_model(prompt) print(titan_response) print("\nLlama Response:") llama_response = invoker.invoke_llama_model(prompt) print(llama_response)
# Advanced RAG implementation with multiple knowledge bases and reranking
import boto3
import json
from typing import List, Dict, Any
class AdvancedRAGSystem:
"""
Advanced RAG implementation with multiple knowledge bases and reranking
"""
def __init__(self):
self.bedrock_agent_runtime = boto3.client('bedrock-agent-runtime')
self.bedrock_runtime = boto3.client('bedrock-runtime')
def multi_knowledge_base_rag(self, query: str, kb_configs: List[Dict]) -> Dict[str, Any]:
"""
Query multiple knowledge bases and combine results
"""
all_results = []
for kb_config in kb_configs:
kb_results = self.query_knowledge_base(
query,
kb_config['id'],
kb_config.get('max_results', 5)
)
# Add knowledge base metadata to results
for result in kb_results:
result['knowledge_base'] = kb_config['name']
result['domain'] = kb_config.get('domain', 'general')
all_results.extend(kb_results)
# Rerank combined results
reranked_results = self.rerank_results(query, all_results)
# Generate response using top results
response = self.generate_multi_source_response(query, reranked_results[:10])
return {
'answer': response,
'sources': [r['source'] for r in reranked_results[:5]],
'knowledge_bases_used': [kb['name'] for kb in kb_configs]
}
def query_knowledge_base(self, query: str, kb_id: str, max_results: int = 5) -> List[Dict]:
"""
Query individual knowledge base with advanced configuration
"""
try:
response = self.bedrock_agent_runtime.retrieve(
knowledgeBaseId=kb_id,
retrievalQuery={'text': query},
retrievalConfiguration={
'vectorSearchConfiguration': {
'numberOfResults': max_results,
'overrideSearchType': 'HYBRID', # Combines vector and keyword search
'filter': {
'equals': {
'key': 'category',
'value': 'approved'
}
}
}
}
)
results = []
for item in response['retrievalResults']:
results.append({
'content': item['content']['text'],
'source': item['location']['s3Location']['uri'],
'score': item['score'],
'metadata': item.get('metadata', {})
})
except Exception as e:
print(f"Error querying knowledge base {kb_id}: {e}")
return []
def rerank_results(self, query: str, results: List[Dict]) -> List[Dict]:
"""
Rerank results using semantic similarity and relevance scoring
"""
# Simple reranking based on score and content length
# In production, you might use a dedicated reranking model
def calculate_relevance_score(result):
base_score = result['score']
content_length = len(result['content'])
# Prefer results with moderate length (not too short, not too long)
length_penalty = 1.0
if content_length < 50:
length_penalty = 0.7
elif content_length > 2000:
length_penalty = 0.8
# Boost score for results from specific domains
domain_boost = 1.0
if result.get('domain') == 'technical':
domain_boost = 1.2
return base_score * length_penalty * domain_boost
# Sort by relevance score
for result in results:
result['relevance_score'] = calculate_relevance_score(result)
return sorted(results, key=lambda x: x['relevance_score'], reverse=True)
def generate_multi_source_response(self, query: str, results: List[Dict]) -> str:
"""
Generate response using multiple sources with proper attribution
"""
context_blocks = []
for i, result in enumerate(results, 1):
source_name = result['source'].split('/')[-1]
kb_name = result.get('knowledge_base', 'Unknown')
context_block = f"""
Source {i} ({kb_name} - {source_name}):
{result['content']}
"""
context_blocks.append(context_block)
combined_context = '\n'.join(context_blocks)
prompt = f"""
You are an expert AI assistant that provides comprehensive answers based on multiple information sources.
Context from Knowledge Bases:
{combined_context}
User Question: {query}
Instructions:
1. Provide a comprehensive answer using information from the provided sources
2. Cite sources using the format [Source X] where X is the source number
3. If sources contain conflicting information, acknowledge this and explain the different viewpoints
4. Synthesize information across sources to provide the most complete answer possible
5. If the sources don't fully address the question, state what information is missing
Answer:
"""
response = self.bedrock_runtime.invoke_model(
modelId='anthropic.claude-3-sonnet-20240229-v1:0',
body=json.dumps({
'anthropic_version': 'bedrock-2023-05-31',
'max_tokens': 1500,
'temperature': 0.3,
'messages': [{'role': 'user', 'content': prompt}]
})
)
response_body = json.loads(response['body'].read())
return response_body['content'][0]['text']
def conversational_rag(self, query: str, kb_id: str, session_id: str,
conversation_history: List[Dict] = None) -> Dict:
"""
Implement conversational RAG with memory and context
"""
if conversation_history is None:
conversation_history = []
# Build conversation context
context_messages = []
for turn in conversation_history[-5:]: # Keep last 5 turns
context_messages.extend([
{'role': 'user', 'content': turn['user']},
{'role': 'assistant', 'content': turn['assistant']}
])
# Use RetrieveAndGenerate for conversational RAG
try:
response = self.bedrock_agent_runtime.retrieve_and_generate(
input={'text': query},
retrieveAndGenerateConfiguration={
'type': 'KNOWLEDGE_BASE',
'knowledgeBaseConfiguration': {
'knowledgeBaseId': kb_id,
'modelArn': 'arn:aws:bedrock:us-east-1::foundation-model/anthropic.claude-3-sonnet-20240229-v1:0',
'generationConfiguration': {
'promptTemplate': {
'textPromptTemplate': '''
You are an AI assistant engaged in a conversation. Use the provided context and conversation history to give helpful responses.
Previous conversation:
{conversation_history}
Current context from knowledge base:
$search_results$
Current question: $query$
Provide a natural, conversational response that:
1. Acknowledges the conversation history when relevant
2. Uses the retrieved context to answer accurately
3. Maintains conversational flow
4. Cites sources when making specific claims
Response:'''
}
}
}
},
sessionId=session_id
)
return {
'answer': response['output']['text'],
'session_id': response['sessionId'],
'citations': response.get('citations', [])
}
except Exception as e:
return {'error': f"Conversational RAG error: {e}"}
# Usage example
def demo_advanced_rag():
"""
Demonstrate advanced RAG capabilities
"""
rag_system = AdvancedRAGSystem()
# Configure multiple knowledge bases
kb_configs = [
{
'id': 'technical-kb-123',
'name': 'Technical Documentation',
'domain': 'technical',
'max_results': 3
},
{
'id': 'policy-kb-456',
'name': 'Company Policies',
'domain': 'policy',
'max_results': 3
},
{
'id': 'faq-kb-789',
'name': 'FAQ Database',
'domain': 'support',
'max_results': 2
}
]
# Multi-knowledge base query
query = "What are the security requirements for cloud deployment?"
result = rag_system.multi_knowledge_base_rag(query, kb_configs)
print("Multi-KB RAG Result:")
print(f"Answer: {result['answer']}")
print(f"Sources: {result['sources']}")
print(f"Knowledge Bases Used: {result['knowledge_bases_used']}")
# Conversational RAG
conversation_history = [
{
'user': 'What is our data retention policy?',
'assistant': 'According to company policy, we retain customer data for 7 years after account closure.'
