There are no items in your cart
Add More
Add More
| Item Details | Price | ||
|---|---|---|---|

Executive Summary: Model Control Plane (MCP) represents the evolution of AI infrastructure from single-model applications to scalable, governed, multi-agent systems. In the GenAI landscape, MCP serves two critical functions: as a centralized orchestration layer for managing model lifecycle, routing, policies, and cost optimization; and as a standardized protocol for connecting AI agents to external tools and data sources. This comprehensive guide explores both aspects, providing detailed architectural blueprints, implementation strategies, security frameworks, and real-world deployment examples for enterprise teams ready to scale their AI operations beyond proof-of-concept.
The acronym "MCP" has evolved to represent two complementary but distinct concepts that together form the backbone of enterprise AI infrastructure. Understanding both definitions is crucial for architects and engineers building production-grade AI systems.
Model Control Plane emerges as the governance and orchestration layer for AI models and agents across distributed environments. Think of it as "Kubernetes for AI models" - it provides centralized management for routing requests to appropriate models, enforcing access policies, managing costs, and ensuring compliance across multi-cloud deployments. The control plane separates policy decisions from execution, enabling teams to govern fleets of models without directly managing the underlying inference infrastructure.
Model Context Protocol represents a standardized communication interface developed by Anthropic that enables AI applications to connect securely to external tools, databases, and services. Often described as "USB-C for AI applications," MCP defines how agents discover, authenticate with, and invoke external capabilities through a consistent JSON-RPC interface. This protocol standardization eliminates the need for custom integrations with each tool or data source.
The power emerges when these concepts work together. The Control Plane governs which models execute under what policies, while the Context Protocol standardizes how those models access the tools and data they need to complete tasks. This separation of concerns enables modular, scalable AI architectures that can evolve without requiring extensive refactoring.
The shift from experimental AI to production systems has revealed critical gaps in traditional architectures. Organizations deploying generative AI at scale encounter challenges that simple API calls to language models cannot address effectively.
Operational Complexity at Scale: Modern AI applications require coordination between multiple models, each with different capabilities, costs, and latency profiles. A customer service system might route simple queries to cost-effective models while escalating complex requests to premium endpoints. Managing this complexity manually becomes unsustainable as usage grows.
Governance and Compliance Requirements: Enterprise deployments must enforce data access policies, maintain audit trails, and comply with regulations like GDPR or HIPAA. Traditional pointto-point integrations make it difficult to ensure consistent policy enforcement across all AI interactions. A centralized control plane provides the governance layer necessary for regulated industries.
Cost Management and Optimization: Token costs, infrastructure expenses, and model licensing fees can quickly spiral out of control without proper governance. Organizations need intelligent routing that considers cost alongside performance, automatic budget enforcement, and detailed usage analytics. The control plane enables policy-driven cost optimization that adapts to changing usage patterns.
Multi-Agent Coordination: Advanced AI applications increasingly rely on specialized agents working together. A financial analysis system might coordinate between data retrieval agents, calculation agents, and report generation agents. This requires standardized communication protocols and centralized orchestration to manage agent interactions effectively.
Security and Access Control: AI systems often require access to sensitive enterprise data and powerful external tools. Without proper security frameworks, a compromised AI agent could potentially access all connected systems. MCP architectures provide the security boundaries and access controls necessary for safe AI deployment.
Block (formerly Square) provides a compelling example of MCP deployment at enterprise scale. Their internal AI agent "Goose" demonstrates how MCP architecture delivers tangible business value across multiple teams and use cases.
Architecture: Block built custom MCP servers connecting to their internal tools including Snowflake, Jira, Slack, Google Drive, and task-specific APIs. Rather than using third-party MCP servers, they maintained complete control over security and customization by developing all integrations in-house.
Business Impact: The implementation resulted in up to 75% reduction in time spent on daily engineering tasks across thousands of employees. Engineering teams use MCP-enabled tools for legacy code refactoring, database migrations, and automated testing. Design and product teams leverage the system for documentation generation and prototype development.
Cross-Team Adoption: The standardized MCP interface enabled rapid adoption across diverse teams with different technical requirements. Data teams use MCP connections to internal systems for contextual analysis, while customer support teams process tickets and build prototypes through the same unified interface.
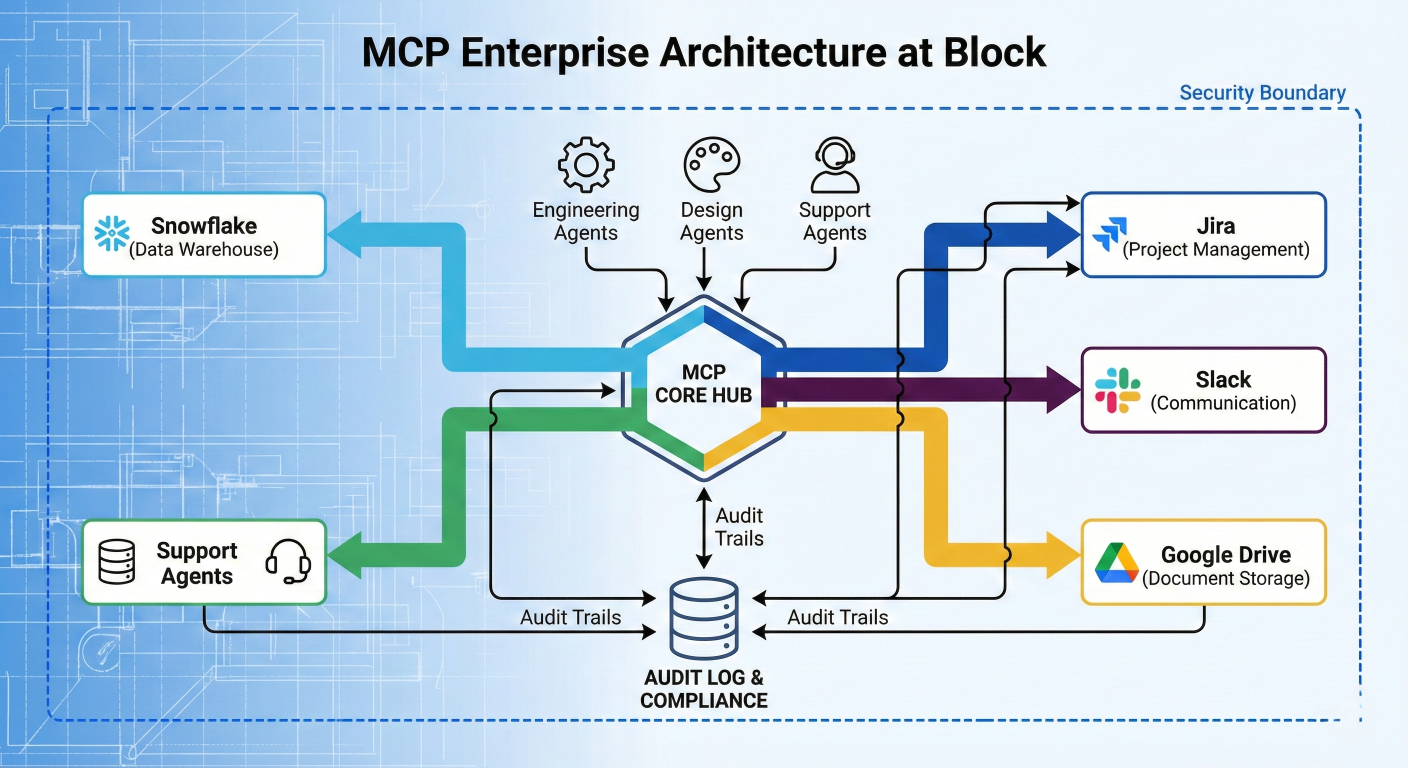
MCP Enterprise Architecture at Block: Show centralized MCP hub connecting to Snowflake, Jira, Slack, Google Drive; multiple agent types (engineering, design, data, support) accessing different tool combinations; include security boundaries and audit trails
The Model Control Plane operates on several fundamental principles that distinguish it from traditional model serving architectures. These principles guide design decisions and implementation strategies for scalable AI systems.
Separation of Control and Data Planes: The control plane makes decisions about routing, policies, and lifecycle management without directly handling inference requests. This separation enables independent scaling, policy enforcement, and governance without impacting inference performance. The data plane focuses solely on executing inference requests efficiently.
Policy-Driven Operations: All decisions about model selection, access control, and resource allocation are driven by explicitly defined policies rather than hard-coded logic. This enables non-technical stakeholders to modify behavior without code changes and ensures consistent enforcement across all interactions.
Multi-Tenancy by Design: The architecture supports multiple teams, projects, and environments with appropriate isolation and resource sharing. Each tenant can have different policies, budgets, and access controls while sharing underlying infrastructure efficiently.
Observability as a First-Class Citizen: Comprehensive monitoring, logging, and analytics are built into every component rather than added as an afterthought. This enables proactive optimization, debugging, and compliance reporting.
Vendor Neutrality: The control plane abstracts away differences between model providers, enabling seamless migration between vendors and multi-cloud deployments without application changes
Model Registry and Metadata Management
The model registry serves as the single source oftraining datasets, evaluation metrics, approval status, and deployment history. truth for all models, versions, and their metadata. Unlike simple model stores, an enterprise registry maintains rich metadata including.
