There are no items in your cart
Add More
Add More
| Item Details | Price | ||
|---|---|---|---|

If you have spent any time building applications with Large Language Models (LLMs), you have likely experienced the "magic moment." You write a prompt, maybe hook it up to a vector database, and ask a question. The model spits out a coherent, beautifully written answer. You show it to your boss or your client, and everyone is impressed. It feels like magic.
But then, the magic starts to fade.
You deploy the chatbot to a few beta testers. Suddenly, reports start trickling in. Your customer support bot promised a user a 50% discount that doesn't exist. Your internal legal tool cited a court case that was overruled in 1995—or worse, one that never existed at all. Your code generator imported a Python library that was deprecated three years ago.
You realize, with a sinking feeling, that you don't actually know how good your model is. You know it can work, but you don't know how often it works.
Welcome to the world of Model Evaluation in Generative AI.
In traditional software engineering, we have unit tests. assert 2 + 2 == 4. It either passes, or it fails. In traditional Machine Learning, we had ground truth labels. The image is either a cat, or it isn't. We calculated Accuracy, Precision, Recall, and F1-Score, and we went home happy.
Generative AI is different. It is nondeterministic. You can ask the same question twice and get two different answers. It is creative, meaning there isn't always one right answer. How do you evaluate a poem? How do you score a summary? How do you measure if a chat response was "helpful" or just "polite but useless"?
In this comprehensive guide, we are going to demystify the entire landscape of Generative AI evaluation. We are moving past the surface-level tutorials. We will dive deep into the history of metrics, the modern "LLM-as-a-Judge" paradigm, the specific architectures for evaluating Retrieval-Augmented Generation (RAG), and the code-heavy frameworks that make it all possible.
Grab a coffee. We have a lot of ground to cover.
To understand where we are going, we need to understand where we came from. The history of Natural Language Processing (NLP) evaluation is a story of trying to translate human intuition into mathematical formulas. We have moved through three distinct eras: the N-Gram Era, the Embedding Era, and now, the Generative Era.
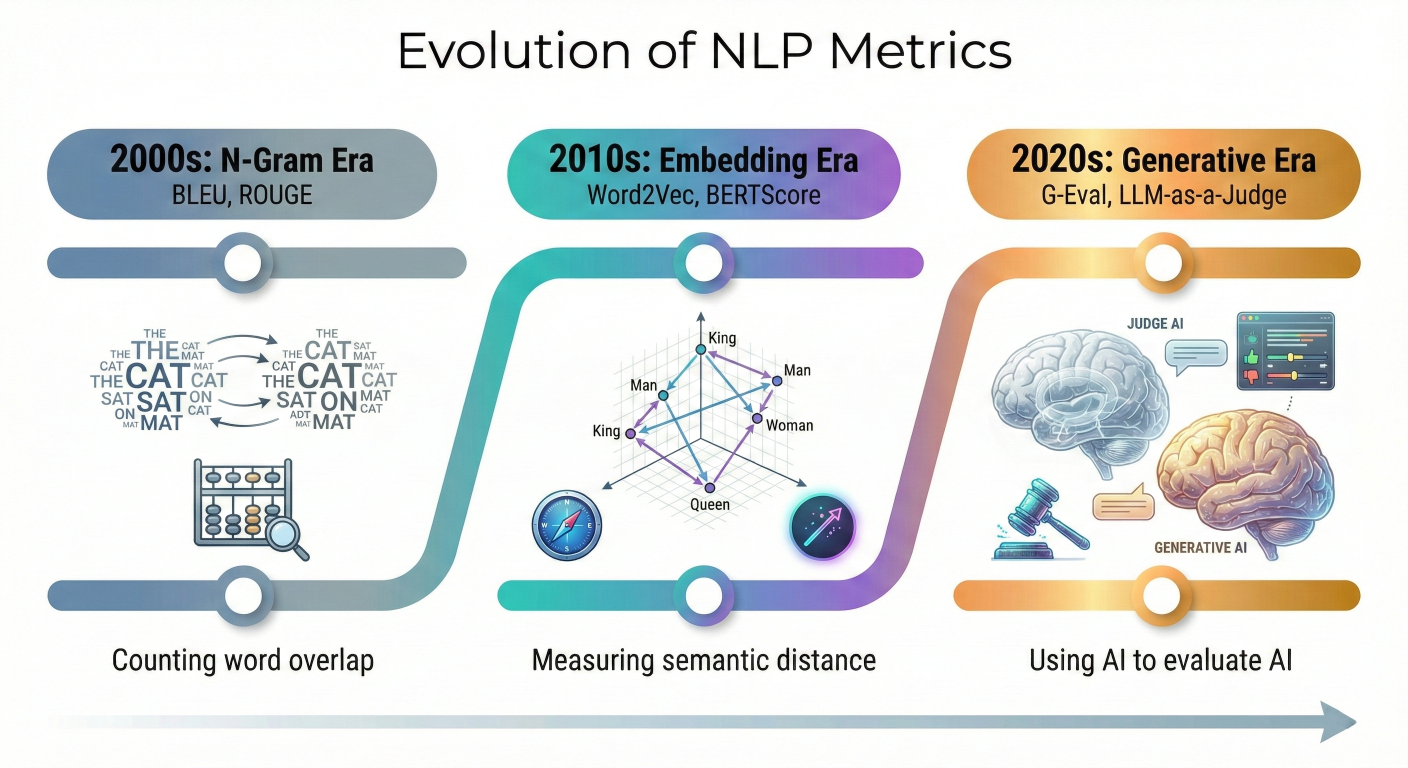
A horizontal timeline showing the evolution of NLP metrics. Left side: "2000s: N-Gram Era (BLEU, ROUGE) - Counting word overlap". Middle: "2010s: Embedding Era (Word2Vec, BERTScore) - Measuring semantic distance". Right: "2020s: Generative Era (G-Eval, LLM-as-a-Judge) - Using AI to evaluate AI".
1.1 The N-Gram Era: Counting Words (BLEU and ROUGE)