}
]
follow_up_query = "What about data stored in the cloud?"
conv_result = rag_system.conversational_rag(
follow_up_query,
'policy-kb-456',
'session-123',
conversation_history
)
print(f"\nConversational RAG Result: {conv_result['answer']}")
if __name__ == "__main__":
demo_advanced_rag()
return results
# Complete implementation of various agent action group patterns
import boto3
import json
from datetime import datetime, timedelta
from typing import Dict, List, Any
class ComprehensiveAgentActionGroups:
"""
Complete implementation of various agent action group patterns
"""
def __init__(self):
# Initialize Bedrock agent client and DynamoDB resource
self.bedrock_agent = boto3.client('bedrock-agent')
self.dynamodb = boto3.resource('dynamodb')
def create_customer_service_action_group(self, agent_id: str, agent_version: str) -> Dict:
"""
Create comprehensive customer service action group
"""
# Define OpenAPI schema for customer service actions
api_schema = {
"openapi": "3.0.1",
"info": {
"title": "Customer Service API",
"version": "1.0.0",
"description": "Comprehensive customer service operations"
},
"paths": {
"/customer/{customer_id}": {
"get": {
"summary": "Retrieve customer information",
"operationId": "get_customer_info",
"parameters": [{
"name": "customer_id",
"in": "path",
"required": True,
"schema": {"type": "string"},
"description": "Unique customer identifier"
}],
"responses": {
"200": {
"description": "Customer information retrieved",
"content": {
"application/json": {
"schema": {
"type": "object",
"properties": {
"customer_id": {"type": "string"},
"name": {"type": "string"},
"email": {"type": "string"},
"status": {"type": "string"},
"tier": {"type": "string"},
"last_interaction": {"type": "string"}
}
}
}
}
}
}
}
},
"/ticket": {
"post": {
"summary": "Create support ticket",
"operationId": "create_support_ticket",
"requestBody": {
"required": True,
"content": {
"application/json": {
"schema": {
"type": "object",
"required": ["customer_id", "subject", "priority"],
"properties": {
"customer_id": {"type": "string"},
"subject": {"type": "string"},
"description": {"type": "string"},
"priority": {"type": "string", "enum": ["low", "medium", "high", "critical"]},
"category": {"type": "string"}
}
}
}
}
}
}
},
# API schema and Lambda handler for customer service operations
"/order/{order_id}/status": {
"get": {
# Get order status
"summary": "Get order status",
"operationId": "get_order_status",
"parameters": [{
"name": "order_id",
"in": "path",
"required": True,
"schema": {"type": "string"}
}]
}
},
"/refund": {
"post": {
# Process refund request
"summary": "Process refund request",
"operationId": "process_refund",
"requestBody": {
"required": True,
"content": {
"application/json": {
"schema": {
"type": "object",
"required": ["order_id", "amount", "reason"],
"properties": {
"order_id": {"type": "string"},
"amount": {"type": "number"},
"reason": {"type": "string"},
"refund_method": {"type": "string"}
}
}
}
}
}
}
}
# Create action group
response = self.bedrock_agent.create_agent_action_group(
agentId=agent_id,
agentVersion=agent_version,
actionGroupName='CustomerServiceActions',
description='Comprehensive customer service operations including customer lookup, ticket creation, order status, and refunds',
actionGroupExecutor={
'lambda': 'arn:aws:lambda:us-east-1:123456789012:function:CustomerServiceHandler'
},
apiSchema={ 'payload': json.dumps(api_schema) },
actionGroupState='ENABLED'
)
return response['agentActionGroup']
def customer_service_lambda_handler(event, context):
"""
Comprehensive Lambda handler for customer service action group
"""
function_name = event['function']
parameters = {p['name']: p['value'] for p in event.get('parameters', [])}
try:
if function_name == 'get_customer_info':
result = handle_get_customer_info(parameters)
elif function_name == 'create_support_ticket':
result = handle_create_support_ticket(parameters)
elif function_name == 'get_order_status':
result = handle_get_order_status(parameters)
elif function_name == 'process_refund':
result = handle_process_refund(parameters)
else:
result = {'error': fUnknown function: {function_name}}
response_body = {'TEXT': {'body': json.dumps(result)}}
except Exception as e:
response_body = {'TEXT': {'body': json.dumps({'error': str(e)})}}
return {
'messageVersion': event['messageVersion'],
'response': {
'actionGroup': event['actionGroup'],
'function': function_name,
'functionResponse': {
'responseBody': response_body
}
}
}
# Handle customer information retrieval
def handle_get_customer_info(parameters):
"""Handle customer information retrieval"""
customer_id = parameters.get('customer_id')
if not customer_id:
return {'error': 'Customer ID is required'}
# Simulate database lookup
customer_data = {
'customer_id': customer_id,
'name': 'John Smith',
'email': 'john.smith@email.com',
'status': 'active',
'tier': 'premium',
'last_interaction': '2024-01-15T10:30:00Z',
'total_orders': 15,
'lifetime_value': 2500.00
}
return {
'success': True,
'customer': customer_data,
'message': fCustomer information retrieved for ID: {customer_id}
}
def handle_create_support_ticket(parameters):
"""Handle support ticket creation"""
required_fields = ['customer_id', 'subject', 'priority']
for field in required_fields:
if not parameters.get(field):
return {'error': f'Missing required field: {field}'}
# Generate ticket ID
ticket_id = f"TKT-{datetime.now().strftime('%Y%m%d')}-{hash(parameters['subject']) % 10000:04d}"
ticket_data = {
'ticket_id': ticket_id,
'customer_id': parameters['customer_id'],
'subject': parameters['subject'],
'description': parameters.get('description', ''),
'priority': parameters['priority'],
'category': parameters.get('category', 'general'),
'status': 'open',
'created_at': datetime.now().isoformat(),
'assigned_to': determine_assignment(parameters['priority'])
}
# In production, save to database
return {
'success': True,
'ticket': ticket_data,
'message': f'Support ticket created successfully: {ticket_id}'
}
def handle_get_order_status(parameters):
"""Handle order status lookup"""
order_id = parameters.get('order_id')
if not order_id:
return {'error': 'Order ID is required'}
# Simulate order lookup
order_status = {
'order_id': order_id,
'status': 'shipped',
'tracking_number': 'TRK123456789',
'estimated_delivery': (datetime.now() + timedelta(days=2)).strftime('%Y-%m-%d'),
'items': [
{'name': 'Product A', 'quantity': 2, 'status': 'shipped'},
{'name': 'Product B', 'quantity': 1, 'status': 'shipped'}
],
'shipping_address': '123 Main St, Anytown, USA'
}
return {
'success': True,
'order': order_status,
'message': f'Order status retrieved for: {order_id}'
}
def handle_process_refund(parameters):
"""Handle refund processing"""
required_fields = ['order_id', 'amount', 'reason']
for field in required_fields:
if not parameters.get(field):
return {'error': f'Missing required field: {field}'}
order_id = parameters['order_id']
amount = float(parameters['amount'])
reason = parameters['reason']
# Validate refund amount (simulate business logic)
if amount <= 0:
return {'error': 'Refund amount must be positive'}
if amount > 1000: # Example business rule
return {'error': 'Refunds over $1000 require manager approval'}
# Generate refund ID
refund_id = f"REF-{datetime.now().strftime('%Y%m%d')}-{hash(order_id) % 10000:04d}"
refund_data = {
'refund_id': refund_id,
'order_id': order_id,
'amount': amount,
'reason': reason,
'method': parameters.get('refund_method', 'original_payment'),
'status': 'processing',
'processing_time': '3-5 business days',
'initiated_at': datetime.now().isoformat()
}
return {
'success': True,
'refund': refund_data,
'message': f'Refund initiated successfully: {refund_id}'
}
def determine_assignment(priority):
"""Determine ticket assignment based on priority"""
assignment_map = {
'critical': 'senior-support-team',
'high': 'escalation-team',
'medium': 'general-support-team',
'low': 'tier-1-support'
}
return assignment_map.get(priority, 'general-support-team')
def create_approval_workflow_action_group(agent_id: str, agent_version: str):
"""
Create action group that requires external approval workflows
"""
api_schema = {
"openapi": "3.0.1",
"info": {
"title": "Approval Workflow API",
"version": "1.0.0"
},
"paths": {
"/approval/request": {
"post": {
"summary": "Request approval for high-value actions",
"operationId": "request_approval",
"requestBody": {
"required": True,
"content": {
"application/json": {
"schema": {
"type": "object",
"properties": {
"action_type": {"type": "string"},
"amount": {"type": "number"},
"justification": {"type": "string"},
"requester": {"type": "string"}
}
}
}
}
}
}
}
}
}
bedrock_agent = boto3.client('bedrock-agent')
response = bedrock_agent.create_agent_action_group(
agentId=agent_id,
agentVersion=agent_version,
actionGroupName='ApprovalWorkflow',
description='Handles approval workflows for high-value or sensitive actions',
actionGroupExecutor={
'customControl': 'RETURN_CONTROL' # Return of Control
},
apiSchema={'payload': json.dumps(api_schema)},
actionGroupState='ENABLED'
)
return response['agentActionGroup']
def approval_workflow_handler(event, context):
"""
Handle return of control for approval workflows
"""
function_name = event['function']
parameters = {p['name']: p['value'] for p in event.get('parameters', [])}
if function_name == 'request_approval':
# Return control to calling application for external approval
return {
'messageVersion': event['messageVersion'],
'response': {
'actionGroup': event['actionGroup'],
'function': function_name,
'functionResponse': {
'responseState': 'REPROMPT',
'responseBody': {
'TEXT': {
'body': json.dumps({
'approval_required': True,
'approval_type': parameters.get('action_type'),
'amount': parameters.get('amount'),
'workflow_id': f"WF-{datetime.now().strftime('%Y%m%d%H%M%S')}",
'message': 'External approval required. Please complete approval workflow.'