Key capabilities include:
# Example model registry entry
models:
- id: "gpt-4-turbo-2024-04-09"
name: "GPT-4 Turbo April 2024"
provider: "openai"
capabilities:
- "text-generation"
- "code-completion"
- "reasoning"
performance:
max_tokens: 128000
latency_p95_ms: 2800
throughput_req_per_min: 500
cost:
input_token_price_per_1k: 0.01
output_token_price_per_1k: 0.03
compliance:
data_residency: ["us", "eu"]
certifications: ["soc2", "iso27001"]
deployment:
endpoints:
- region: "us-east-1"
url: "https://api.openai.com/v1/chat/completions"
auth_type: "bearer_token"
- region: "eu-west-1"
url: "https://api.openai.com/v1/chat/completions"
auth_type: "bearer_token"Policy Engine and Governance Framework
The policy engine enforces organizational rules and compliance requirements across all AI interactions. Modern implementations support both role-based access control (RBAC) and attribute-based access control (ABAC) for fine-grained permissions.
Policy categories include:
# Example policy configuration
policies:
access_control:
- name: "pii-sensitive-routing"
conditions:
- data_classification: "pii"
- user_role: ["data-scientist", "analyst"]
actions:
- route_to: "privacy-compliant-models"
- enable_logging: true
- require_approval: true
cost_management:
- name: "development-budget-limits"
conditions:
- environment: "dev"
- project: "*"
actions:
- monthly_budget_usd: 1000
- daily_budget_usd: 50
- alert_threshold: 0.8
- throttle_at_limit: true
quality_assurance:
- name: "production-quality-gates"
conditions:
- environment: "prod"
- model_type: "text-generation"
actions:
- min_quality_score: 0.85
- require_human_review: false
- shadow_traffic_percent: 10
The routing layer makes real-time decisions about which model endpoints should handle each request based on multiple factors including performance requirements, cost constraints, and availability
Advanced routing strategies include:
# Example routing logic implementation
class IntelligentRouter:
def __init__(self, policy_engine, model_registry, metrics_collector):
self.policy_engine = policy_engine
self.model_registry = model_registry
self.metrics = metrics_collector
def route_request(self, request, user_context):
# Apply policy filters
eligible_models = self.policy_engine.filter_models(
request.domain,
user_context.permissions,
request.data_classification
)
# Score models by cost-performance
scored_models = []
for model in eligible_models:
performance_score = self.calculate_performance_score(
model, request.complexity
)
cost_score = self.calculate_cost_score(
model, request.estimated_tokens
)
availability_score = self.metrics.get_availability(model.id)
total_score = (
performance_score * 0.4 +
cost_score * 0.3 +
availability_score * 0.3
)
scored_models.append((model, total_score))
# Select best model with fallback options
scored_models.sort(key=lambda x: x[1], reverse=True)
primary_model = scored_models[0][0]
fallback_models = [m[0] for m in scored_models[1:3]]
return RoutingDecision(
primary=primary_model,
fallbacks=fallback_models,
routing_reason="cost_performance_optimized"
)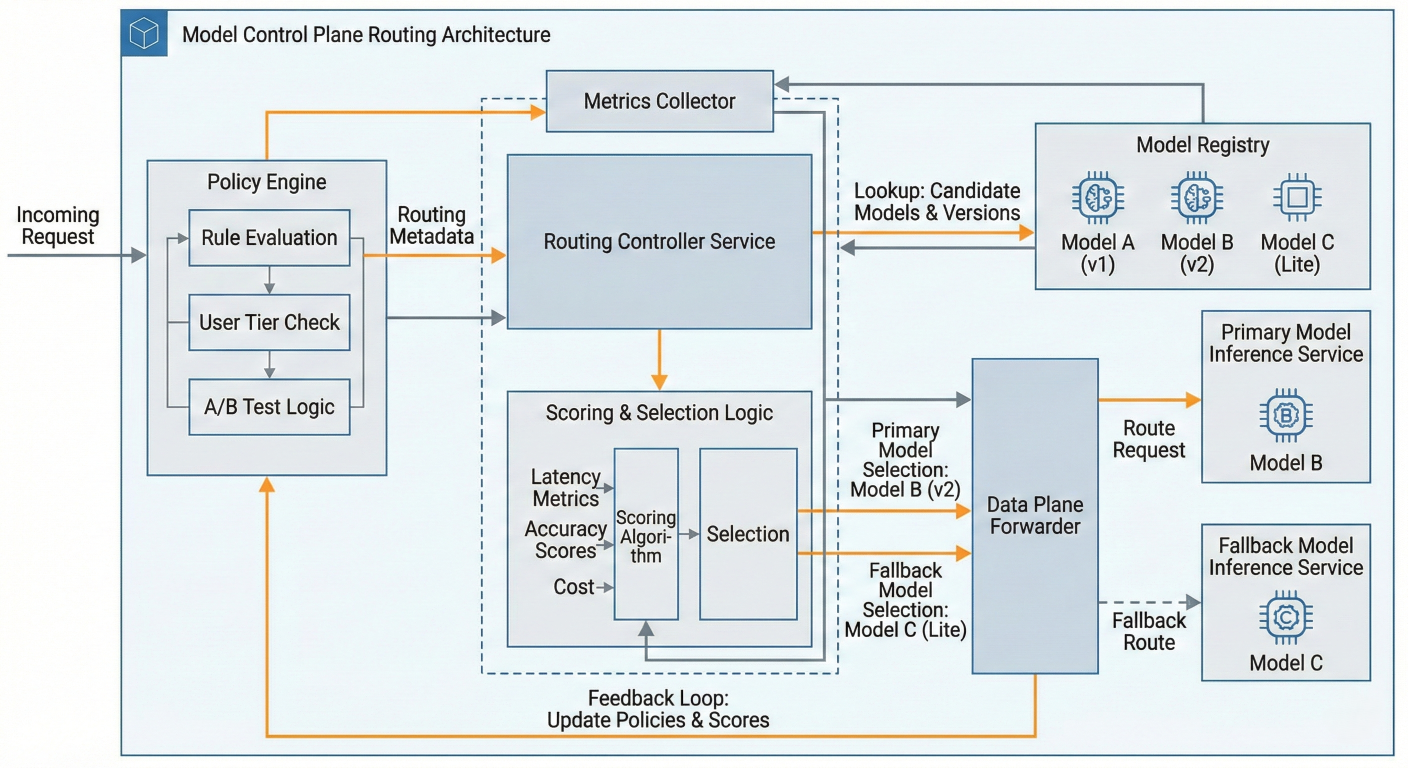
Model Control Plane Routing Architecture: Show request flow through policy engine, model registry lookup, scoring algorithm, primary/fallback selection, and metrics collection loop
Enterprise observability goes beyond basic metrics to provide actionable insights for optimization and compliance. The system must track performance, costs, quality, and business impact across all AI interactions.
Key observability components:
# Example observability implementation
from dataclasses import dataclass
from typing import Dict, Optional
import time
@dataclass
class RequestMetrics:
request_id: str
user_id: str
model_id: str
start_time: float
end_time: Optional[float] = None
input_tokens: int = 0
output_tokens: int = 0
cost_usd: float = 0.0
quality_score: Optional[float] = None
business_outcome: Optional[str] = None
class ObservabilityCollector:
def __init__(self, metrics_backend, cost_tracker, quality_evaluator):
self.metrics = metrics_backend
self.costs = cost_tracker
self.quality = quality_evaluator
def track_request(self, request_id: str, user_context, model_selection):
return RequestMetrics(
request_id=request_id,
user_id=user_context.user_id,
model_id=model_selection.model_id,
start_time=time.time()
)
def record_completion(self, metrics: RequestMetrics, response):
metrics.end_time = time.time()
metrics.input_tokens = response.usage.prompt_tokens
metrics.output_tokens = response.usage.completion_tokens
metrics.cost_usd = self.costs.calculate_cost(
metrics.model_id,
metrics.input_tokens,
metrics.output_tokens
)
# Asynchronous quality evaluation
self.quality.evaluate_async(
metrics.request_id,
response.content,
callback=lambda score: self.update_quality_score(
metrics.request_id, score
)
)
# Store comprehensive metrics
self.metrics.record({
'request_id': metrics.request_id,
'latency_ms': (metrics.end_time - metrics.start_time) * 1000,
'cost_usd': metrics.cost_usd,
'token_count': metrics.input_tokens + metrics.output_tokens,
'model_id': metrics.model_id,
'user_id': metrics.user_id,
'timestamp': metrics.end_time
})
Cost optimization in AI systems requires sophisticated strategies that balance performance, quality, and financial constraints. The control plane enables automated cost management that adapts to changing usage patterns and business requirements.
Dynamic Model Selection Based on Cost-Performance Profiles
Different models have varying cost-performance characteristics that change based on task complexity, input length, and quality requirements. The control plane maintains detailed costperformance models and automatically selects optimal configurations.
