

There are no items in your cart
Add More
Add More
| Item Details | Price | ||
|---|---|---|---|
If you have been following the trajectory of Generative AI, you know that the initial euphoria of 2023—where we marveled that ChatGPT could write a poem—has settled into the pragmatic engineering reality of 2025. We are no longer asking if Large Language Models (LLMs) are useful; we are asking how to make them accurate, reliable, and deeply knowledgeable about proprietary data. The answer, resoundingly, is Retrieval-Augmented Generation (RAG).
RAG has graduated from a clever "hack" to the central architectural pillar of enterprise AI. It addresses the fundamental "parametric memory" limitation of LLMs. A model like GPT-4o or Claude 3.5 Sonnet is essentially a frozen snapshot of the internet at a specific point in time. It knows everything about the Battle of Hastings but nothing about the Q4 sales report you generated this morning. It can write Python code, but it cannot cite your company's internal security compliance standards.
RAG bridges this gap by dynamically injecting relevant context into the model's inference window, grounding its creative power in your specific, verifiable facts. It transforms the LLM from a "Know-It-All" into a "Know-Where-To-Look" engine.
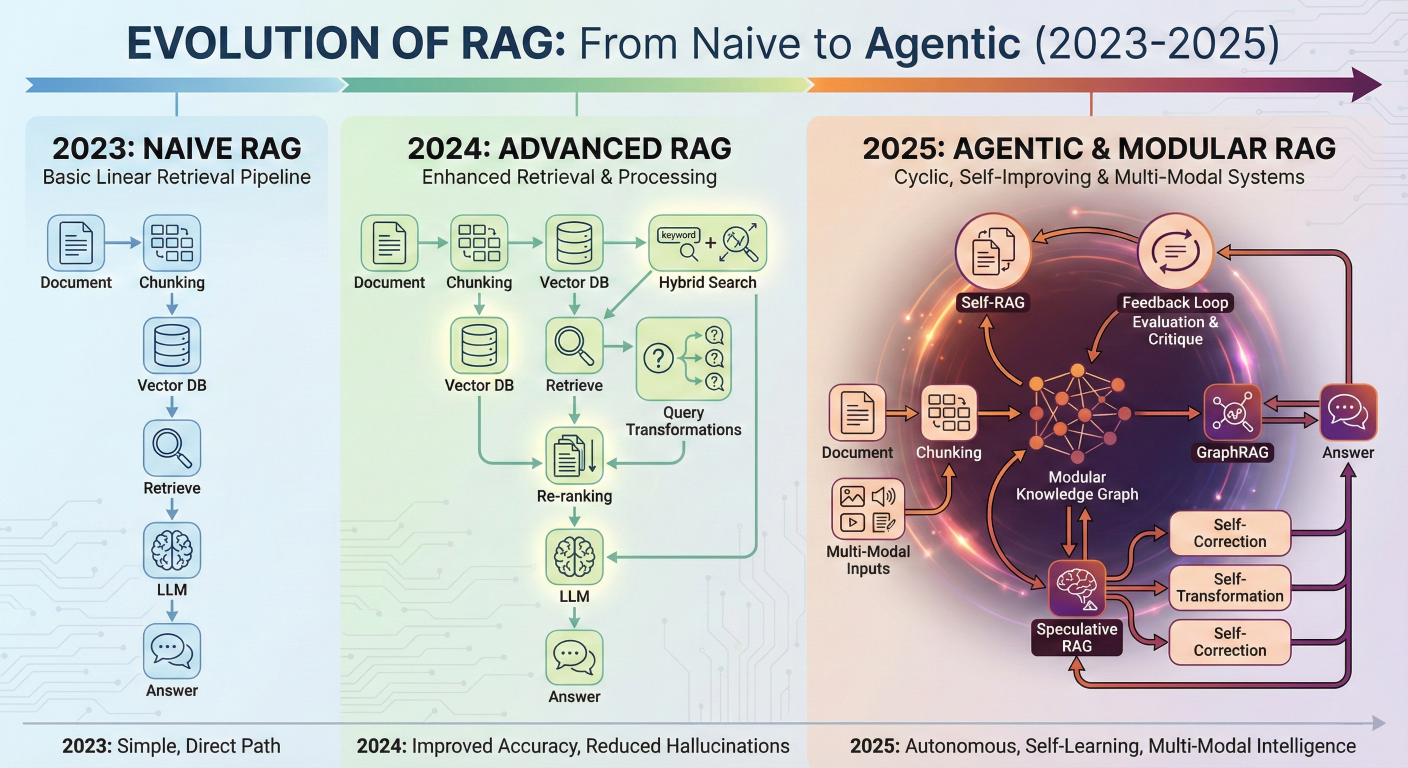
Detailed description about picture/Architecture/Diagram: A comprehensive timeline and evolutionary diagram of RAG. The left side shows "2023: Naive RAG" with a simple linear path (Document -> Chunk -> Vector DB -> Retrieve -> LLM). The center shows "2024: Advanced RAG" introducing Re-ranking, Query Transformations, and Hybrid Search. The right side shows "2025: Agentic & Modular RAG" featuring a cyclic graph with Feedback Loops, Self-Correction, Knowledge Graphs, and Multi-Modal inputs, labeled with terms like "Self-RAG," "GraphRAG," and "Speculative RAG."