})
}
}
}
}
}
# Usage examples
if __name__ == "__main__":
action_groups = ComprehensiveAgentActionGroups()
# Create customer service action group
cs_action_group = action_groups.create_customer_service_action_group(
agent_id='AGENT123456',
agent_version='DRAFT'
)
print("Customer Service Action Group created:")
print(json.dumps(cs_action_group, indent=2, default=str))
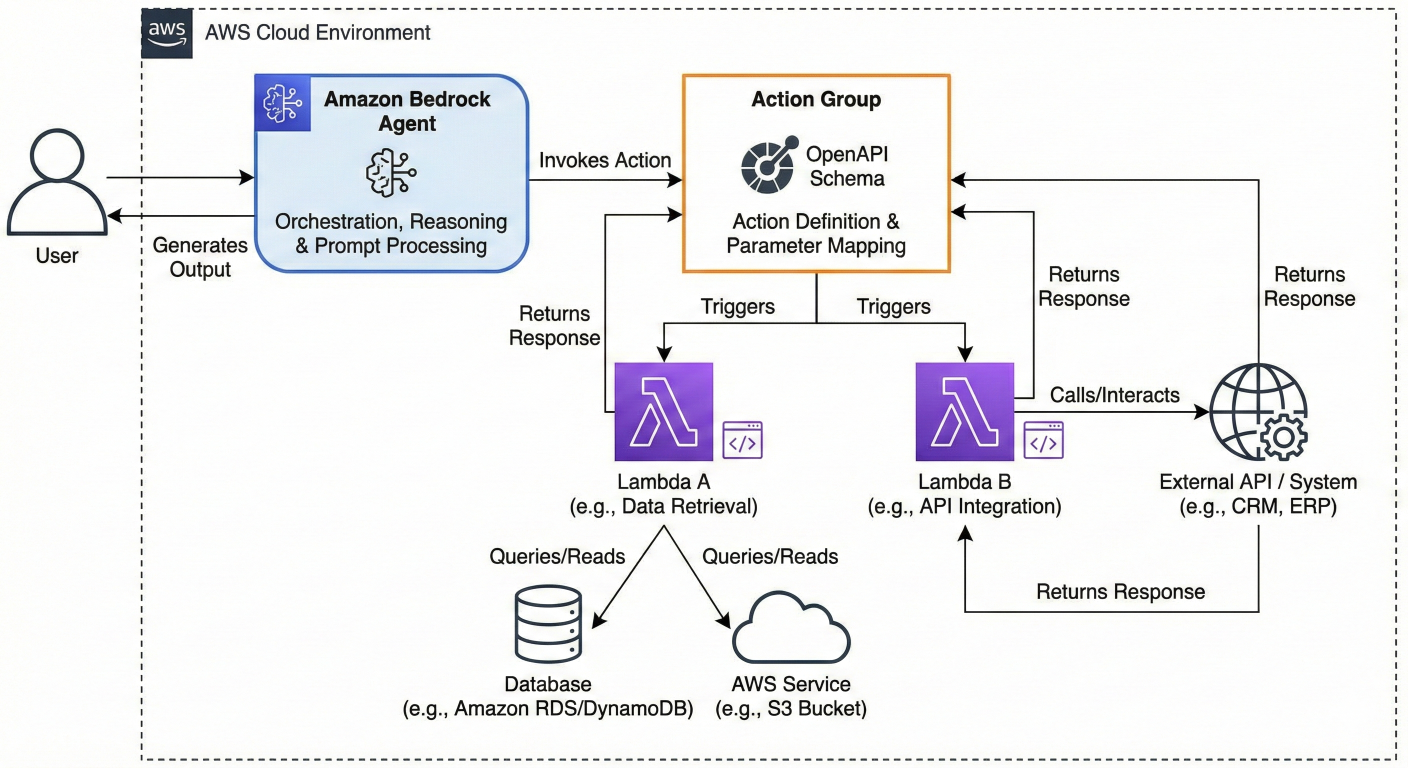
Code architecture diagram showing the relationship between agents, action groups, Lambda functions, and external systems
Amazon Bedrock's Prompt Optimization feature revolutionizes the traditionally manual process of prompt engineering by automatically enhancing prompts for specific use cases and target models. This AI-driven capability can significantly improve model performance across various tasks including classification, summarization, and complex reasoning.
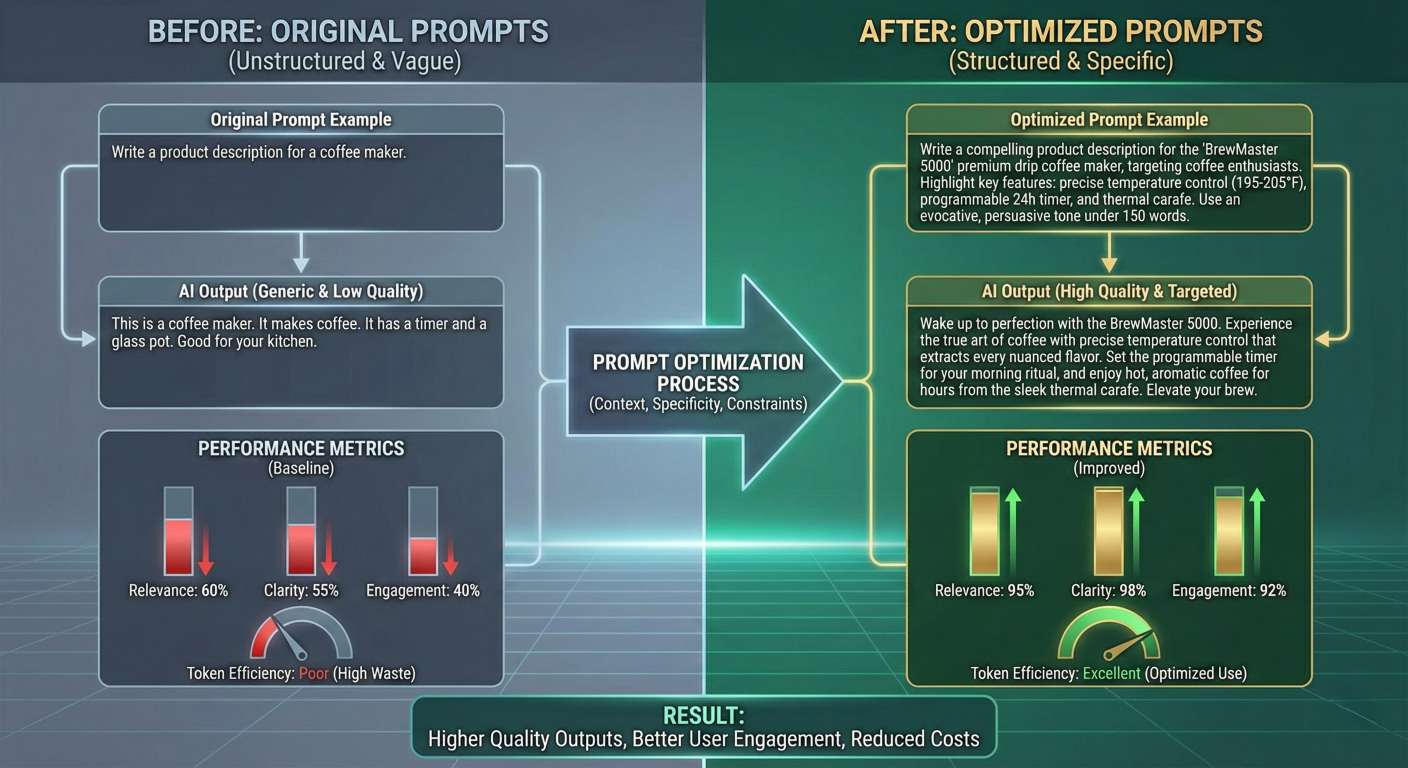
Before and after comparison showing original prompts vs. optimized prompts with performance metrics
Automated Prompt Enhancement Process:
1. Prompt Analysis: AI system decomposes prompt structure and extracts key elements
2. Component Identification: Isolates task instructions, input context, and examples
3. Prompt Rewriting: Applies model-specific optimization strategies
4. Structure Improvement: EnhanceDifferent models require tailored optimization approaches: s clarity, specificity, and formatting
import boto3
import json
from typing import Dict, Any
class BedrockPromptOptimizer:
"""
Comprehensive prompt optimization implementation
"""
def __init__(self, region='us-east-1'):
self.bedrock_client = boto3.client('bedrock', region_name=region)
def optimize_prompt(self, original_prompt: str, target_model: str, use_case: str = None) -> Dict[str, Any]:
"""
Optimize prompt for specific model and use case
"""
try:
response = self.bedrock_client.create_prompt_optimization_job(
jobName=f"optimization-{use_case or 'general'}-{int(time.time())}",
roleArn='arn:aws:iam::123456789012:role/BedrockOptimizationRole',
sourcePrompt={
'textPromptTemplate': original_prompt
},
targetModelId=target_model,
optimizationConfig={
'targetModelId': target_model
}
)
job_arn = response['jobArn']
# Poll for completion
optimized_prompt = self.wait_for_optimization_completion(job_arn)
return {
'original_prompt': original_prompt,
'optimized_prompt': optimized_prompt,
'target_model': target_model,
'improvement_notes': self.analyze_optimization_improvements(original_prompt, optimized_prompt)
}
except Exception as e:
return {'error': f"Optimization failed: {e}"}
def wait_for_optimization_completion(self, job_arn: str) -> str:
"""
Wait for optimization job to complete and return optimized prompt
"""
import time
while True:
response = self.bedrock_client.get_prompt_optimization_job(
jobIdentifier=job_arn
)
status = response['status']
if status == 'COMPLETED':
return response['outputPrompt']['textPromptTemplate']
elif status == 'FAILED':
raise Exception(f"Optimization failed: {response.get('failureMessage', 'Unknown error')}")
time.sleep(30) # Check every 30 seconds
def analyze_optimization_improvements(self, original: str, optimized: str) -> Dict[str, str]:
"""
Analyze improvements made during optimization
"""
improvements = {
'length_change': f"{'Expanded' if len(optimized) > len(original) else 'Condensed'} by {abs(len(optimized) - len(original))} characters",
'structure_improvements': [],
'clarity_enhancements': []
}
# Analyze structural improvements
if '###' in optimized and '###' not in original:
improvements['structure_improvements'].append('Added clear section headers')
if 'Step ' in optimized and 'Step ' not in original:
improvements['structure_improvements'].append('Added step-by-step structure')
if 'Example:' in optimized and 'Example:' not in original:
improvements['structure_improvements'].append('Added examples for clarity')
# Analyze clarity enhancements
clarity_indicators = [
('specific', 'Added specific instructions'),
('format', 'Improved output formatting guidance'),
('context', 'Enhanced context handling'),
('constraint', 'Added helpful constraints')