class CostOptimizer:
def __init__(self, model_registry, performance_predictor):
self.models = model_registry
self.predictor = performance_predictor
def optimize_selection(self, request, quality_threshold=0.8, budget_limit=None):
candidates = []
for model in self.models.get_eligible_models(request):
# Predict performance and cost
predicted_quality = self.predictor.predict_quality(
model.id, request.complexity, request.domain
)
estimated_cost = self.predictor.estimate_cost(
model.id, request.estimated_tokens
)
if predicted_quality >= quality_threshold:
efficiency_score = predicted_quality / estimated_cost
candidates.append({
'model': model,
'quality': predicted_quality,
'cost': estimated_cost,
'efficiency': efficiency_score
})
# Apply budget constraints
if budget_limit:
candidates = [c for c in candidates if c['cost'] <= budget_limit]
# Select most efficient model
if candidates:
optimal = max(candidates, key=lambda x: x['efficiency'])
return ModelSelection(
model=optimal['model'],
predicted_quality=optimal['quality'],
estimated_cost=optimal['cost'],
selection_reason="cost_efficiency_optimized"
)
return None # No suitable model found
Intelligent Caching and Result Reuse
Caching strategies can significantly reduce costs by avoiding redundant computations. The control plane implements multi-level caching with semantic similarity matching for language model outputs
import hashlib
from typing import Optional, Tuple
class SemanticCache:
def __init__(self, vector_store, similarity_threshold=0.85):
self.vector_store = vector_store
self.similarity_threshold = similarity_threshold
self.exact_cache = {} # Hash-based exact matching
def get_cached_response(self, prompt: str, model_id: str) -> Optional[str]:
# Try exact match first (fastest)
exact_key = self._hash_key(prompt, model_id)
if exact_key in self.exact_cache:
return self.exact_cache[exact_key]
# Try semantic similarity (slower but more flexible)
similar_results = self.vector_store.similarity_search(
prompt, model_filter=model_id, top_k=1
)
if similar_results and similar_results[0].similarity > self.similarity_threshold:
cached_response = similar_results[0].response
# Store in exact cache for future lookups
self.exact_cache[exact_key] = cached_response
return cached_response
return None
def store_response(
self,
prompt: str,
model_id: str,
response: str,
cost: float
):
exact_key = self._hash_key(prompt, model_id)
self.exact_cache[exact_key] = response
# Store in vector database for semantic matching
self.vector_store.add_document({
'prompt': prompt,
'response': response,
'model_id': model_id,
'cost_saved': cost,
'created_at': time.time()
})
def _hash_key(self, prompt: str, model_id: str) -> str:
return hashlib.sha256(f"{prompt}:{model_id}".encode()).hexdigest()
Automated Budget Management and Alerts
The control plane enforces budget limits at multiple levels (organization, team, project, user) with sophisticated alerting and throttling mechanisms.
class BudgetManager:
def __init__(self, budget_store, notification_service):
self.budgets = budget_store
self.notifications = notification_service
def check_budget_constraints(
self,
user_context,
estimated_cost: float
) -> Tuple[bool, Optional[str]]:
# Check hierarchical budgets (user -> project -> team -> org)
budget_levels = [
('user', user_context.user_id),
('project', user_context.project_id),
('team', user_context.team_id),
('organization', user_context.org_id)
]
for level_type, level_id in budget_levels:
budget = self.budgets.get_budget(level_type, level_id)
if not budget:
continue
current_spend = self.budgets.get_current_spend(level_type, level_id)
projected_spend = current_spend + estimated_cost
# Hard limit check
if projected_spend > budget.limit:
return False, f"{level_type} budget exceeded"
# Alert threshold check
utilization = projected_spend / budget.limit
if utilization >= budget.alert_threshold:
self.notifications.send_budget_alert(
level_type, level_id, utilization, budget.limit
)
return True, None
def record_spend(self, user_context, actual_cost: float):
# Record spend at all applicable levels
budget_levels = [
('user', user_context.user_id),
('project', user_context.project_id),
('team', user_context.team_id),
('organization', user_context.org_id)
]
for level_type, level_id in budget_levels:
self.budgets.increment_spend(level_type, level_id, actual_cost)
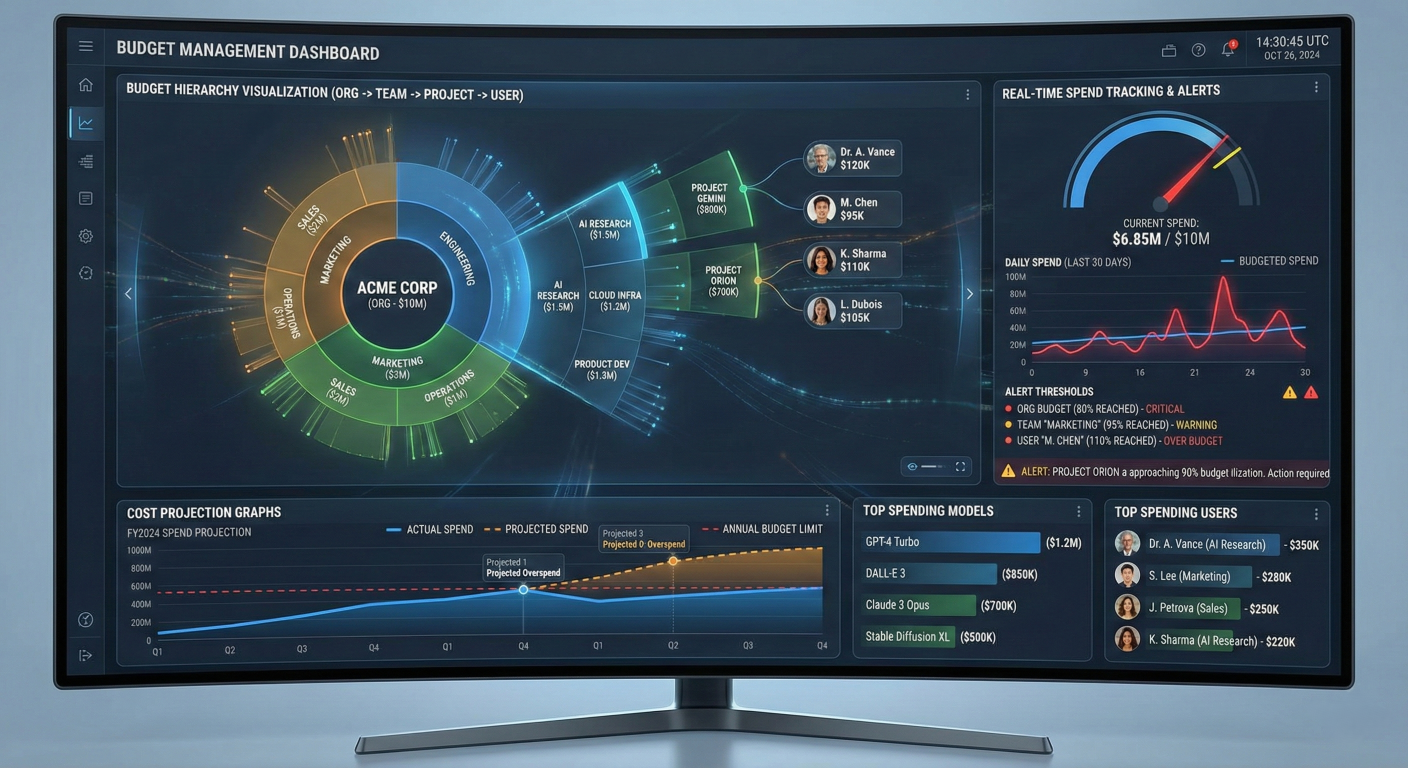
Budget Management Dashboard: Show hierarchical budget visualization (org -> team -> project -> user), real-time spend tracking, alert thresholds, cost projection graphs, and top spending models/users
The Model Context Protocol establishes a standardized framework for AI applications to interact with external tools and data sources. Built on JSON-RPC 2.0, MCP defines clear contracts for capability discovery, authentication, and tool invocation that work consistently across different AI platforms and tool providers.
Client-Server Architecture: MCP follows a clean client-server model where AI applications (hosts) embed MCP clients that connect to MCP servers exposing specific capabilities. Each client maintains a dedicated connection to one server, ensuring clear security boundaries and simplified debugging.
Capability Discovery: Servers dynamically expose their available tools, resources, and prompts through standardized discovery mechanisms. This allows AI applications to adapt their behavior based on available capabilities without requiring hardcoded integrations.
Transport Layer Flexibility: MCP supports multiple transport mechanisms including STDIO for local integrations and HTTP with Server-Sent Events for remote connections. This flexibility enables deployment patterns ranging from local development to distributed cloud architectures.
Schema-Driven Validation: All tool interfaces are defined using JSON schemas that enforce input validation and output formatting. This prevents malformed requests and ensures predictable behavior across different implementations
Tools: Model-Controlled Executable Functions
Tools represent actions that AI models can invoke to interact with external systems. Each tool has a unique name, description, and parameter schema that guide the model's decision-making process.
// Example MCP server exposing database tools import { FastMCP } from 'fastmcp'; const server = new FastMCP('database-server'); server.addTool({ name: 'query_customer_data', description: 'Retrieve customer information by ID or email', parameters: { type: 'object', properties: { customer_id: { type: 'string', description: 'Unique customer identifier' }, email: { type: 'string', format: 'email', description: 'Customer email address' }, include_orders: { type: 'boolean', default: false, description: 'Include recent order history' } }, oneOf: [ { required: ['customer_id'] }, { required: ['email'] } ] } }, async (params) => { // Input validation handled by schema const customer = await database.customers.findUnique({ where: params.customer_id ? { id: params.customer_id } : { email: params.email }, include: { orders: params.include_orders ? { take: 10, orderBy: { createdAt: 'desc' } } : false } }); if (!customer) { throw new Error('Customer not found'); } return { customer: { id: customer.id, name: customer.name, email: customer.email, status: customer.status, orders: customer.orders || [] } }; }); server.addTool({ name: 'create_support_ticket', description: 'Create a new customer support ticket', parameters: { type: 'object', properties: { customer_id: { type: 'string' }, subject: { type: 'string', maxLength: 200 }, description: { type: 'string', maxLength: 2000 }, priority: { type: 'string', enum: ['low', 'medium', 'high', 'urgent'], default: 'medium' }, category: { type: 'string', enum: ['billing', 'technical', 'account', 'general'] } }, required: ['customer_id', 'subject', 'description', 'category'] } }, async (params) => { const ticket = await database.supportTickets.create({ data: { customerId: params.customer_id, subject: params.subject, description: params.description, priority: params.priority, category: params.category, status: 'open', createdBy: 'ai-agent' } }); // Send notification to support team await notificationService.notifyNewTicket(ticket); return { ticket_id: ticket.id, status: 'created', estimated_response_time: '2-4 hours' }; });
Resources: Contextual Data Providers
Resources provide structured data that enriches the AI model's context without requiring explicit invocation. These are typically read-only data sources that the client application manages and injects into the model's context
// Example resource provider for documentation
server.addResource({
uri: 'doc://api-reference',
name: 'API Reference Documentation',
description: 'Complete REST API documentation with examples'
}, async () => {
const apiDocs = await documentationService.getApiReference();
return {
mimeType: 'text/markdown',
content: apiDocs.content,
metadata: {
version: apiDocs.version,
lastUpdated: apiDocs.lastUpdated,
sections: apiDocs.sections
}
};
});
server.addResource({
uri: 'schema://database',
name: 'Database Schema',
description: 'Current database schema with table relationships'
}, async () => {
const schema = await database.introspectSchema();
return {
mimeType: 'application/json',
content: JSON.stringify(schema, null, 2),
metadata: {
tables: schema.tables.length,
relationships: schema.relationships.length,
lastMigration: schema.lastMigration
}
};
});
Prompts: Interactive Templates
Prompts provide user-controlled templates that guide AI interactions. These are particularly useful for creating consistent experiences across different use cases and users.