In the early days of machine translation and automatic summarization, researchers needed a way to check if a machine's output was "good" without having a human read every single sentence. The solution was simple: compare the machine's text to a human-written "reference" text and count how many words overlapped.
BLEU (Bilingual Evaluation Understudy)
BLEU was the king of translation metrics. It asks a specific question: How precise is the machine's output?Technically, BLEU calculates the precision of n-grams (sequences of n words).
Why it fails for Generative AI:
To a human, these sentences mean the same thing. To BLEU, they are completely different. There is almost zero word overlap. BLEU punishes creativity and synonym usage, which is exactly what modern LLMs are good at.
ROUGE (Recall-Oriented Understudy for Gisting Evaluation)
If BLEU is about precision (did I say anything wrong?), ROUGE is about recall (did I miss anything?). It became the standard for summarization tasks.
Example:
1.2 The Semantic Era: Vectors and Embeddings (BERTScore)
As Deep Learning took over, we stopped treating words as just strings of characters. We started treating them as vectors—lists of numbers that represent the meaning of the word in a high-dimensional space.
BERTScore was a revolution. Instead of matching exact words, it uses a pre-trained BERT model to convert every word in the generated text and the reference text into embeddings. It then calculates the cosine similarity between these embeddings.
Why this is better:
In our previous example ("cat" vs. "feline"), a vector model knows that these two words are semantically close. They appear in similar contexts in the training data. Therefore, their vectors will be close together in space, and BERTScore will return a high similarity score, even though the words are different.
1.3 The Generative Era: Model-Based Evaluation
We eventually realized that the best system to evaluate a Large Language Model is... another Large Language Model.
G-Eval (Generative Evaluation)
G-Eval is a framework that uses an LLM (like GPT-4) to evaluate the output of another LLM based on a prompt-based rubric. Instead of relying on math proxies, we simply ask the model to act as a human grader.
The concept of LLM-as-a-Judge is central to almost all modern evaluation frameworks. It is the engine that powers tools like Ragas and DeepEval. But it is not a magic bullet. It requires careful engineering and an understanding of its psychology.
2.1 How It Works
The workflow is surprisingly simple, yet powerful.
This enables Reference-Free Evaluation. You don't need a human-written "Gold Answer" to check if a response is polite, coherent, or even grounded in the context. You just need the Judge to analyze the relationship between the input and the output.
2.2 The Hidden Dangers: Biases in LLM Judges
However, LLM Judges are not neutral arbiters. They have personalities, preferences, and quirks inherited from their training data. We call these biases, and they can ruin your evaluation if you aren't careful.