]
for indicator, description in clarity_indicators:
if indicator in optimized.lower() and indicator not in original.lower():
improvements['clarity_enhancements'].append(description)
return improvements
# Advanced prompt engineering patterns
class PromptEngineeringBestPractices:
"""
Comprehensive prompt engineering best practices and patterns
"""
@staticmethod
def create_few_shot_prompt(task_description: str, examples: list, new_input: str) -> str:
"""
Create few-shot learning prompts with examples
"""
prompt_parts = [task_description, "\nHere are some examples:\n"]
for i, example in enumerate(examples, 1):
prompt_parts.append(f"Example {i}:")
prompt_parts.append(f"Input: {example['input']}")
prompt_parts.append(f"Output: {example['output']}\n")
prompt_parts.extend([
f"Now, please process this new input:",
f"Input: {new_input}",
f"Output:"
])
return "\n".join(prompt_parts)
@staticmethod
def create_chain_of_thought_prompt(problem: str, reasoning_steps: bool = True) -> str:
"""
Create prompts that encourage step-by-step reasoning
"""
if reasoning_steps:
prompt = f"""
Please solve this problem step by step, showing your reasoning at each stage.
Problem: {problem}
Please follow this format:
1. Understanding: [What is being asked?]
2. Analysis: [What information do we have?]
3. Approach: [What method will you use?]
4. Solution: [Step-by-step solution]
5. Answer: [Final answer]
Begin your response:
"""
else:
prompt = f"""
Solve this problem and explain your reasoning:
{problem}
Think through this step by step before giving your final answer.
"""
return prompt.strip()
@staticmethod
def create_role_based_prompt(role: str, context: str, task: str) -> str:
"""
Create prompts with specific role assignments
"""
prompt = f"""
You are a {role}. {context}
Your task is to: {task}
Please respond in character, using your expertise and experience in this role.
Consider the following in your response:
- Use appropriate professional language and terminology
- Draw from relevant best practices in your field
- Provide actionable insights where applicable
- Structure your response clearly and professionally
Response:
"""
return prompt.strip()
@staticmethod
def create_structured_output_prompt(task: str, output_format: Dict) -> str:
"""
Create prompts that specify structured output formats
"""
format_description = json.dumps(output_format, indent=2)
prompt = f"""
{task}
Please provide your response in the following JSON format:
{format_description}
Ensure your response is valid JSON and follows the exact structure specified above.
Response:
"""
return prompt.strip()
# Usage examples and testing
def demonstrate_prompt_optimization():
"""
Demonstrate various prompt optimization techniques
"""
optimizer = BedrockPromptOptimizer()
best_practices = PromptEngineeringBestPractices()
# Example 1: Basic prompt optimization
original_prompt = "Summarize this text."
optimized_result = optimizer.optimize_prompt(
original_prompt,
target_model='anthropic.claude-3-sonnet-20240229-v1:0',
use_case='summarization'
)
print("Prompt Optimization Result:")
print(f"Original: {optimized_result['original_prompt']}")
print(f"Optimized: {optimized_result['optimized_prompt']}")
print(f"Improvements: {optimized_result['improvement_notes']}")
# Example 2: Few-shot learning prompt
few_shot_examples = [
{
'input': 'The quarterly sales report shows a 15% increase in revenue.',
'output': 'Positive - Revenue growth indicates business success'
},
{
'input': 'Customer complaints have doubled this month.',
'output': 'Negative - Increasing complaints suggest service issues'
}
]
few_shot_prompt = best_practices.create_few_shot_prompt(
"Analyze the business sentiment of the following statements:",
few_shot_examples,
"Our new product launch exceeded expectations with pre-orders."
)
print("\nFew-shot Learning Prompt:")
print(few_shot_prompt)
# Example 3: Chain of thought prompt
cot_prompt = best_practices.create_chain_of_thought_prompt(
"A company's revenue increased from $100M to $120M. If their profit margin improved from 8% to 12%, what was the change in absolute profit?"