// Add a new prompt to analyze customer behavior
server.addPrompt({
name: 'customer-analysis',
description: 'Analyze customer behavior and provide insights',
parameters: {
type: 'object',
properties: {
customer_id: { type: 'string' },
analysis_period: {
type: 'string',
enum: ['7d', '30d', '90d', '1y'],
default: '30d'
},
include_predictions: {
type: 'boolean',
default: true
}
},
required: ['customer_id']
}
}, async (params) => {
const customer = await database.customers.findUnique({
where: { id: params.customer_id },
include: {
orders: {
where: {
createdAt: {
gte: getPeriodStartDate(params.analysis_period)
}
}
},
supportTickets: true,
interactions: true
}
});
return {
role: 'user',
content: `Analyze the following customer data and provide insights:
**Customer Profile:**
- Name: ${customer.name}
- Email: ${customer.email}
- Join Date: ${customer.createdAt}
- Status: ${customer.status}
**Recent Activity (${params.analysis_period}):**
- Orders: ${customer.orders.length}
- Total Spent: $${customer.orders.reduce((sum, order) => sum + order.total, 0)}
- Support Tickets: ${customer.supportTickets.length}
- Last Interaction: ${customer.interactions[0]?.createdAt || 'None'}
Please provide:
1. Customer health score (1-10)
2. Key behavioral patterns
3. Potential risks or opportunities
${params.include_predictions ? '4. Predictions for next 30 days' : ''}
5. Recommended actions`
};
});
Production MCP servers require robust error handling, authentication, monitoring, and security controls. The following example demonstrates enterprise-ready patterns.
import { FastMCP } from 'fastmcp';
import { Logger } from 'winston';
import { RateLimiter } from 'bottleneck';
import { validateToken, checkPermissions } from './auth';
import { AuditLogger } from './audit';
class EnterpriseMCPServer {
private server: FastMCP;
private logger: Logger;
private rateLimiter: RateLimiter;
private auditLogger: AuditLogger;
constructor(config: ServerConfig) {
this.server = new FastMCP(config.name);
this.logger = new Logger(config.logging);
this.rateLimiter = new RateLimiter({
minTime: config.rateLimit.minTimeMs,
maxConcurrent: config.rateLimit.maxConcurrent
});
this.auditLogger = new AuditLogger(config.audit);
this.setupMiddleware();
this.setupErrorHandling();
}
private setupMiddleware() {
// Authentication middleware
this.server.use(async (context, next) => {
try {
const token = context.headers['authorization']?.replace('Bearer ', '');
if (!token) {
throw new Error('Authentication required');
}
const user = await validateToken(token);
context.user = user;
this.auditLogger.logAccess({
userId: user.id,
action: 'server_access',
serverName: this.server.name,
timestamp: new Date()
});
await next();
} catch (error) {
this.logger.error('Authentication failed', { error: error.message });
throw new Error('Authentication failed');
}
});
// Rate limiting middleware
this.server.use(async (context, next) => {
await this.rateLimiter.schedule(async () => {
await next();
});
});
// Request logging middleware
this.server.use(async (context, next) => {
const startTime = Date.now();
try {
await next();
this.logger.info('Request completed', {
userId: context.user?.id,
method: context.method,
duration: Date.now() - startTime,
status: 'success'
});
} catch (error) {
this.logger.error('Request failed', {
userId: context.user?.id,
method: context.method,
duration: Date.now() - startTime,
error: error.message,
status: 'error'
});
throw error;
}
});
}
private setupErrorHandling() {
this.server.onError((error, context) => {
// Sanitize error messages for security
const sanitizedError = this.sanitizeError(error);
this.auditLogger.logError({
userId: context.user?.id,
error: error.message,
stackTrace: error.stack,
context: {
method: context.method,
params: context.params
},
timestamp: new Date()
});
return {
error: {
code: sanitizedError.code,
message: sanitizedError.message
}
};
});
}
addSecureTool(
toolDefinition: ToolDefinition,
handler: ToolHandler,
requiredPermissions: string[]
) {
this.server.addTool(toolDefinition, async (params, context) => {
// Permission check
const hasPermission = await checkPermissions(
context.user,
requiredPermissions
);
if (!hasPermission) {
throw new Error('Insufficient permissions');
}
// Input validation and sanitization
const sanitizedParams = this.sanitizeInput(params, toolDefinition.parameters);
// Audit log tool invocation
this.auditLogger.logToolInvocation({
userId: context.user.id,
toolName: toolDefinition.name,
parameters: sanitizedParams,
timestamp: new Date()
});
try {
const result = await handler(sanitizedParams, context);
// Audit log successful completion
this.auditLogger.logToolCompletion({
userId: context.user.id,
toolName: toolDefinition.name,
success: true,
timestamp: new Date()
});
return result;
} catch (error) {
// Audit log failure
this.auditLogger.logToolCompletion({
userId: context.user.id,
toolName: toolDefinition.name,
success: false,
error: error.message,
timestamp: new Date()
});
throw error;
}
});
}
private sanitizeInput(input: any, schema: JSONSchema): any {
// Implement input sanitization based on schema
// Remove potentially dangerous content
// Validate against schema constraints
return input; // Simplified for example
}
private sanitizeError(error: Error): { code: string, message: string } {
// Prevent information leakage in error messages
if (error.message.includes('database') || error.message.includes('sql')) {
return { code: 'DATABASE_ERROR', message: 'A database error occurred' };
}
if (error.message.includes('authentication') || error.message.includes('token')) {
return { code: 'AUTH_ERROR', message: 'Authentication failed' };
}
return { code: 'GENERAL_ERROR', message: 'An error occurred' };
}
}
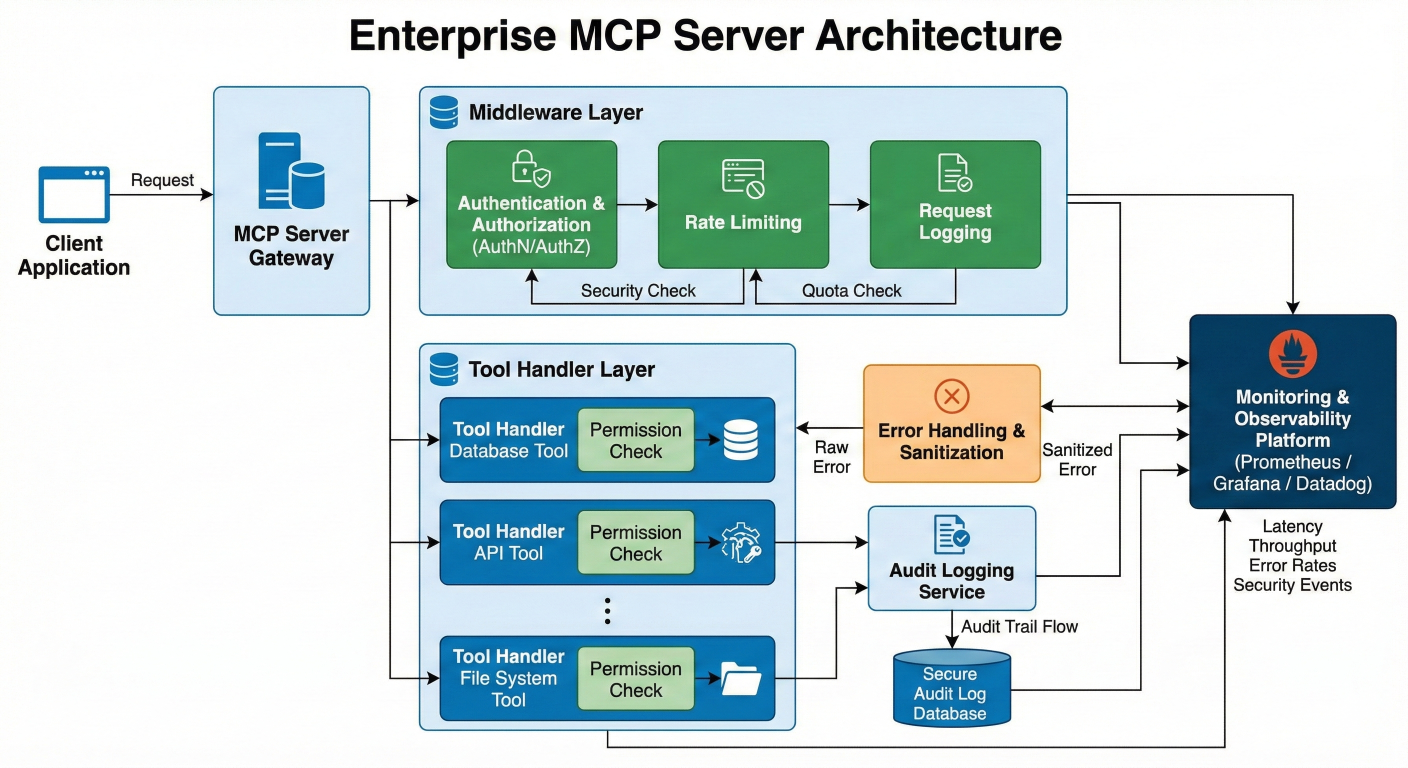
Enterprise MCP Server Architecture: Show middleware layers (auth, rate limiting, logging), tool handlers with permission checks, audit logging flow, error sanitization, and monitoring integration
Security in MCP deployments requires defense-in-depth strategies that protect against various attack vectors including prompt injection, credential compromise, and unauthorized access.