A persistent question in the developer community remains: "Why shouldn't I just fine-tune the model on my data?" It is an intuitive thought—if the model learns from data, teaching it my data should work, right? In 2025, the industry consensus is heavily weighted toward RAG for knowledge retrieval, reserving fine-tuning for behavioral adaptation.
To understand this, we must look at the mechanics of how models store information. Fine-tuning adjusts the weights of the neural network. It "bakes" information into the model's fuzzy parametric memory. RAG, conversely, provides an "open-book" exam setting where the model has access to the source text.
| Feature | RAG(Retrieval-Augmented Generation) | Fine-Tuning | Prompt Engineering |
Primary Mechanism | Connects LLM to external databases to retrieve context at query time. The model "reads" the data before answering. | Retrains the model on a specific dataset to adjust internal weights. The model "memorizes" the data. | Optimizes input instructions to guide model behavior without training. |
Knowledge Updates | Instant. Add a document to the vector DB, and the system knows it immediately. | Slow. Requires compiling a dataset and running a computationally expensive training job. | None. Limited to what fits in the context window and model's training data. |
Hallucination Control |
High. The model is grounded in retrieved evidence, which can be cited directly. | Low/Variable. The model may "forget" facts or conflate them (catastrophic forgetting). | Low. Dependent entirely on the model's internal training. |
Data Privacy | High. Sensitive data stays in your database; only relevant chunks are sent to the LLM. Access controls are easier to enforce. | Low. Private data becomes part of the model, making it difficult to control access or "unlearn". | Moderate. Data is sent to the model but not retained for training (usually). |
Cost Profile | OpEx Heavy. Costs are driven by storage and per-query retrieval/inference. | OpEx Heavy. Costs are driven by storage and per-query retrieval/inference. | Low. Only inference costs, but requires manual effort. |
Best Use Case | Querying dynamic, large-scale, or proprietary knowledge bases (e.g., legal docs, customer support). | Adapting tone, style, format, or specialized languages (e.g., medical terminology, code styles). | Prototyping, testing, and simple tasks. |
The hybrid approach is often the gold standard: use Fine-Tuning to teach the model how to speak (e.g., "Act as a senior legal analyst"), and use RAG to tell it what to speak about (e.g., "Here is the contract from 2024").
We are currently witnessing the third generation of RAG architectures.
To build a robust RAG system, we must treat it as a data engineering challenge first and an AI challenge second. The quality of your retrieval is strictly capped by the quality of your data ingestion and indexing.
Before vectors exist, we have documents. In the enterprise, these are rarely clean text files. They are PDFs with multi-column layouts, PowerPoints with embedded charts, and Excel sheets with critical financial data.
The "Garbage In, Garbage Out" Reality If your parser reads a PDF and merges a header from page 1 with a footer from page 2, your chunk will be nonsensical. Modern parsers like LlamaParse or Unstructured.io use vision-based models to "see" the document layout. They identify that a table is a table, not just a stream of text.
Chunking is the process of breaking large documents into smaller pieces that fit into the LLM's context window. It seems trivial, but it is one of the highest-leverage hyperparameters in RAG.