Position Bias
Verbosity Bias
Self-Preference Bias
2.3 The Cost vs. Performance Trade-off
Using GPT-4 as a judge for every single user query in production is prohibitively expensive. It's slow and costs real money.
The Strategy: Cascading Evaluation You don't need a PhD-level judge for every question.
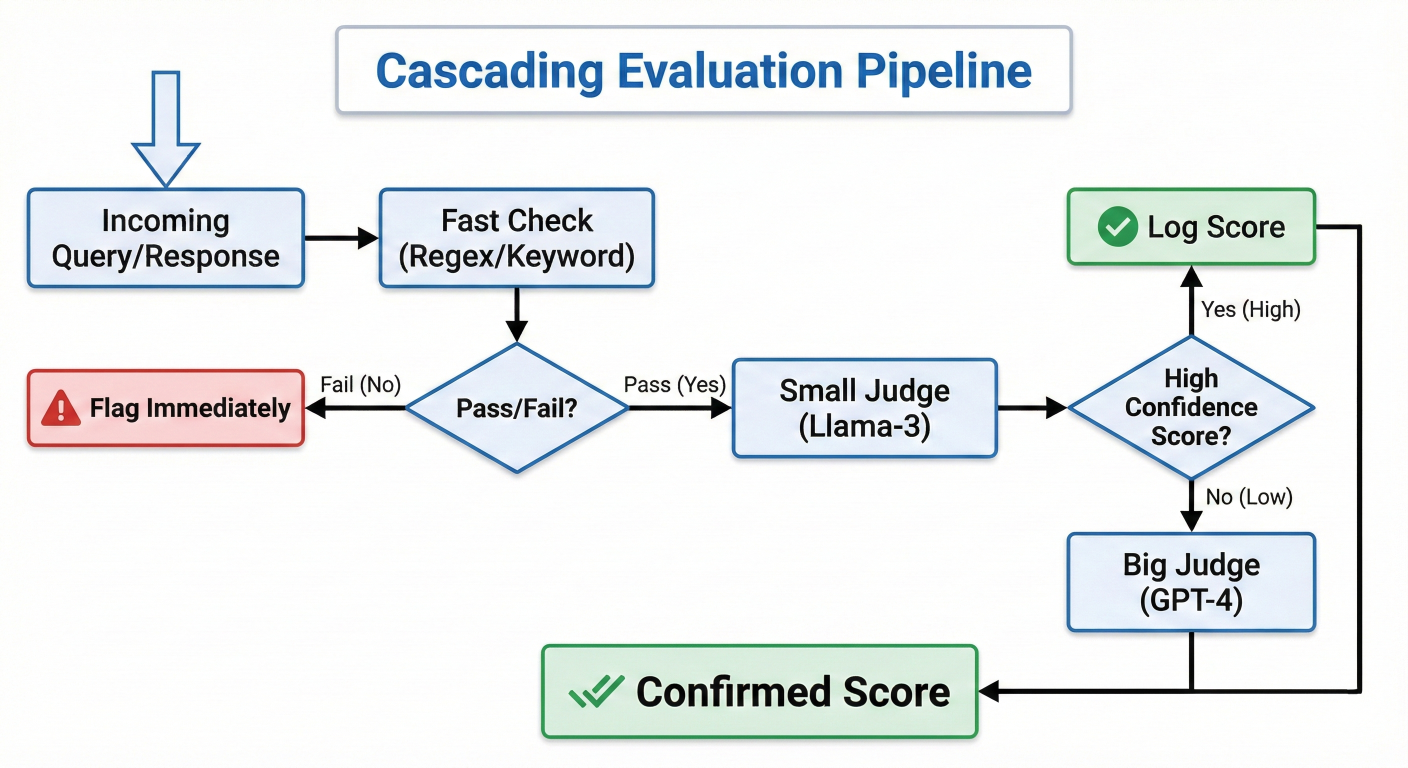
A flowchart showing a "Cascading Evaluation Pipeline". Step 1: Incoming Query/Response -> "Fast Check" (Regex/Keyword). Decision Diamond: Pass/Fail? If Fail -> Flag immediately. If Pass -> Step 2: "Small Judge" (Llama-3). Decision Diamond: High Confidence Score? If Yes -> Log Score. If No (Low Confidence) -> Step 3: "Big Judge" (GPT-4). Final Output: Confirmed Score.