Authentication and Authorization
// Enterprise authentication implementation
class MCPAuthManager {
private tokenValidator: JWTValidator;
private permissionEngine: PermissionEngine;
private auditLogger: AuditLogger;
constructor(config: AuthConfig) {
this.tokenValidator = new JWTValidator({
issuer: config.oidc.issuer,
audience: config.oidc.audience,
algorithms: ['RS256'],
cache: true,
cacheTTL: 300 // 5 minutes
});
this.permissionEngine = new PermissionEngine(config.rbac);
this.auditLogger = new AuditLogger(config.audit);
}
async authenticateRequest(authHeader: string): Promise<AuthContext> {
if (!authHeader?.startsWith('Bearer ')) {
throw new AuthError('Invalid authorization header');
}
const token = authHeader.substring(7);
try {
// Validate JWT token
const payload = await this.tokenValidator.verify(token);
// Create auth context
const authContext = new AuthContext({
userId: payload.sub,
email: payload.email,
roles: payload.roles || [],
permissions: payload.permissions || [],
organizationId: payload.org_id,
tokenId: payload.jti
});
// Log successful authentication
this.auditLogger.logAuth({
userId: authContext.userId,
action: 'authenticate',
success: true,
timestamp: new Date()
});
return authContext;
} catch (error) {
// Log failed authentication
this.auditLogger.logAuth({
token: token.substring(0, 10) + '...',
action: 'authenticate',
success: false,
error: error.message,
timestamp: new Date()
});
throw new AuthError('Token validation failed');
}
}
async checkToolPermission(
authContext: AuthContext,
toolName: string,
parameters: any
): Promise<boolean> {
// Check basic tool access
const hasToolAccess = await this.permissionEngine.hasPermission(
authContext,
`tool:${toolName}:execute`
);
if (!hasToolAccess) {
return false;
}
// Check parameter-level permissions
const paramPermissions = await this.permissionEngine.checkParameterAccess(
authContext,
toolName,
parameters
);
// Log permission check
this.auditLogger.logPermissionCheck({
userId: authContext.userId,
resource: `tool:${toolName}`,
action: 'execute',
granted: hasToolAccess && paramPermissions.allowed,
restrictions: paramPermissions.restrictions,
timestamp: new Date()
});
return hasToolAccess && paramPermissions.allowed;
}
}
// Permission engine with RBAC and ABAC support
class PermissionEngine {
private policies: PolicyStore;
private attributeProvider: AttributeProvider;
async hasPermission(
authContext: AuthContext,
permission: string
): Promise<boolean> {
// Check role-based permissions
const rolePermissions = await this.getRolePermissions(authContext.roles);
if (rolePermissions.includes(permission)) {
return true;
}
// Check attribute-based permissions
const attributes = await this.attributeProvider.getAttributes(authContext);
const abacResult = await this.evaluateABACPolicies(
authContext,
permission,
attributes
);
return abacResult.allowed;
}
async checkParameterAccess(
authContext: AuthContext,
toolName: string,
parameters: any
): Promise<{ allowed: boolean, restrictions: string[] }> {
const restrictions = [];
// Check data classification restrictions
if (parameters.data_classification) {
const canAccessClassification = await this.hasPermission(
authContext,
`data:${parameters.data_classification}:read`
);
if (!canAccessClassification) {
return { allowed: false, restrictions: ['data_classification'] };
}
}
// Check customer data access
if (parameters.customer_id) {
const canAccessCustomer = await this.checkCustomerAccess(
authContext,
parameters.customer_id
);
if (!canAccessCustomer) {
restrictions.push('customer_access');
}
}
return {
allowed: restrictions.length === 0,
restrictions
};
}
}
Input Validation and Sanitization
class InputValidator {
private schemaValidator: JSONSchemaValidator;
private sanitizer: InputSanitizer;
constructor() {
this.schemaValidator = new JSONSchemaValidator();
this.sanitizer = new InputSanitizer({
// Remove potentially dangerous patterns
patterns: [
/system\s*:/gi, // System prompt injection
/ignore\s+previous/gi, // Instruction override
/forget\s+everything/gi, // Context reset attempts
/<script\b[^<]*(?:(?!<\/script>)<[^<]*)*<\/script>/gi, // XSS
/sql\s*injection/gi, // SQL injection keywords
/eval\s*\(/gi, // Code execution
/exec\s*\(/gi // Command execution
],
maxLength: {
string: 10000,
array: 1000,
object: 100
}
});
}
validateAndSanitize(input: any, schema: JSONSchema): ValidationResult {
// Schema validation
const schemaResult = this.schemaValidator.validate(input, schema);
if (!schemaResult.valid) {
return {
valid: false,
errors: schemaResult.errors,
sanitized: null
};
}
// Input sanitization
const sanitized = this.sanitizer.sanitize(input);
// Additional security checks
const securityResult = this.performSecurityChecks(sanitized);
if (!securityResult.safe) {
return {
valid: false,
errors: ['Input contains potentially dangerous content'],
sanitized: null,
securityIssues: securityResult.issues
};
}
return {
valid: true,
errors: [],
sanitized: sanitized,
securityIssues: []
};
}
private performSecurityChecks(input: any): SecurityCheckResult {
const issues = [];
// Check for prompt injection patterns
const stringifiedInput = JSON.stringify(input).toLowerCase();
if (stringifiedInput.includes('ignore previous')) {
issues.push('potential_prompt_injection');
}
if (stringifiedInput.includes('system:') || stringifiedInput.includes('assistant:')) {
issues.push('role_confusion_attempt');
}
// Check for excessive nesting (potential DoS)
const maxDepth = this.calculateObjectDepth(input);
if (maxDepth > 10) {
issues.push('excessive_nesting');
}
return {
safe: issues.length === 0,
issues: issues
};
}
}
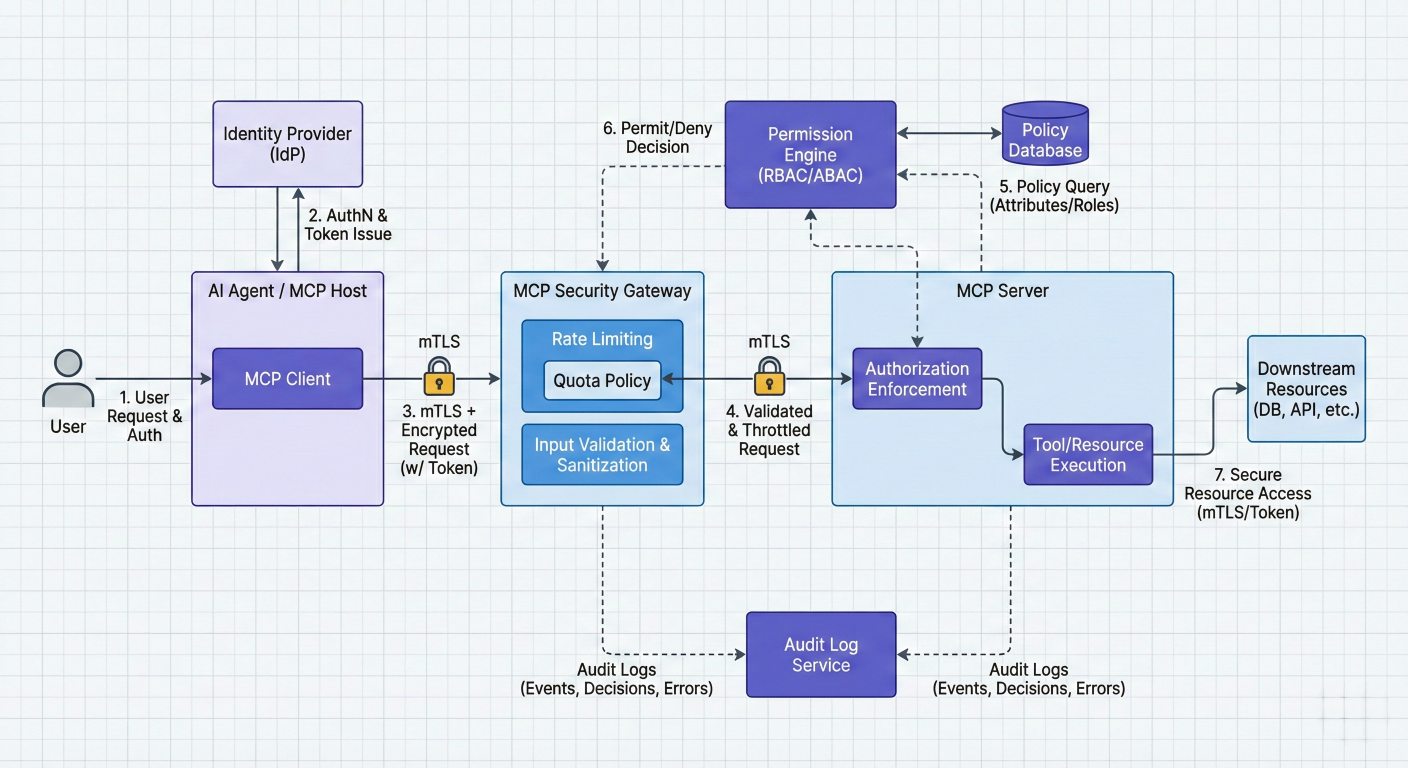
MCP Security Architecture: Show authentication flow, permission engine (RBAC/ABAC), input validation/sanitization, audit logging, rate limiting, and transport security (mTLS)
Traditional RAG systems retrieve static documents from vector databases. MCP extends this pattern by enabling dynamic tool invocation that can fetch real-time data, perform calculations, and interact with live systems during the retrieval process.