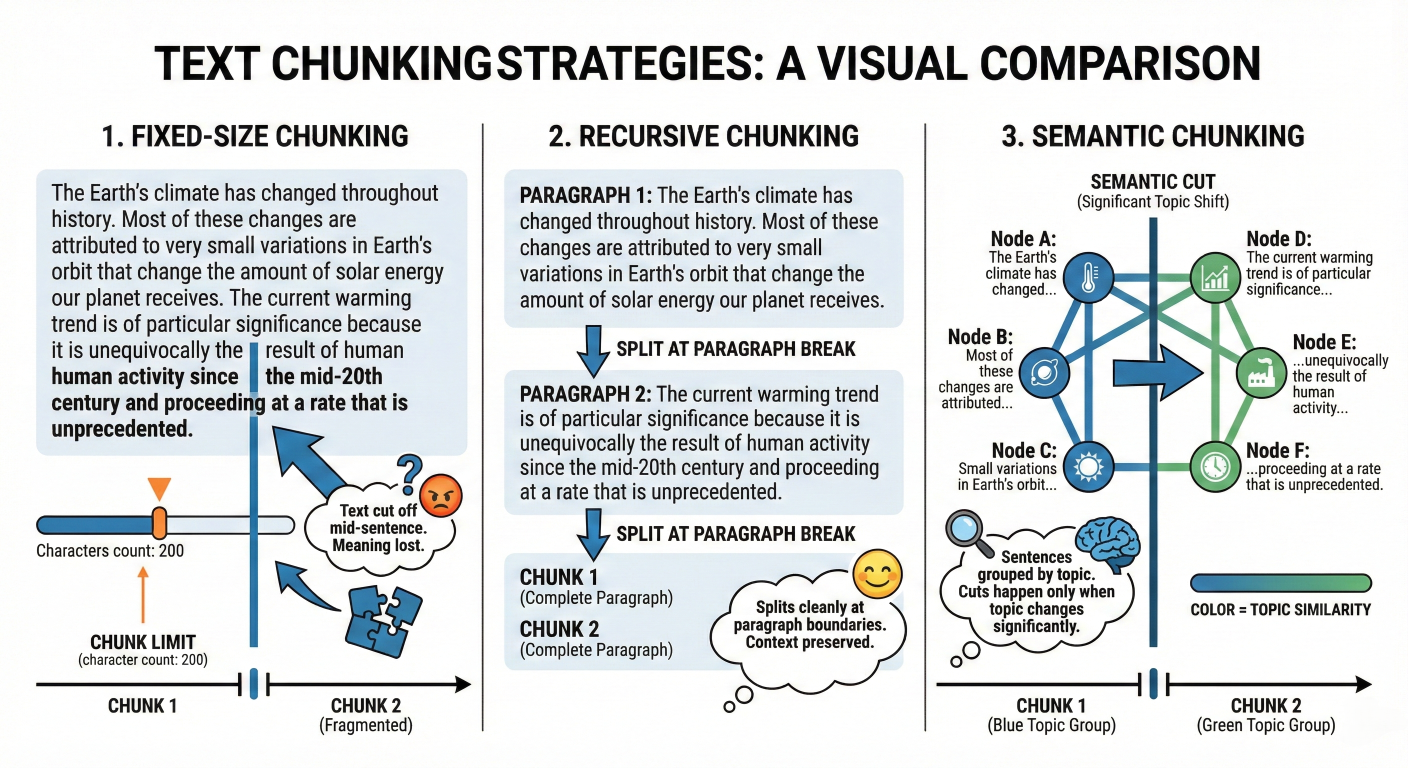
Fixed-Size Chunking
The simplest approach. You slice text every $N$ characters or tokens (e.g., 512 tokens) with an overlap (e.g., 50 tokens).
Recursive Character Chunking
The industry standard for generic text. It attempts to split hierarchically: first by paragraphs (\n\n), then by newlines (\n), then by sentences (.), and finally by words.
Semantic Chunking
A more advanced method for 2025. Instead of relying on punctuation, it uses an embedding model to measure the semantic similarity between sequential sentences.
Agentic / Propositional Chunking
This is the cutting edge. It uses an LLM to rewrite the text into atomic "propositions"—standalone statements of fact—before embedding.
Once chunked, data is passed through an embedding model (like OpenAI's text-embedding-3 or open-source equivalents like bge-m3) to create vectors. These vectors are stored in a Vector Database (Vector DB).
HNSW vs. IVF: The Indexing Wars
When configuring a Vector DB (like Pinecone, Milvus, or Weaviate), you typically choose between two indexing algorithms: HNSW and IVF. Understanding the difference is critical for production performance.