)
print("\nChain of Thought Prompt:")
print(cot_prompt)
# Example 4: Structured output prompt
output_format = {
"summary": "string - brief summary",
"key_points": ["array of main points"],
"sentiment": "positive/negative/neutral",
"confidence": "number between 0 and 1"
}
structured_prompt = best_practices.create_structured_output_prompt(
"Analyze the following customer feedback and provide insights:",
output_format
)
print("\nStructured Output Prompt:")
print(structured_prompt)
if __name__ == "__main__":
demonstrate_prompt_optimization()
Different models require tailored optimization approaches:
- Use XML tags for structured inputs: `<document>
Effective model versioning ensures reproducibility, enables rollback capabilities, and supports controlled deployment of model updates.
import boto3
import json
from datetime import datetime
from typing import Dict, List, Optional
class BedrockModelVersionManager:
"""
Comprehensive model version management system
"""
def __init__(self):
self.bedrock_client = boto3.client('bedrock')
self.dynamodb = boto3.resource('dynamodb')
self.model_registry = self.dynamodb.Table('BedrockModelRegistry')
def register_model_version(self, model_config: Dict) -> str:
"""
Register a new model version with comprehensive metadata
"""
version_id = f"{model_config['model_name']}-v{model_config['version']}-{int(datetime.now().timestamp())}"
registry_entry = {
'version_id': version_id,
'model_name': model_config['model_name'],
'model_id': model_config['model_id'],
'version': model_config['version'],
'description': model_config.get('description', ''),
'capabilities': model_config.get('capabilities', []),
'performance_metrics': model_config.get('performance_metrics', {}),
'deployment_config': model_config.get('deployment_config', {}),
'created_at': datetime.now().isoformat(),
'status': 'registered',
'tags': model_config.get('tags', {}),
'compatibility': model_config.get('compatibility', {}),
'deprecation_date': model_config.get('deprecation_date'),
'migration_path': model_config.get('migration_path', [])
}
# Store in registry
self.model_registry.put_item(Item=registry_entry)
return version_id
def create_deployment_strategy(self, version_id: str, strategy_type: str = 'blue_green') -> Dict:
"""
Create deployment strategy for model version updates
"""
strategies = {
'blue_green': self._create_blue_green_strategy,
'canary': self._create_canary_strategy,
'rolling': self._create_rolling_strategy
}
if strategy_type not in strategies:
raise ValueError(f"Unknown strategy type: {strategy_type}")
return strategies[strategy_type](version_id)
def _create_blue_green_strategy(self, version_id: str) -> Dict:
"""
Blue-green deployment strategy
"""
return {
'strategy': 'blue_green',
'version_id': version_id,
'phases': [
{
'phase': 'preparation',
'duration': '30m',
'actions': [
'provision_new_environment',
'deploy_new_version',
'run_smoke_tests'
]
},
{
'phase': 'validation',
'duration': '1h',
'actions': [
'run_integration_tests',
'performance_validation',
'security_scan'
]
},
{
'phase': 'cutover',
'duration': '5m',
'actions': [
'update_load_balancer',
'verify_traffic_routing',
'monitor_error_rates'
]
},
{
'phase': 'monitoring',
'duration': '2h',
'actions': [
'monitor_performance_metrics',
'validate_business_metrics',
'prepare_rollback_if_needed'
]
}
],
'rollback_plan': {
'trigger_conditions': [
'error_rate > 5%',
'latency_p99 > 2000ms',
'business_metric_degradation > 10%'
],
'rollback_time': '2m'
}
}
def _create_canary_strategy(self, version_id: str) -> Dict:
"""
Canary deployment strategy
"""
return {
'strategy': 'canary',
'version_id': version_id,
'traffic_splits': [
{'percentage': 5, 'duration': '1h'},
{'percentage': 25, 'duration': '2h'},
{'percentage': 50, 'duration': '2h'},
{'percentage': 100, 'duration': 'indefinite'}
],
'success_criteria': {
'error_rate_threshold': 2.0,
'latency_p95_threshold': 1500,
'business_metric_threshold': 0.95
},
'monitoring': {
'metrics': [
'request_count',
'error_rate',
'latency_percentiles',
'business_conversion_rate'
],
'alerting': {
'channels': ['slack', 'email', 'pagerduty'],
'escalation_policy': 'immediate_for_critical'
}
}
}
def validate_model_compatibility(self, current_version: str, target_version: str) -> Dict:
"""
Validate compatibility between model versions
"""
current_model = self.get_model_version(current_version)
target_model = self.get_model_version(target_version)
compatibility_issues = []
# Check API compatibility
current_inputs = current_model.get('compatibility', {}).get('input_format', [])
target_inputs = target_model.get('compatibility', {}).get('input_format', [])
if not set(current_inputs).issubset(set(target_inputs)):
compatibility_issues.append({
'type': 'input_format_incompatibility',
'description': 'Target model does not support all current input formats',
'impact': 'high'
})
# Check performance expectations
current_perf = current_model.get('performance_metrics', {})
target_perf = target_model.get('performance_metrics', {})
if target_perf.get('latency_p95', 0) > current_perf.get('latency_p95', 0) * 1.5:
compatibility_issues.append({
'type': 'performance_degradation',
'description': 'Target model has significantly higher latency',
'impact': 'medium'
})
# Check capability requirements
current_caps = set(current_model.get('capabilities', []))
target_caps = set(target_model.get('capabilities', []))
missing_capabilities = current_caps - target_caps
if missing_capabilities:
compatibility_issues.append({
'type': 'missing_capabilities',
'description': f'Target model missing capabilities: {missing_capabilities}',
'impact': 'high'
})
return {
'compatible': len(compatibility_issues) == 0,
'issues': compatibility_issues,
'migration_required': len([i for i in compatibility_issues if i['impact'] == 'high']) > 0
}
def create_migration_plan(self, current_version: str, target_version: str) -> Dict:
"""
Create detailed migration plan between model versions
"""
compatibility_check = self.validate_model_compatibility(current_version, target_version)
migration_plan = {
'source_version': current_version,
'target_version': target_version,
'compatibility_status': compatibility_check,
'migration_steps': [],
'estimated_duration': '0h',
'risk_assessment': 'low'
}
if not compatibility_check['compatible']:
migration_plan['migration_steps'].extend([
{
'step': 'code_updates',
'description': 'Update application code for compatibility',
'duration': '4h',
'risk': 'medium'
},
{
'step': 'testing',
'description': 'Comprehensive testing with new model',
'duration': '8h',
'risk': 'low'
}
])
migration_plan['estimated_duration'] = '12h'
migration_plan['risk_assessment'] = 'medium'
migration_plan['migration_steps'].extend([
{
'step': 'backup_current',
'description': 'Backup current model configuration',
'duration': '15m',
'risk': 'low'
},
{
'step': 'deploy_target',
'description': 'Deploy target model version',
'duration': '30m',
'risk': 'medium'
},
{
'step': 'validation',
'description': 'Validate new model performance',
'duration': '1h',
'risk': 'low'
}
])
return migration_plan
def get_model_version(self, version_id: str) -> Dict:
"""
Retrieve model version details from registry
"""
response = self.model_registry.get_item(Key={'version_id': version_id})
return response.get('Item', {})
def list_model_versions(self, model_name: str, status: str = None) -> List[Dict]:
"""
List all versions of a specific model
"""
# In production, this would use appropriate DynamoDB queries
# This is a simplified example
versions = []
# Simulate database query results
mock_versions = [
{
'version_id': f'{model_name}-v1.0-123456789',
'version': '1.0',
'status': 'deprecated',
'created_at': '2024-01-01T00:00:00Z'
},
{
'version_id': f'{model_name}-v1.1-234567890',
'version': '1.1',
'status': 'active',
'created_at': '2024-02-01T00:00:00Z'
},
{
'version_id': f'{model_name}-v2.0-345678901',
'version': '2.0',
'status': 'beta',
'created_at': '2024-03-01T00:00:00Z'
}
]
for version in mock_versions:
if status is None or version['status'] == status:
versions.append(version)
return versions
# Example usage and testing
def demonstrate_version_management():
"""
Demonstrate model version management capabilities
"""
version_manager = BedrockModelVersionManager()
# Register a new model version
model_config = {
'model_name': 'customer-sentiment-analyzer',
'model_id': 'anthropic.claude-3-sonnet-20240229-v1:0',
'version': '2.1',
'description': 'Enhanced customer sentiment analysis with improved accuracy',
'capabilities': ['text_classification', 'sentiment_analysis', 'confidence_scoring'],
'performance_metrics': {
'accuracy': 0.94,
'precision': 0.92,
'recall': 0.96,
'latency_p95': 850
},
'compatibility': {
'input_format': ['json', 'plain_text'],
'output_format': ['json'],
'api_version': '2.1'
},
'tags': {
'environment': 'production',
'team': 'ml-platform',
'cost_center': 'engineering'
}
}
version_id = version_manager.register_model_version(model_config)
print(f"Registered model version: {version_id}")
# Create deployment strategy
deployment_strategy = version_manager.create_deployment_strategy(version_id, 'canary')
print(f"Deployment strategy: {deployment_strategy['strategy']}")
# Validate compatibility
compatibility = version_manager.validate_model_compatibility(
'customer-sentiment-analyzer-v2.0-123456789',
version_id
)
print(f"Compatibility check: {compatibility}")
# Create migration plan
if not compatibility['compatible']:
migration_plan = version_manager.create_migration_plan(
'customer-sentiment-analyzer-v2.0-123456789',
version_id
)
print(f"Migration plan duration: {migration_plan['estimated_duration']}")
if __name__ == "__main__":
demonstrate_version_management()
Amazon Bedrock Guardrails provides multi-layered protection against harmful content, prompt attacks, and policy violations. Implementing comprehensive safety measures requires careful configuration of content filters, topic restrictions, and monitoring systems.