Dynamic Context Augmentation
import asyncio
from typing import List, Dict, Any, Optional
from dataclasses import dataclass
from mcp_client import MCPClient
from vector_store import VectorStore
from llm_client import LLMClient
@dataclass
class EnhancedContext:
static_documents: List[str]
dynamic_data: Dict[str, Any]
tool_outputs: List[Dict[str, Any]]
metadata: Dict[str, Any]
class MCPEnhancedRAG:
def __init__(self, vector_store: VectorStore, llm_client: LLMClient, mcp_clients: Dict[str, MCPClient]):
self.vector_store = vector_store
self.llm = llm_client
self.mcp_clients = mcp_clients
async def enhanced_retrieval(self, query: str, user_context: Dict[str, Any]) -> EnhancedContext:
# Traditional vector-based retrieval
static_docs = await self.vector_store.similarity_search(query, k=5, filters={'user_id': user_context.get('user_id')})
# Dynamic data retrieval through MCP
dynamic_data = {}
tool_outputs = []
# Customer context retrieval
if 'customer_id' in user_context:
customer_client = self.mcp_clients['customer_db']
customer_data = await customer_client.call_tool('get_customer_profile', {'customer_id': user_context['customer_id']})
dynamic_data['customer'] = customer_data
tool_outputs.append({'tool': 'get_customer_profile', 'output': customer_data})
# Real-time system status
if self.requires_system_status(query):
system_client = self.mcp_clients['monitoring']
system_status = await system_client.call_tool('get_system_health', {'components': ['api', 'database', 'cache']})
dynamic_data['system_status'] = system_status
tool_outputs.append({'tool': 'get_system_health', 'output': system_status})
# Market data for financial queries
if self.is_financial_query(query):
market_client = self.mcp_clients['market_data']
market_data = await market_client.call_tool('get_market_snapshot', {'symbols': self.extract_symbols(query)})
dynamic_data['market_data'] = market_data
tool_outputs.append({'tool': 'get_market_snapshot', 'output': market_data})
return EnhancedContext(
static_documents=[doc.content for doc in static_docs],
dynamic_data=dynamic_data,
tool_outputs=tool_outputs,
metadata={'query': query, 'retrieval_timestamp': asyncio.get_event_loop().time(), 'tools_used': [output['tool'] for output in tool_outputs]}
)
async def generate_response(self, query: str, context: EnhancedContext) -> Dict[str, Any]:
# Construct comprehensive prompt
prompt = self.build_enhanced_prompt(query, context)
# Generate response with full context
response = await self.llm.generate(prompt, max_tokens=2000, temperature=0.1)
return {'response': response.text, 'sources': {'static_documents': len(context.static_documents), 'dynamic_sources': list(context.dynamic_data.keys()), 'tools_invoked': [out['tool'] for out in context.tool_outputs]}, 'metadata': context.metadata, 'confidence': response.confidence_score}
def build_enhanced_prompt(self, query: str, context: EnhancedContext) -> str:
prompt_parts = [f"User Query: {query}", "", "Static Knowledge Base:"]
# Add static documents
for i, doc in enumerate(context.static_documents, 1):
prompt_parts.append(f"Document {i}: {doc[:500]}...")
# Add dynamic data
if context.dynamic_data:
prompt_parts.extend(["", "Real-time Context:"])
for source, data in context.dynamic_data.items():
prompt_parts.append(f"{source.title()}: {self.format_data(data)}")
# Add tool outputs with explanations
if context.tool_outputs:
prompt_parts.extend(["", "Live System Data:"])
for tool_output in context.tool_outputs:
tool_name = tool_output['tool']
output = tool_output['output']
prompt_parts.append(f"From {tool_name}: {self.format_data(output)}")
prompt_parts.extend(["", "Instructions:", "1. Use ALL available context (static, dynamic, and live data)", "2. Prioritize real-time information over static documents when conflicts exist", "3. Cite specific sources for factual claims", "4. If data is incomplete, clearly state limitations", "5. Provide actionable recommendations when appropriate", "", "Response:"])
return "\n".join(prompt_parts)
def format_data(self, data: Any) -> str:
"""Format complex data structures for prompt inclusion"""
if isinstance(data, dict):
return "; ".join([f"{k}: {v}" for k, v in data.items()])
elif isinstance(data, list):
return "; ".join([str(item) for item in data[:5]])
else:
return str(data)[:200]
class FinancialAdvisoryRAG(MCPEnhancedRAG):
async def analyze_portfolio(
self,
user_query: str,
portfolio_id: str
) -> Dict[str, Any]:
# Enhanced retrieval with financial context
context = await self.enhanced_retrieval(
user_query,
{'portfolio_id': portfolio_id}
)
# Get additional financial data through MCP
portfolio_client = self.mcp_clients['portfolio_service']
# Current holdings
holdings = await portfolio_client.call_tool(
'get_portfolio_holdings',
{'portfolio_id': portfolio_id}
)
# Performance metrics
performance = await portfolio_client.call_tool(
'calculate_portfolio_metrics',
{
'portfolio_id': portfolio_id,
'period': '1Y',
'benchmarks': ['SPY', 'QQQ']
}
)
# Risk analysis
risk_analysis = await portfolio_client.call_tool(
'analyze_portfolio_risk',
{
'portfolio_id': portfolio_id,
'risk_factors': ['market', 'sector', 'geographic', 'currency']
}
)
# Market conditions
market_client = self.mcp_clients['market_data']
market_conditions = await market_client.call_tool(
'get_market_sentiment',
{'indicators': ['vix', 'yield_curve', 'sector_rotation']}
)
# Enhance context with financial data
context.dynamic_data.update({
'holdings': holdings,
'performance': performance,
'risk_analysis': risk_analysis,
'market_conditions': market_conditions
})
# Generate comprehensive analysis
analysis = await self.generate_response(user_query, context)
return {
'analysis': analysis['response'],
'data_sources': analysis['sources'],
'recommendations': self.extract_recommendations(analysis['response']),
'risk_score': risk_analysis.get('overall_risk_score'),
'confidence': analysis['confidence']
} 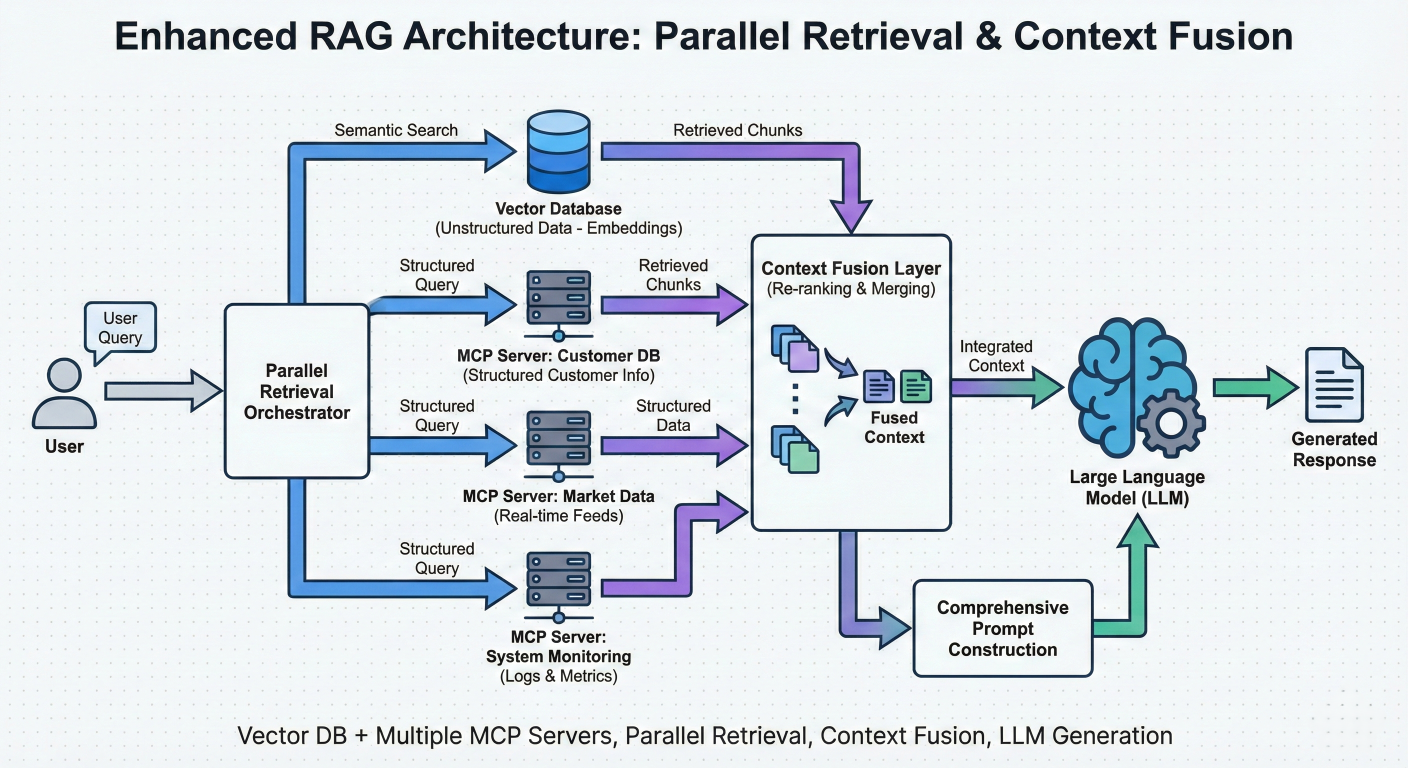
Enhanced RAG Architecture: Show vector database + multiple MCP servers (customer DB, market data, system monitoring), parallel retrieval, context fusion, and LLM generation with comprehensive prompt
Complex AI applications benefit from specialized agents coordinating through standardized MCP interfaces. This pattern enables scalable, maintainable multi-agent systems where each agent focuses on specific capabilities.