Retrieval-Augmented Generation (RAG) has become the default architecture for enterprise AI. By connecting an LLM to your private data (PDFs, Databases, Wikis), you theoretically fix the "knowledge cutoff" problem.But RAG introduces a complex dependency chain. If your bot gives a wrong answer, whose fault is it?
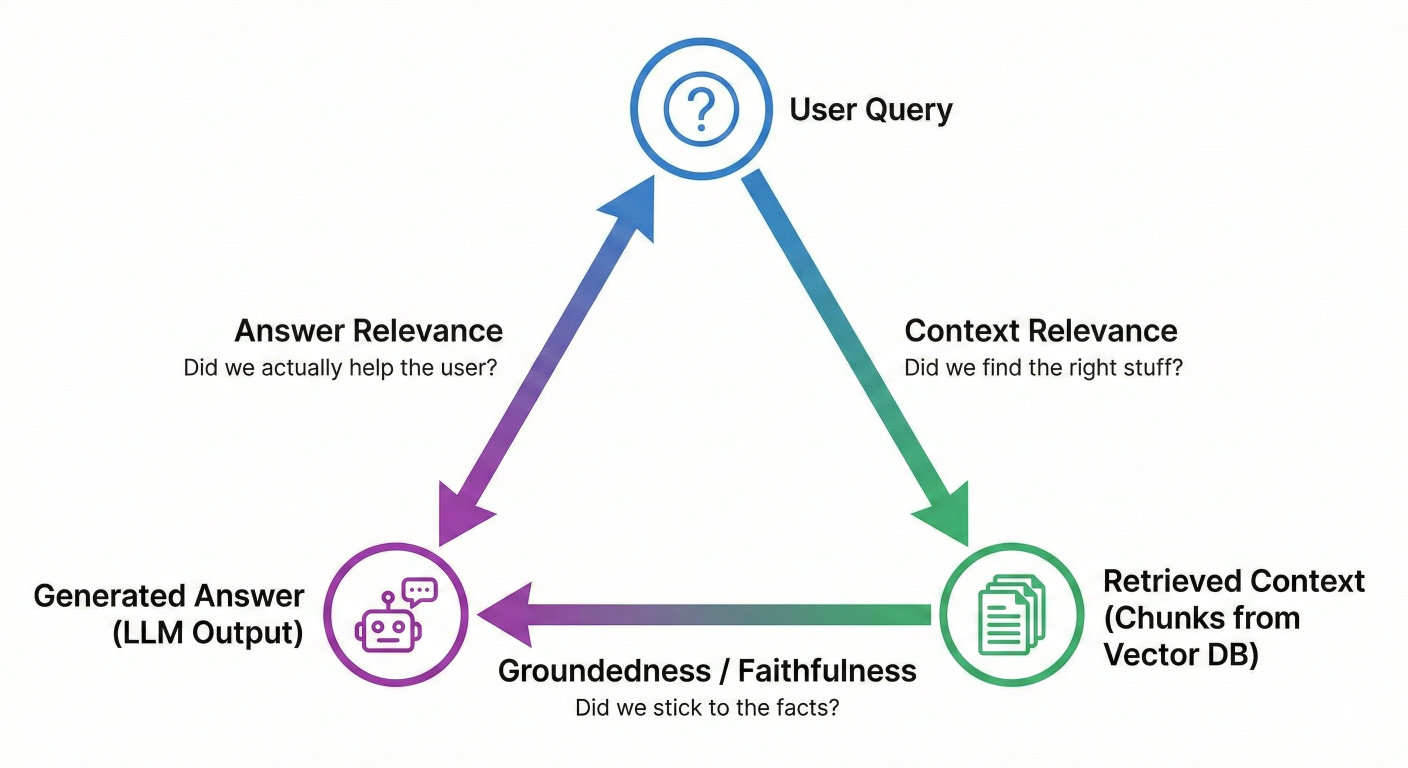
Description: A triangle diagram visualizing the RAG Triad. Top Vertex: "User Query". Bottom Right Vertex: "Retrieved Context" (The chunks from your vector DB). Bottom Left Vertex: "Generated Answer" (The LLM output). Edge 1 (Query -> Context): "Context Relevance" (Did we find the right stuff?). Edge 2 (Context -> Answer): "Groundedness / Faithfulness" (Did we stick to the facts?). Edge 3 (Query -> Answer): "Answer Relevance" (Did we actually help the user?).