import boto3
import json
from typing import Dict, List, Any
from enum import Enum
class GuardrailFilterStrength(Enum):
"""Enumeration of guardrail filter strengths"""
NONE = "NONE"
LOW = "LOW"
MEDIUM = "MEDIUM"
HIGH = "HIGH"
class BedrockGuardrailManager:
"""
Comprehensive guardrail management and implementation
"""
def __init__(self):
self.bedrock_client = boto3.client('bedrock')
self.bedrock_runtime = boto3.client('bedrock-runtime')
def create_comprehensive_guardrail(self, name: str, use_case: str) -> str:
"""
Create a comprehensive guardrail configuration for specific use cases
"""
# Define content filters based on use case
content_config = self._get_content_filter_config(use_case)
# Define topic restrictions
topic_config = self._get_topic_policy_config(use_case)
# Define word filters
word_config = self._get_word_filter_config(use_case)
# Define sensitive information filters
pii_config = self._get_pii_filter_config(use_case)
guardrail_config = {
'name': name,
'description': f'Comprehensive guardrail for {use_case} applications',
'contentPolicyConfig': content_config,
'topicPolicyConfig': topic_config,
'wordPolicyConfig': word_config,
'sensitiveInformationPolicyConfig': pii_config,
'blockedInputMessaging': 'Your request contains content that violates our usage policies. Please revise and try again.',
'blockedOutputsMessaging': 'The generated response contains inappropriate content. Please try rephrasing your request.',
'kmsKeyId': 'alias/bedrock-guardrails-key'
}
try:
response = self.bedrock_client.create_guardrail(**guardrail_config)
guardrail_id = response['guardrailId']
# Create guardrail version
version_response = self.bedrock_client.create_guardrail_version(
guardrailIdentifier=guardrail_id,
description=f'Version 1.0 for {use_case}'
)
return {
'guardrail_id': guardrail_id,
'version': version_response['version'],
'status': response['status']
}
except Exception as e:
return {'error': f'Failed to create guardrail: {e}'}
def _get_content_filter_config(self, use_case: str) -> Dict:
"""
Configure content filters based on use case requirements
"""
# Default configuration for most use cases
base_config = {
'filtersConfig': [
{
'type': 'SEXUAL',
'inputStrength': GuardrailFilterStrength.HIGH.value,
'outputStrength': GuardrailFilterStrength.HIGH.value
},
{
'type': 'VIOLENCE',
'inputStrength': GuardrailFilterStrength.HIGH.value,
'outputStrength': GuardrailFilterStrength.HIGH.value
},
{
'type': 'HATE',
'inputStrength': GuardrailFilterStrength.HIGH.value,
'outputStrength': GuardrailFilterStrength.HIGH.value
},
{
'type': 'INSULTS',
'inputStrength': GuardrailFilterStrength.MEDIUM.value,
'outputStrength': GuardrailFilterStrength.MEDIUM.value
},
{
'type': 'MISCONDUCT',
'inputStrength': GuardrailFilterStrength.MEDIUM.value,
'outputStrength': GuardrailFilterStrength.MEDIUM.value
}
]
}
# Adjust based on specific use cases
if use_case == 'customer_service':
# More lenient on insults (customers may be frustrated)
base_config['filtersConfig'][3]['inputStrength'] = GuardrailFilterStrength.LOW.value
elif use_case == 'educational':
# More strict across all categories
for filter_config in base_config['filtersConfig']:
filter_config['inputStrength'] = GuardrailFilterStrength.HIGH.value
filter_config['outputStrength'] = GuardrailFilterStrength.HIGH.value
elif use_case == 'creative_writing':
# More lenient for creative content
base_config['filtersConfig'][1]['inputStrength'] = GuardrailFilterStrength.MEDIUM.value # Violence
base_config['filtersConfig'][1]['outputStrength'] = GuardrailFilterStrength.MEDIUM.value
return base_config
def _get_topic_policy_config(self, use_case: str) -> Dict:
"""
Configure denied topics based on use case
"""
base_topics = [
{
'name': 'Financial_Advice',
'definition': 'Requests for specific financial investment advice or recommendations',
'examples': [
'Should I invest in specific stocks?',
'What cryptocurrency should I buy?',
'Give me tax advice for my situation'
],
'type': 'DENY'
},
{
'name': 'Medical_Diagnosis',
'definition': 'Requests for medical diagnosis or specific treatment recommendations',
'examples': [
'Do I have cancer based on these symptoms?',
'What medication should I take?',
'Should I stop taking my prescription?'
],
'type': 'DENY'
},
{
'name': 'Legal_Advice',
'definition': 'Requests for specific legal advice or representation',
'examples': [
'Should I sue my employer?',
'What legal strategy should I use?',
'Help me write a legal contract'
],
'type': 'DENY'
}
]
# Add use case specific topics
if use_case == 'customer_service':
base_topics.append({
'name': 'Competitor_Information',
'definition': 'Requests for detailed information about competitors',
'examples': [
'Tell me about our competitors pricing',
'How does our product compare to competitor X?'