Agent Coordination Framework
from abc import ABC, abstractmethod
from enum import Enum
import asyncio
from typing import List, Dict, Any, Optional, Callable
import uuid
class AgentRole(Enum):
COORDINATOR = "coordinator"
SPECIALIST = "specialist"
VALIDATOR = "validator"
MONITOR = "monitor"
class TaskStatus(Enum):
PENDING = "pending"
IN_PROGRESS = "in_progress"
COMPLETED = "completed"
FAILED = "failed"
REQUIRES_VALIDATION = "requires_validation"
# Task dataclass definition
@dataclass
class Task:
id: str
type: str
description: str
parameters: Dict[str, Any]
assigned_agent: Optional[str] = None
status: TaskStatus = TaskStatus.PENDING
result: Optional[Any] = None
error: Optional[str] = None
dependencies: List[str] = None
created_at: float = None
completed_at: Optional[float] = None
# Abstract MCP Agent base class
class MCPAgent(ABC):
def __init__(
self,
agent_id: str,
role: AgentRole,
capabilities: List[str],
mcp_clients: Dict[str, MCPClient]
):
self.agent_id = agent_id
self.role = role
self.capabilities = capabilities
self.mcp_clients = mcp_clients
self.task_queue = asyncio.Queue()
self.active_tasks = {}
@abstractmethod
async def process_task(self, task: Task) -> Task:
"""Process a single task and return updated task with results"""
pass
async def can_handle_task(self, task: Task) -> bool:
"""Check if this agent can handle the given task type"""
return task.type in self.capabilities
async def execute_mcp_tool(
self,
server_name: str,
tool_name: str,
parameters: Dict[str, Any]
) -> Any:
"""Execute MCP tool with error handling and logging"""
try:
client = self.mcp_clients[server_name]
result = await client.call_tool(tool_name, parameters)
return result
except Exception as e:
raise Exception(f"MCP tool execution failed: {tool_name} - {str(e)}")
# Coordinator Agent implementation
class CoordinatorAgent(MCPAgent):
def __init__(self, agent_id: str, mcp_clients: Dict[str, MCPClient]):
super().__init__(
agent_id,
AgentRole.COORDINATOR,
["task_planning", "agent_coordination", "result_synthesis"],
mcp_clients
)
self.specialist_agents = {}
self.task_graph = {}
async process_complex_request(
self,
request: str,
context: Dict[str, Any]
) -> Dict[str, Any]:
"""Break down complex request into tasks and coordinate execution"""
# Plan task decomposition
task_plan = await self.plan_tasks(request, context)
# Create task graph with dependencies
tasks = []
for task_spec in task_plan['tasks']:
task = Task(
id=str(uuid.uuid4()),
type=task_spec['type'],
description=task_spec['description'],
parameters=task_spec['parameters'],
dependencies=task_spec.get('dependencies', []),
created_at=asyncio.get_event_loop().time()
)
tasks.append(task)
self.task_graph[task.id] = task
# Execute tasks with dependency management
results = await self.execute_task_graph(tasks)
# Synthesize final result
final_result = await self.synthesize_results(request, results, context)
return final_result
async def plan_tasks(
self,
request: str,
context: Dict[str, Any]
) -> Dict[str, Any]:
"""Use planning agent to decompose request into executable tasks"""
planning_prompt = f"""
Break down this complex request into specific, executable tasks:
Request: {request}
Context: {context}
Available agent capabilities:
- Data retrieval and analysis
- Document processing and summarization
- Calculation and computation
- External API integration
- Content generation
- Quality validation
Return a JSON task plan with dependencies:
{{
"tasks": [
{{
"type": "data_retrieval",
"description": "...",
"parameters": {{}},
"dependencies": []
}},
...
]
}}
"""
# Use LLM for task planning
plan_result = await self.execute_mcp_tool(
'llm_service',
'generate_structured_response',
{
'prompt': planning_prompt,
'response_format': 'json',
'temperature': 0.1
}
)
return plan_result['response']
async def execute_task_graph(self, tasks: List[Task]) -> Dict[str, Any]:
"""Execute tasks respecting dependencies"""
completed_tasks = {}
pending_tasks = {task.id: task for task in tasks}
while pending_tasks:
# Find tasks ready for execution (no unmet dependencies)
ready_tasks = []
for task_id, task in pending_tasks.items():
if not task.dependencies or all(
dep_id in completed_tasks for dep_id in task.dependencies
):
ready_tasks.append(task)
if not ready_tasks:
raise Exception("Circular dependency detected in task graph")
# Execute ready tasks in parallel
execution_futures = []
for task in ready_tasks:
# Assign to appropriate specialist agent
agent = await self.select_agent_for_task(task)
if agent:
task.assigned_agent = agent.agent_id
future = agent.process_task(task)
execution_futures.append(future)
else:
# Handle task locally if no specialist available
future = self.process_task(task)
execution_futures.append(future)
# Wait for completion
completed = await asyncio.gather(*execution_futures, return_exceptions=True)
# Process results
for i, result in enumerate(completed):
task = ready_tasks[i]
if isinstance(result, Exception):
task.status = TaskStatus.FAILED
task.error = str(result)
else:
task.status = TaskStatus.COMPLETED
task.result = result
task.completed_at = asyncio.get_event_loop().time()
completed_tasks[task.id] = task
del pending_tasks[task.id]
return completed_tasks
async def select_agent_for_task(self, task: Task) -> Optional[MCPAgent]:
"""Select the best agent for a given task"""
suitable_agents = []
for agent in self.specialist_agents.values():
if await agent.can_handle_task(task):
suitable_agents.append(agent)
if not suitable_agents:
return None
# Simple selection - could be enhanced with load balancing
return suitable_agents[0]
class DataRetrievalAgent(MCPAgent):
def __init__(self, agent_id: str, mcp_clients: Dict[str, MCPClient]):
super().__init__(
agent_id,
AgentRole.SPECIALIST,
["data_retrieval", "database_query", "api_integration"],
mcp_clients
)
async def process_task(self, task: Task) -> Any:
"""Process data retrieval tasks"""
task.status = TaskStatus.IN_PROGRESS
try:
if task.type == "customer_data_retrieval":
result = await self.retrieve_customer_data(task.parameters)
elif task.type == "market_data_retrieval":
result = await self.retrieve_market_data(task.parameters)
elif task.type == "system_metrics_retrieval":
result = await self.retrieve_system_metrics(task.parameters)
else:
raise ValueError(f{task.type})
task.result = result
task.status = TaskStatus.COMPLETED
return result
except Exception as e:
task.status = TaskStatus.FAILED
task.error = str(e)
raise
async def retrieve_customer_data(self, parameters: Dict[str, Any]) -> Dict[str, Any]:
"""Retrieve comprehensive customer data"""
customer_id = parameters['customer_id']
# Get basic customer info
customer_info = await self.execute_mcp_tool(
'customer_db',
'get_customer_profile',
{'customer_id': customer_id}
)
# Get order history
order_history = await self.execute_mcp_tool(
'orders_db',
'get_customer_orders',
{
'customer_id': customer_id,
'limit': 50,
'include_details': True
}
)
# Get support tickets
support_tickets = await self.execute_mcp_tool(
'support_system',
'get_customer_tickets',
{
'customer_id': customer_id,
'status': 'all',
'limit': 20
}
)
return {
'customer_info': customer_info,
'order_history': order_history,
'support_tickets': support_tickets,
'data_completeness': self.assess_data_completeness({
'customer_info': customer_info,