HNSW (Hierarchical Navigable Small World)
Comparison of Vector Indexing Algorithms
Feature |
HNSW (Hierarchical Navigable Small World) |
IVF (Inverted File Index) |
Search Speed | Extremely Fast (0.6 - 2.1 ms) | Fast (1 - 9 ms) |
Memory Usage | High (Graph overhead) | High (Graph overhead) |
Recall (Accuracy) | Excellent (0.95+) | Good (0.7 - 0.95) |
Scalability | Good for <100M vectors | Excellent for >100M vectors |
Best For |
Real-time apps, high accuracy needs |
Massive scale, cost optimization |
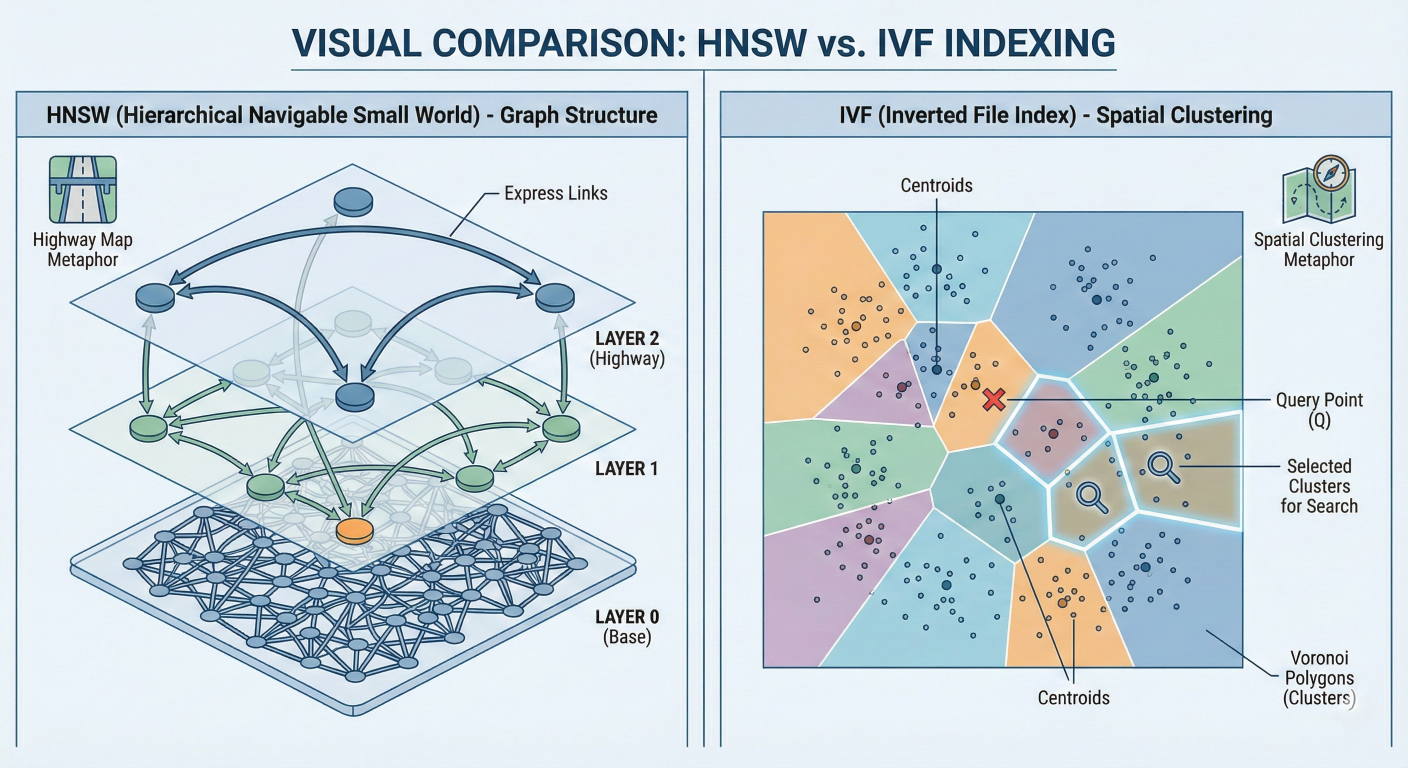
Detailed description about picture/Architecture/Diagram: Visual comparison of HNSW vs IVF. HNSW is depicted as a multi-layered graph structure with "express links" on top layers and dense connections on the bottom layer, resembling a highway map. IVF is depicted as a 2D space divided into Voronoi polygons (clusters) with a query point highlighting specific cells to search.