],
'type': 'DENY'
})
elif use_case == 'educational':
base_topics.append({
'name': 'Academic_Dishonesty',
'definition': 'Requests that would facilitate cheating or plagiarism',
'examples': [
'Write my homework assignment for me',
'Give me answers to this test',
'Help me cheat on my exam'
],
'type': 'DENY'
})
return {'topicsConfig': base_topics}
def _get_word_filter_config(self, use_case: str) -> Dict:
"""
Configure word filters for profanity and custom terms
"""
base_words = [
'damn', 'hell', 'crap' # Mild profanity
]
custom_words = []
if use_case == 'customer_service':
custom_words.extend([
'scam', 'fraud', 'ripoff', # Prevent escalation language
'lawsuit', 'lawyer', 'sue' # Legal escalation terms
])
elif use_case == 'educational':
custom_words.extend([
'cheat', 'plagiarize', 'copy' # Academic integrity terms
])
return {
'wordsConfig': [
{
'text': word
} for word in base_words + custom_words
],
'managedWordListsConfig': [
{'type': 'PROFANITY'}
]
}
def _get_pii_filter_config(self, use_case: str) -> Dict:
"""
Configure PII detection and filtering
"""
base_pii_config = {
'piiEntitiesConfig': [
{
'type': 'EMAIL',
'action': 'ANONYMIZE'
},
{
'type': 'PHONE',
'action': 'ANONYMIZE'
},
{
'type': 'SSN',
'action': 'BLOCK'
},
{
'type': 'CREDIT_DEBIT_CARD_NUMBER',
'action': 'BLOCK'
}
]
}
# Add use case specific PII handling
if use_case == 'customer_service':
base_pii_config['piiEntitiesConfig'].extend([
{
'type': 'NAME',
'action': 'ANONYMIZE'
},
{
'type': 'ADDRESS',
'action': 'ANONYMIZE'
}
])
elif use_case == 'healthcare':
base_pii_config['piiEntitiesConfig'].extend([
{
'type': 'HEALTH_NUMBER',
'action': 'BLOCK'
},
{
'type': 'MEDICAL_CONDITION',
'action': 'ANONYMIZE'
}
])
return base_pii_config
def apply_guardrail_to_input(self, guardrail_id: str, guardrail_version: str,
content: str) -> Dict[str, Any]:
"""
Apply guardrail to input content before model inference
"""
try:
response = self.bedrock_runtime.apply_guardrail(
guardrailIdentifier=guardrail_id,
guardrailVersion=guardrail_version,
source='INPUT',
content=[{'text': {'text': content}}]
)
return {
'action': response['action'],
'blocked': response['action'] == 'GUARDRAIL_INTERVENED',
'assessments': response.get('assessments', []),
'outputs': response.get('outputs', [])
}
except Exception as e:
return {'error': f'Guardrail application failed: {e}'}
def apply_guardrail_to_output(self, guardrail_id: str, guardrail_version: str,
content: str) -> Dict[str, Any]:
"""
Apply guardrail to model output before returning to user
"""
try:
response = self.bedrock_runtime.apply_guardrail(
guardrailIdentifier=guardrail_id,
guardrailVersion=guardrail_version,
source='OUTPUT',
content=[{'text': {'text': content}}]
)
return {
'action': response['action'],
'blocked': response['action'] == 'GUARDRAIL_INTERVENED',
'assessments': response.get('assessments', []),
'filtered_content': response.get('outputs', [{}])[0].get('text', content)
}
except Exception as e:
return {'error': f"Guardrail application failed: {e}"}
def create_safe_inference_wrapper(self, model_id: str, guardrail_id: str,
guardrail_version: str):
"""
Create a safe inference wrapper that applies guardrails automatically
"""
def safe_invoke_model(prompt: str, **kwargs) -> Dict[str, Any]:
"""
Safely invoke model with guardrail protection
"""
# Apply input guardrails
input_check = self.apply_guardrail_to_input(guardrail_id, guardrail_version, prompt)
if input_check.get('blocked', False):
return {
'blocked_at': 'input',
'reason': input_check.get('assessments', []),
'message': 'Input content violates safety policies'
}
# Invoke model
try:
if 'anthropic.claude' in model_id:
request_body = {
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": kwargs.get('max_tokens', 1000),
"messages": [{"role": "user", "content": prompt}]
}
else:
request_body = {
"inputText": prompt,
"textGenerationConfig": {
"maxTokenCount": kwargs.get('max_tokens', 1000),
"temperature": kwargs.get('temperature', 0.7)
}
}
response = self.bedrock_runtime.invoke_model(
modelId=model_id,
body=json.dumps(request_body)
)
response_body = json.loads(response['body'].read())
if 'anthropic.claude' in model_id:
generated_text = response_body['content'][0]['text']
else:
generated_text = response_body['results'][0]['outputText']
# Apply output guardrails
output_check = self.apply_guardrail_to_output(
guardrail_id, guardrail_version, generated_text
)
if output_check.get('blocked', False):
return {
'blocked_at': 'output',
'reason': output_check.get('assessments', []),
'message': 'Generated content violates safety policies'
}
return {
'success': True,
'response': output_check.get('filtered_content', generated_text),
'input_assessments': input_check.get('assessments', []),
'output_assessments': output_check.get('assessments', [])
}
except Exception as e:
return {'error': f"Model inference failed: {e}"}
return safe_invoke_model
# Usage examples and monitoring
class GuardrailMonitoring:
"""
Monitoring and analytics for guardrail effectiveness
"""
def __init__(self):
self.cloudwatch = boto3.client('cloudwatch')
def track_guardrail_metrics(self, guardrail_id: str, intervention_data: Dict):
"""
Track guardrail intervention metrics
"""
metrics = []
# Track intervention rate
metrics.append({
'MetricName': 'GuardrailIntervention',
'Dimensions': [
{'Name': 'GuardrailId', 'Value': guardrail_id},
{'Name': 'Source', 'Value': intervention_data.get('source', 'unknown')}
],
'Value': 1 if intervention_data.get('blocked', False) else 0,
'Unit': 'Count'
})
# Track specific violation types
for assessment in intervention_data.get('assessments', []):
if 'contentPolicy' in assessment:
for filter_result in assessment['contentPolicy'].get('filters', []):
metrics.append({
'MetricName': 'ContentViolation',
'Dimensions': [
{'Name': 'GuardrailId', 'Value': guardrail_id},
{'Name': 'ViolationType', 'Value': filter_result.get('type', 'unknown')}
],
'Value': 1,
'Unit': 'Count'
})
# Send metrics to CloudWatch
try:
self.cloudwatch.put_metric_data(
Namespace='Bedrock/Guardrails',
MetricData=metrics
)
except Exception as e:
print(f"Failed to send metrics: {e}")
# Demonstration and testing
def demonstrate_guardrail_implementation():
"""
Demonstrate comprehensive guardrail implementation
"""
guardrail_manager = BedrockGuardrailManager()
monitoring = GuardrailMonitoring()
# Create guardrail for customer service use case
guardrail_config = guardrail_manager.create_comprehensive_guardrail(
name='CustomerServiceGuardrail',
use_case='customer_service'
)
print(f"Created guardrail: {guardrail_config}")
if 'guardrail_id' in guardrail_config:
guardrail_id = guardrail_config['guardrail_id']
version = guardrail_config['version']
# Create safe inference wrapper
safe_inference = guardrail_manager.create_safe_inference_wrapper(
'anthropic.claude-3-sonnet-20240229-v1:0',
guardrail_id,
version
)
# Test with safe content
safe_result = safe_inference("How can I improve customer satisfaction?")
print(f"Safe content result: {safe_result.get('success', False)}")
# Test with potentially harmful content
harmful_result = safe_inference("How can I harm my competitors?")
print(f"Harmful content blocked: {harmful_result.get('blocked_at', 'not_blocked')}")
# Monitor results
if harmful_result.get('blocked_at'):
monitoring.track_guardrail_metrics(guardrail_id, {
'blocked': True,
'source': harmful_result['blocked_at'],
'assessments': harmful_result.get('reason', [])
})
if __name__ == "__main__":
demonstrate_guardrail_implementation()
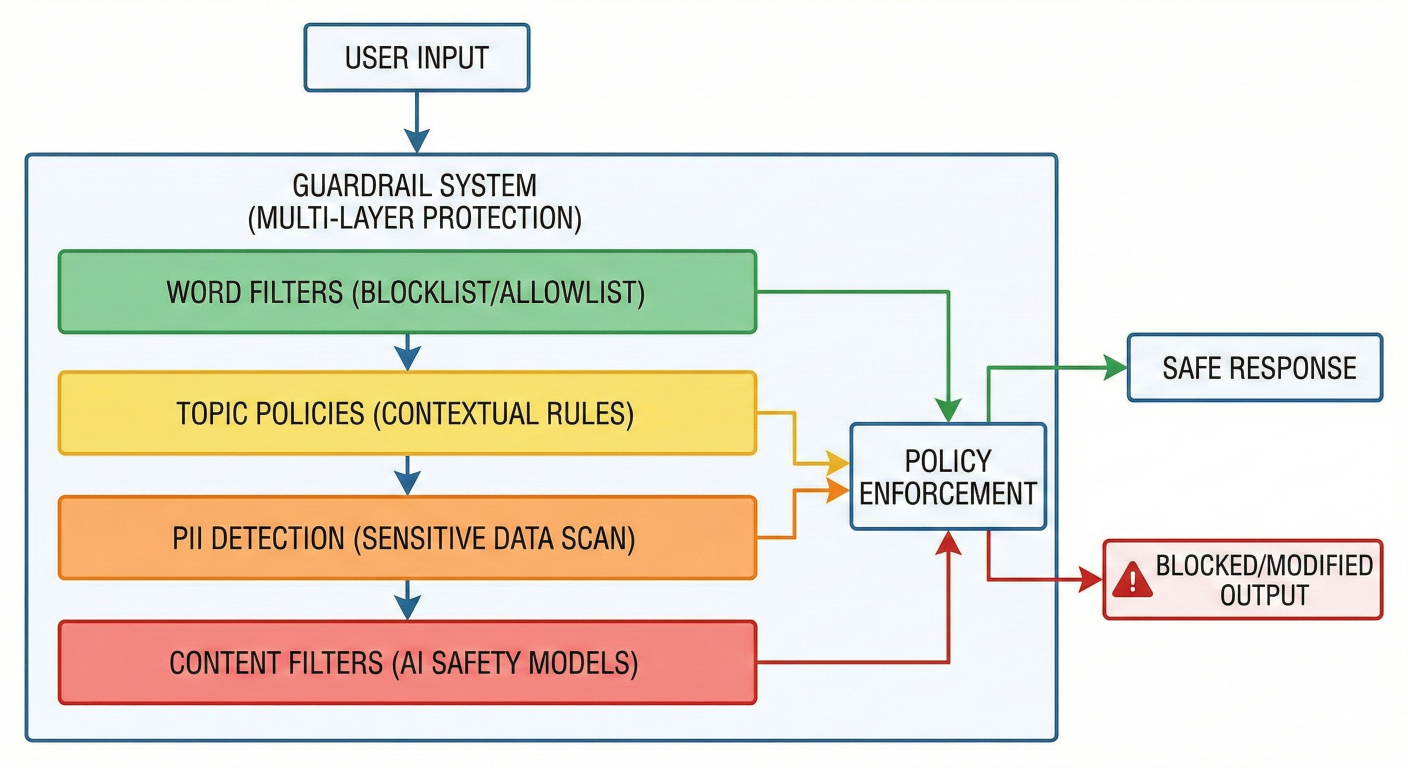
Guardrail architecture diagram showing multi-layer protection including content filters, topic policies, word filters, and PII detection
Amazon Bedrock represents a paradigm shift in how organizations approach generative AI implementation, offering an unprecedented combination of accessibility, power, and enterprise grade security. Through this comprehensive exploration, we've uncovered the platform's extensive capabilities, from its diverse foundation model ecosystem to sophisticated agent orchestration and advanced safety mechanisms.