3.1 Context Relevance (Retrieval Quality)
The Core Question: Did we find the documents that actually contain the answer?If a user asks "What is the company's vacation policy?", and your retriever pulls up documents about "Server Maintenance Protocols," the LLM has zero chance of answering correctly. No amount of prompt engineering can fix bad retrieval.Metrics to Watch:
LLM Implementation:
You pass the User Query and the Retrieved Chunks to a Judge. The Judge reads each chunk and rates it: "Does this chunk contain information relevant to the query?".
3.2 Groundedness (Faithfulness)
The Core Question: Is the answer derived only from the retrieved documents?
This is your primary defense against hallucinations. If the documents say "The revenue was $5M" and the LLM says "The revenue was $10M," groundedness is zero. Crucially, even if the LLM uses its external training knowledge to give a "factually correct" answer that isn't in your documents, it fails this check. In enterprise RAG, we want the model to be a faithful interpreter of our data, not a creative improviser.
How to measure it (The Algorithm):
3.3 Answer Relevance (Generation Quality)
The Core Question: Did we actually answer the user's specific question?A model can be perfectly grounded but completely useless.
You do not need to write these metrics from scratch. The Python ecosystem has exploded with libraries that implement the RAG Triad and LLM-as-a-Judge patterns out of the box.
Let's do a deep comparative analysis of the "Big Three": Ragas, DeepEval, and TruLens.
| Feature |
Ragas |
DeepEval | TruLens |
| Philosophy | Data-Centric: Focuses on generating synthetic test data and metrics. | Testing-Centric: Treats eval like software unit tests (Pytest). | Observability-Centric: Focuses on tracking apps in production. |
Key Metric Approach | RAG Triad (Faithfulness, Context Precision). | G-Eval (Rubrics), Hallucination Metric. | RAG Triad (Feedback Functions). |
Integration |
Strong integration with LangChain / LlamaIndex. |
Seamless integration with CI/CD pipelines. | Wraps your app to "record" traces. |
Synthetic Data | Best-in-class generator (Evolution strategies) | Good Synthesizer class | Basic |
Developer Experience | Feels like a data science tool. | Feels like a software testing tool. | Feels like a monitoring/logging tool. |
4.1 Ragas (Retrieval Augmented Generation Assessment)
Best For: Pure RAG pipeline evaluation and generating synthetic test data.
Ragas is famous for defining the modern RAG metrics. It is highly mathematical in its approach to "Context Precision" and "Context Recall."
Code Walkthrough: Evaluating with Ragas You need a dataset containing question, answer, contexts, and ground_truth.
# Import necessary modules
from ragas import evaluate
from ragas.metrics import (
faithfulness,
answer_relevancy,
context_precision,
context_recall,
)
from datasets import Dataset
# Imagine this data comes from your RAG pipeline logs
data = {
'question': ['How do I reset my password?'],
'answer': ['Go to settings and click reset.'],
'contexts': [],
'ground_truth': ['Navigate to settings > security > reset password.']
}
# Convert to HuggingFace Dataset format
dataset = Dataset.from_dict(data)
# Run the evaluation
results = evaluate(
dataset=dataset,
metrics=[
faithfulness,
answer_relevancy,
context_precision,
context_recall
],
)
# Print the scores (returns a dictionary of scores 0.0 - 1.0)
print(results)
# Output Example: {'faithfulness': 0.92, 'answer_relevancy': 0.85,...} Note: To use context_recall, you strictly need a ground truth reference. faithfulness and answer_relevancy can work without it..
4.2 DeepEval
Best For: Unit Testing and CI/CD Integration.
DeepEval (by Confident AI) is built for developers who love TDD (Test Driven Development). It integrates directly with Pytest. This allows you to "fail the build" if your LLM performance drops, preventing bad models from ever reaching production.