In 2023, we relied on "Dense Retrieval"—matching the query vector to document vectors. In 2025, we know this is insufficient. Dense vectors capture semantic meaning ("dog" matches "canine"), but they often fail at exact keyword matching ("Error code 543" might not match "Issue 543" if the embedding model wasn't trained on those specific tokens).
Hybrid Search: The Industry Standard
Hybrid search combines two retrieval methods:
Where r(d) is the rank of document d in one of the retrieval lists (e.g., the vector list or the keyword list), and k is a constant (usually 60). This formula ensures that a document appearing in both lists gets a significantly higher score than a document appearing at the top of only one list.
Re-Ranking: The Quality Filter
Retrieving the top 100 documents is fast (milliseconds). But feeding 100 documents to an LLM is expensive and confusing. We need a filter. Enter the Cross-Encoder Re-ranker (e.g., Cohere Rerank, BGE-Reranker).
Once you have mastered the basics, you will encounter edge cases where simple RAG fails. This is where advanced patterns come into play.
2.1 Parent Document Retrieval (Small-to-Big)A fundamental tension in RAG is chunk size.
2.2 Query Transformations
Users often write poor queries. "Wi-Fi broken" is a terrible query for a technical manual. Query transformations use an LLM to rewrite the user's intent before it hits the vector database.
Multi-Query Retrieval
The system generates variations of the user's question to cast a wider net.
2.3 GraphRAG: Structuring the Unstructured
One of the most significant advancements in 2025 is GraphRAG. Standard Vector RAG treats documents as a bag of isolated vectors. It struggles with "global" questions like * "How do the themes in Document A relate to the conclusions in Document B?"*
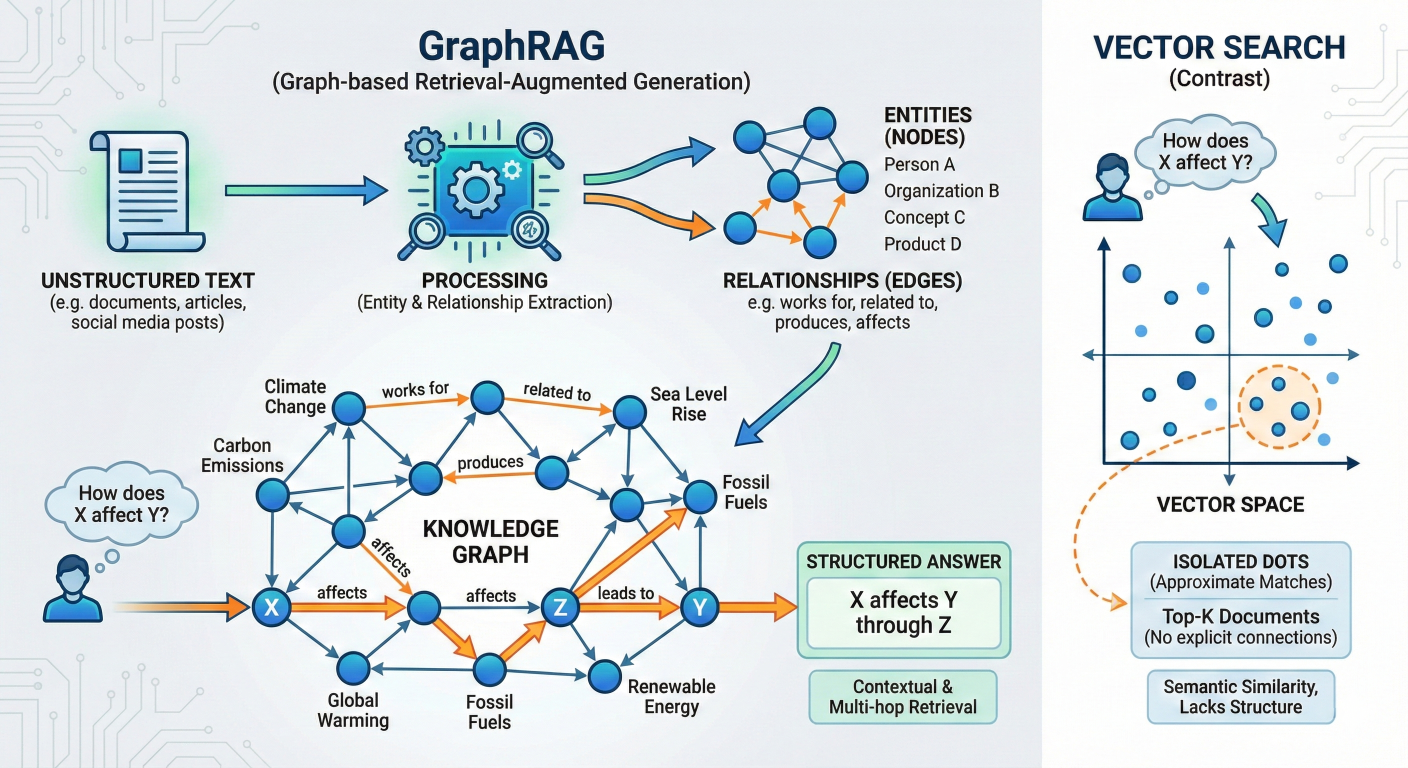
<--- Detailed description about picture/Architecture/Diagram: Diagram of GraphRAG. It shows unstructured text being processed into "Entities" (Nodes) and "Relationships" (Edges) to form a Knowledge Graph. A user query "How does X affect Y?" is shown traversing the edges of the graph to find the answer, contrasting with a Vector Search which just finds isolated dots in a 2D space. --->
GraphRAG combines Knowledge Graphs (KG) with LLMs.
When to use GraphRAG?
2.4 RAPTOR (Recursive Abstractive Processing for Tree-Organized Retrieval)
RAPTOR is designed for long-context question answering where the answer spans multiple parts of a document.