The journey from traditional AI development—characterized by complex infrastructure management, extensive ML expertise requirements, and lengthy deployment cycles—to Bedrock's streamlined approach demonstrates AWS's commitment to democratizing artificial intelligence. Organizations can now focus on solving business problems rather than managing AI infrastructure complexities.
The foundation model diversity available through Bedrock provides organizations with unprecedented flexibility to optimize for specific use cases, performance requirements, and cost constraints. Whether leveraging Claude's conversational excellence, Titan's cost-effectiveness, or Llama's open-source adaptability, teams can select and switch between models based on evolving needs.
Knowledge Bases and RAG capabilities transform static AI systems into dynamic, context-aware applications that can access and utilize organizational knowledge in real-time. This represents a fundamental advancement from models limited to their training data toward systems that can continuously incorporate new information and domain-specific insights.
The agent orchestration framework enables the creation of sophisticated AI workflows that can reason through complex, multi-step processes while integrating with existing enterprise systems. This capability bridges the gap between simple AI assistants and comprehensive business process automation.
Success with Bedrock requires thoughtful architectural planning, comprehensive security implementation, and ongoing optimization. Organizations must carefully consider their model selection strategy, implement robust safety guardrails, and establish effective monitoring and governance frameworks.
The prompt optimization capabilities, model versioning strategies, and comprehensive safety measures detailed in this guide provide the foundation for responsible, effective AI deployment at enterprise scale.
As the generative AI landscape continues evolving rapidly, Bedrock's abstraction layer and unified API approach position organizations to adapt quickly to new models, capabilities, and techniques. The platform's comprehensive integration with AWS services creates powerful synergies for building end-to-end AI solutions that can scale with organizational needs.
The best practices, code examples, and architectural patterns presented here provide a solid foundation for immediate implementation while establishing scalable approaches for future expansion. Organizations investing in Bedrock today are positioning themselves at the forefront of the AI-driven business transformation that will define the next decade of competitive advantage.
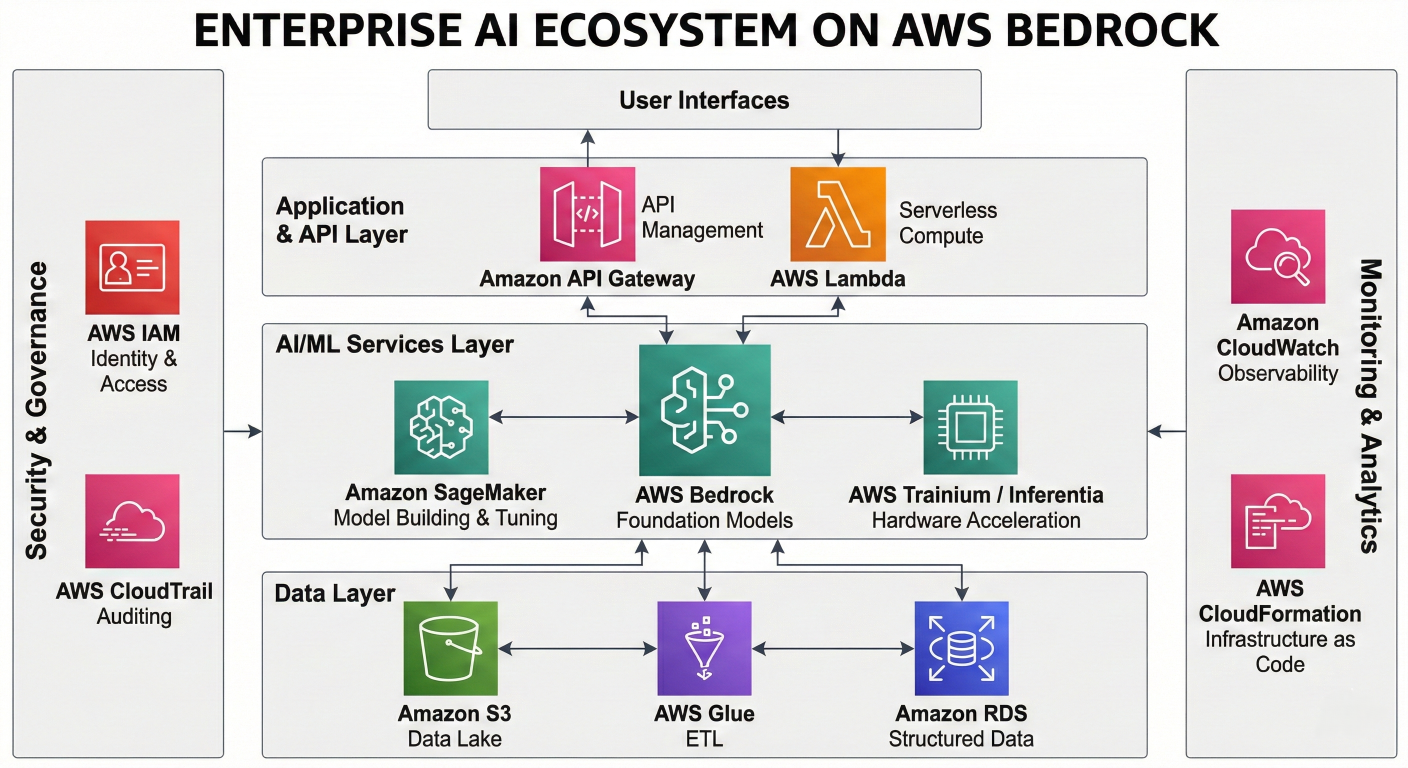
Final architecture diagram showing a complete enterprise AI ecosystem built on AWS Bedrock with all components integrated
For the most current information about AWS Bedrock features, pricing, and regional availability, consult the official AWS documentation and product pages. The rapidly evolving nature of generative AI means that new capabilities, models, and best practices are continuously emerging, making ongoing learning and adaptation essential for success in this transformative field.
AWS Bedrock roadmap and future capabilities overview diagram

{{AUTHOR}}
 Launch your Graphy
Launch your Graphy