Code Walkthrough: Pytest Integration
import pytest
from deepeval import assert_test
from deepeval.metrics import HallucinationMetric
from deepeval.test_case import LLMTestCase
def test_hallucination():
# Define the test case (Input, Actual Output, Retrieved Context)
test_case = LLMTestCase(
input="Who won the 2024 Super Bowl?",
actual_output="The Kansas City Chiefs won.",
context=
)
# Initialize the metric (Minimum score threshold = 0.7)
# This means we demand at least 70% faithfulness
metric = HallucinationMetric(minimum_score=0.7)
# Run the assertion
# If the metric score is < 0.7, this line raises an error and fails the test
assert_test(test_case, [metric])
# Run this in your terminal:
# pytest test_eval.py
This paradigm shift—treating prompt engineering like software engineering—is crucial for scaling AI teams.
4.3 TruLens
Best For: Experiment Tracking and Observability.
TruLens (by TruEra) works differently. Instead of running a separate test script, you wrap your existing RAG application (built with LangChain or LlamaIndex) with a TruChain or TruLlama recorder. It watches your app run, logs the data, and runs "Feedback Functions" (evaluations) in the background.
from trulens.core import Feedback, TruSession
from trulens.providers.openai import OpenAI
# 1. Define the Feedback Provider (The Judge)
provider = OpenAI()
# 2. Define the Metric (Groundedness)
f_groundedness = (
Feedback(provider.groundedness_measure_with_cot_reasons)
.on_context()
.on_output()
)
# 3. Wrap your app
tru = TruSession()
# 'my_rag_app' is your existing LlamaIndex or LangChain app
with tru.TruCustomApp(my_rag_app, feedbacks=[f_groundedness]) as recording:
# Run your app as normal
response = my_rag_app.query("What is the refund policy?")
# 4. View results in the Dashboard
# This launches a Streamlit app to visualize your performance over time
tru.run_dashboard() TruLens is excellent for comparing different versions of your app (e.g., "Chunk Size 512" vs. "Chunk Size 1024") on a leaderboard.
One of the biggest blockers beginners face is: "I don't have a test set."
You have 1,000 documents, but you don't have 1,000 Question-Answer pairs to test your bot against. Writing them manually would take weeks of expensive subject-matter expert time.
Enter Synthetic Data Generation.
You can use an LLM to read your documents and generate the test cases for you. This solves the "Cold Start" problem in evaluation.
5.1 How It Works (Evolutionary Generation)
Frameworks like Ragas don't just ask "Write a question about this text." That produces boring, easy questions. Instead, they use Evolution Strategies.
5.2 Implementation Example
Here is how you generate a test set using Ragas or DeepEval's synthesizer:
from ragas.testset.generator import TestsetGenerator
from ragas.testset.evolutions import simple, reasoning, multi_context
from langchain_openai import ChatOpenAI
# Load your documents
documents = loader.load() # Assume standard LangChain loader
# Initialize the Generator with specific models for generation vs criticism
generator = TestsetGenerator.with_openai()
# Generate the data
testset = generator.generate_with_langchain_docs(
documents,
test_size=50, # Generate 50 Q/A pairs
distributions={
simple: 0.5, # 50% easy questions
reasoning: 0.25, # 25% requires logic
multi_context: 0.25 # 25% requires combining info from multiple docs
}
)
# Export to Pandas
df = testset.to_pandas()
df.to_csv("my_synthetic_gold_dataset.csv") Now you have a benchmark dataset to run evaluate() against every time you change your prompt or retrieval settings.
Metrics give you a score, but they don't tell you the nature of your failure. In production, certain failures are annoying (verbosity), while others are catastrophic (hallucinations, toxicity).
6.1 The Taxonomy of Hallucination
Not all wrong answers are created equal.
6.2 Red Teaming and Adversarial Evaluation
You cannot wait for users to break your model. You must break it yourself first. This is called Red Teaming.
You need a dataset of Adversarial Prompts designed to trigger failure modes:
Evaluation is no longer an afterthought; it is the backbone of Generative AI engineering. If you cannot measure it, you cannot improve it.
We have come a long way from counting word overlaps with BLEU. We now have sophisticated LLM-as-a-Judge systems that can reason about nuance, tone, and groundedness. We have the RAG Triad to diagnose retrieval vs. generation failures. And we have powerful open-source frameworks like Ragas, DeepEval, and TruLens to automate the entire process.
Your Call to Action:
ragas or deepeval today. Experiment with one.Generative AI is powerful, but power without control is chaos. Evaluation is your control. Go build something robust.

{{AUTHOR}}
 Launch your Graphy
Launch your Graphy