We are moving away from linear chains (Step A -> Step B -> Step C) toward Agentic Workflows (Loops, Conditionals, Decision Making).
3.1 Self-RAG (Self-Reflective RAG)
Self-RAG adds a "Critic" to the loop. It is a framework where the model learns to critique its own retrieval and generation. It introduces Reflection Tokens:
Retrieve: The model decides if it needs to retrieve. If the user asks "Hi", it skips retrieval. If they ask "Explain the 2025 tax code", it triggers retrieval.IsRel (Is Relevant): After retrieving, the model grades the document. "Is this actually relevant to the query?"IsSup (Is Supported): After generating an answer, the model checks, "Is this sentence supported by the retrieved document?"IsUse (Is Useful): "Is this a helpful answer?"IsRel score is low, the agent can loop back and re-write the search query. This "active" participation significantly reduces hallucinations.3.2 Corrective RAG (CRAG)
CRAG focuses specifically on the quality of retrieved documents.
3.3 Speculative RAG
This architecture optimizes for both speed and accuracy using a "Drafter-Verifier" approach.
3.4 MemoRAG (Memory-Augmented)
Standard RAG is stateless; it forgets the previous query instantly. MemoRAG introduces a global memory module.
Let's transition from theory to code. We will compare the two dominant frameworks: LangChain and LlamaIndex, and implement advanced features.
4.1 LangChain: The Composable Builder
LangChain is famous for its "Lego block" philosophy. In 2025, the standard way to write LangChain is using LCEL (LangChain Expression Language), a declarative way to pipe components together.
Code Example: A Modern LangChain RAG Pipeline with Hybrid Search and Re-ranking
import os
# Ensure you have 'langchain', 'langchain-openai', 'faiss-cpu', 'rank_bm25', 'cohere' installed
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_community.retrievers import BM25Retriever
from langchain.retrievers import EnsembleRetriever, ContextualCompressionRetriever
from langchain.retrievers.document_compressors import CohereRerank
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_core.prompts import ChatPromptTemplate
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 1. Setup Environment & Models
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
llm = ChatOpenAI(model="gpt-4o", temperature=0)
# 2. Ingestion & Chunking
raw_text = """
RAG (Retrieval-Augmented Generation) allows LLMs to access private data.
It consists of Retrieval, Augmentation, and Generation.
In 2025, Agentic RAG is the standard.
"""
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
docs = splitter.create_documents([raw_text])
# 3. Hybrid Retrieval Setup
vectorstore = FAISS.from_documents(docs, embeddings)
vector_retriever = vectorstore.as_retriever(search_kwargs={"k": 5})
bm25_retriever = BM25Retriever.from_documents(docs)
bm25_retriever.k = 5
ensemble_retriever = EnsembleRetriever(
retrievers=[bm25_retriever, vector_retriever],
weights=[0.5, 0.5]
)
# 4. Re-ranking
compressor = CohereRerank(model="rerank-english-v3.0", top_n=3)
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor,
base_retriever=ensemble_retriever
)
# 5. The Chain (LCEL)
template = """Answer the question based ONLY on the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
def format_docs(documents):
return "\n\n".join([d.page_content for d in documents])
rag_chain = (
{"context": compression_retriever | format_docs,
"question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
# 6. Execution
try:
response = rag_chain.invoke("What is the standard in 2025?")
print(f"Response: {response}")
except Exception as e:
print(f"Error executing chain: {e}") Why Choose LlamaIndex? LlamaIndex excels at handling hierarchical data. It has native support for "Index Composition"—building an index of indices (e.g., a Summary Index for each document, and a Vector Index for the summaries). This is powerful for complex document sets.
4.3 Implementing Multi-Query Retrieval (LangChain)
To implement the Multi-Query pattern discussed earlier, we wrap the base retriever.
from langchain.retrievers.multi_query import MultiQueryRetriever
import logging
# Enable logging to visualize the generated queries
logging.basicConfig()
logging.getLogger("langchain.retrievers.multi_query").setLevel(logging.INFO)
# Create the Multi-Query Retriever
# It uses the LLM to generate 3 variations of the question
multi_query_retriever = MultiQueryRetriever.from_llm(
retriever=vectorstore.as_retriever(),
llm=llm
)
# Execution
# The logs will show the LLM generating 3 variations of the question
unique_docs = multi_query_retriever.invoke("How do I fix network errors?")
print(f"Retrieved {len(unique_docs)} unique documents.")
This simple addition effectively "automates" prompt engineering for the retrieval step, making the system robust against vague user inputs.
Key RAG Metrics
| Metric |
Definition | Question It Answers |
| Faithfulness |
Measures if the answer is derived only from the retrieved context. | "Is the bot hallucinating information not present in the docs?" |
| Answer Relevance | Measures how relevant the answer is to the user's original query. | "Did the bot actually answer the question, or did it just ramble?" |
| Context Precision | Measures the signal-to-noise ratio in the retrieved chunks. | "Is the relevant information ranked at the top, or is it buried?" |
| Context Recall | Measures if the retrieved context contains the ground truth answer. | "Did the retriever find the necessary facts at all?" |
Ragas Implementation Code
from ragas import evaluate
from ragas.metrics import faithfulness, answer_relevancy, context_precision, context_recall
from datasets import Dataset
# 1. Prepare Data
# In production, you would collect these lists from your application logs
data_samples = {
'question':,
'answer':,
'contexts':,
,
'ground_truth':
}
dataset = Dataset.from_dict(data_samples)
# 2. Run Evaluation
results = evaluate(
dataset=dataset,
metrics=[faithfulness, answer_relevancy, context_precision, context_recall],
)
# 3. Analyze Results
print(results)
# Output Example: {'faithfulness': 0.98, 'answer_relevancy': 0.92,...}
df = results.to_pandas()
df.to_csv("rag_evaluation_report.csv") This pipeline allows you to practice Test-Driven Development (TDD) for AI. If you change your chunk size from 500 to 1000, run the eval. If Context Precision drops, you know the larger chunks introduced too much noise. This data-driven approach is the only way to optimize systematically.
Building a RAG demo in a notebook is easy. Deploying it to 10,000 users is a war zone. Here are the critical challenges and solutions for production RAG in 2025.
6.1 The Cost of RAGRAG is operationally expensive.
Optimization Strategies:
6.2 Latency Kills
Users expect chat interfaces to be instant.
6.3 The "Lost in the Middle" Phenomenon
Research has shown that LLMs are biased towards information at the beginning and end of the context window. Information buried in the middle is often ignored.
As we look toward the latter half of 2025 and into 2026, the line between "Model" and "Retrieval" is blurring. With the rise of "Long Context" models (like Gemini 1.5 Pro supporting 1M+ tokens), some argue RAG is dead—just paste the whole database into the prompt!
However, RAG is not dead; it is evolving. Even with a 1M token window, filling it is slow and expensive. RAG will remain the efficient "pre-filter" that selects the most relevant 1% of data to feed the model. Furthermore, Agentic RAG—where the model can actively browse, verify, and correct its own research—is unlocking capabilities we are only beginning to understand.
Call to Action: The theory is vast, but mastery comes from practice.
 Launch your Graphy
Launch your Graphy