'order_history': order_history,
'support_tickets': support_tickets
})
}
class AnalysisAgent(MCPAgent):
def __init__(self, agent_id: str, mcp_clients: Dict[str, MCPClient]):
super().__init__(
agent_id,
AgentRole.SPECIALIST,
["data_analysis", "calculation", "pattern_recognition"],
mcp_clients
)
async def process_task(self, task: Task) -> Any:
"""Process analysis tasks"""
task.status = TaskStatus.IN_PROGRESS
try:
if task.type == "customer_behavior_analysis":
result = await self.analyze_customer_behavior(task.parameters)
elif task.type == "financial_analysis":
result = await self.analyze_financial_data(task.parameters)
elif task.type == "trend_analysis":
result = await self.analyze_trends(task.parameters)
else:
raise ValueError(f"Unknown analysis type: {task.type}" )
task.result = result
task.status = TaskStatus.COMPLETED
return result
except Exception as e:
task.status = TaskStatus.FAILED
task.error = str(e)
raise
async def analyze_customer_behavior(
self,
parameters: Dict[str, Any]
) -> Dict[str, Any]:
"""Analyze customer behavior patterns"""
customer_data = parameters['customer_data']
# Use analytics service for pattern recognition
behavior_patterns = await self.execute_mcp_tool(
'analytics_service',
'analyze_behavior_patterns',
{
'customer_id': customer_data['customer_info']['id'],
'order_history': customer_data['order_history'],
'support_interactions': customer_data['support_tickets'],
'analysis_period': parameters.get('period', '12M')
}
)
# Calculate customer health score
health_score = await self.execute_mcp_tool(
'scoring_service',
'calculate_customer_health',
{
'behavior_data': behavior_patterns,
'recency_weight': 0.3,
'frequency_weight': 0.3,
'monetary_weight': 0.4
}
)
return {
'behavior_patterns': behavior_patterns,
'health_score': health_score,
'risk_indicators': self.identify_risk_indicators(behavior_patterns),
'opportunities': self.identify_opportunities(behavior_patterns),
'recommendations': self.generate_recommendations(
behavior_patterns, health_score
)
}
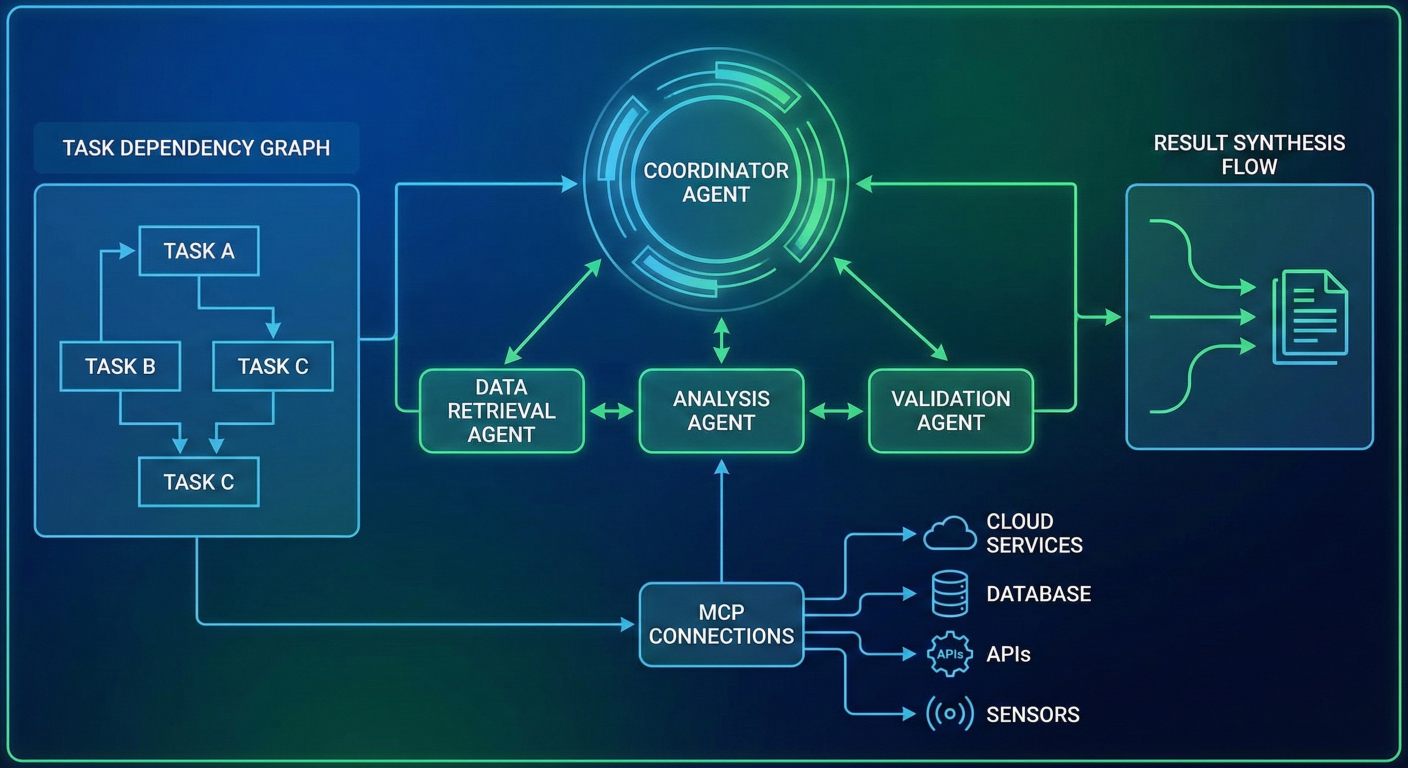
Multi-Agent Coordination Architecture: Show coordinator agent orchestrating specialist agents (data retrieval, analysis, validation), task dependency graph, MCP connections to various services, and result synthesis flow
Containerized MCP Server Deployment
# Kubernetes deployment for enterprise MCP server
apiVersion: apps/v1
kind: Deployment
metadata:
name: customer-mcp-server
namespace: ai-platform
labels:
app: customer-mcp-server
version: v1.2.3
spec:
replicas: 3
selector:
matchLabels:
app: customer-mcp-server
template:
metadata:
labels:
app: customer-mcp-server
version: v1.2.3
spec:
serviceAccountName: mcp-server-sa
securityContext:
runAsNonRoot: true
runAsUser: 1000
fsGroup: 2000
containers:
- name: mcp-server
image: company/customer-mcp-server:v1.2.3
ports:
- containerPort: 8080
name: http
env:
- name: DATABASE_URL
valueFrom:
secretKeyRef:
name: database-credentials
key: url
- name: AUTH_ISSUER
value: "https://auth.company.com"
- name: LOG_LEVEL
value: "info"
- name: METRICS_PORT
value: "9090"
resources:
requests:
memory: "256Mi"
cpu: "200m"
limits:
memory: "512Mi"
cpu: "500m"
livenessProbe:
httpGet:
path: /health
port: 8080
initialDelaySeconds: 30
periodSeconds: 10
readinessProbe:
httpGet:
path: /ready
port: 8080
initialDelaySeconds: 5
periodSeconds: 5
volumeMounts:
- name: config
mountPath: /app/config
readOnly: true
- name: certificates
mountPath: /app/certs
readOnly: true
volumes:
- name: config
configMap:
name: mcp-server-config
- name: certificates
secret:
secretName: mcp-server-tls
---
apiVersion: v1
kind: Service
metadata:
name: customer-mcp-server
namespace: ai-platform
spec:
selector:
app: customer-mcp-server
ports:
- name: http
port: 80
targetPort: 8080
- name: metrics
port: 9090
targetPort: 9090
type: ClusterIP
---
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: customer-mcp-server-netpol
namespace: ai-platform
spec:
podSelector:
matchLabels:
app: customer-mcp-server
policyTypes:
- Ingress
- Egress
ingress:
- from:
- namespaceSelector:
matchLabels:
name: ai-agents
- podSelector:
matchLabels:
role: mcp-client
ports:
- protocol: TCP
port: 8080
egress:
- to:
- namespaceSelector:
matchLabels:
name: databases
ports:
- protocol: TCP
port: 5432
- to: []
ports:
- protocol: TCP
port: 443 # HTTPS for external services
Production Monitoring and Observability
# Prometheus, OpenTelemetry, and MCP server metrics implementation
from prometheus_client import Counter, Histogram, Gauge, start_http_server
import structlog
import opentelemetry.auto_instrumentation
from opentelemetry import trace
from opentelemetry.exporter.jaeger.thrift import JaegerExporter
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor
class MCPServerMetrics:
def __init__(self):
# Prometheus metrics
self.request_count = Counter(
'mcp_requests_total',
'Total MCP requests',
['server_name', 'tool_name', 'status']
)
self.request_duration = Histogram(
'mcp_request_duration_seconds',
'MCP request duration',
['server_name', 'tool_name']
)
self.active_connections = Gauge(
'mcp_active_connections',
'Active MCP connections',
['server_name']
)
self.tool_availability = Gauge(
'mcp_tool_availability',
'Tool availability status',
['server_name', 'tool_name']
)
# Structured logging
self.logger = structlog.get_logger()
# Distributed tracing
self.setup_tracing()
def setup_tracing(self):
trace.set_tracer_provider(TracerProvider())
tracer = trace.get_tracer(__name__)
jaeger_exporter = JaegerExporter(
agent_host_name="jaeger-agent",
agent_port=6831,
)
span_processor = BatchSpanProcessor(jaeger_exporter)
trace.get_tracer_provider().add_span_processor(span_processor)
def record_request(
self,
server_name: str,
tool_name: str,
duration: float,
status: str,
user_id: str = None,
trace_id: str = None
):
# Prometheus metrics
self.request_count.labels(
server_name=server_name,
tool_name=tool_name,
status=status
).inc()
self.request_duration.labels(
server_name=server_name,
tool_name=tool_name
).observe(duration)
# Structured log
self.logger.info(
"mcp_request_completed",
server_name=server_name,
tool_name=tool_name,
duration=duration,
status=status,
user_id=user_id,
trace_id=trace_id
)
def update_tool_availability(
self,
server_name: str,
tool_name: str,
available: bool
):
self.tool_availability.labels(
server_name=server_name,
tool_name=tool_name
).set(1 if available else 0)
# Health check implementation
class HealthChecker:
def __init__(self, mcp_clients: Dict[str, MCPClient]):
self.mcp_clients = mcp_clients
self.health_status = {}
async def check_all_servers(self) -> Dict[str, bool]:
"""Check health of all MCP servers"""
health_results = {}
for server_name, client in self.mcp_clients.items():
try:
# Attempt to list tools (lightweight health check)
await asyncio.wait_for(
client.list_tools(),
timeout=5.0
)
health_results[server_name] = True
except Exception as e:
health_results[server_name] = False
self.logger.error(
"mcp_server_health_check_failed",
server_name=server_name,
error=str(e)
)
self.health_status = health_results
return health_results
async def continuous_health_monitoring(self):
"""Run continuous health checks"""
while True:
await self.check_all_servers()
await asyncio.sleep(30) # Check every 30 seconds
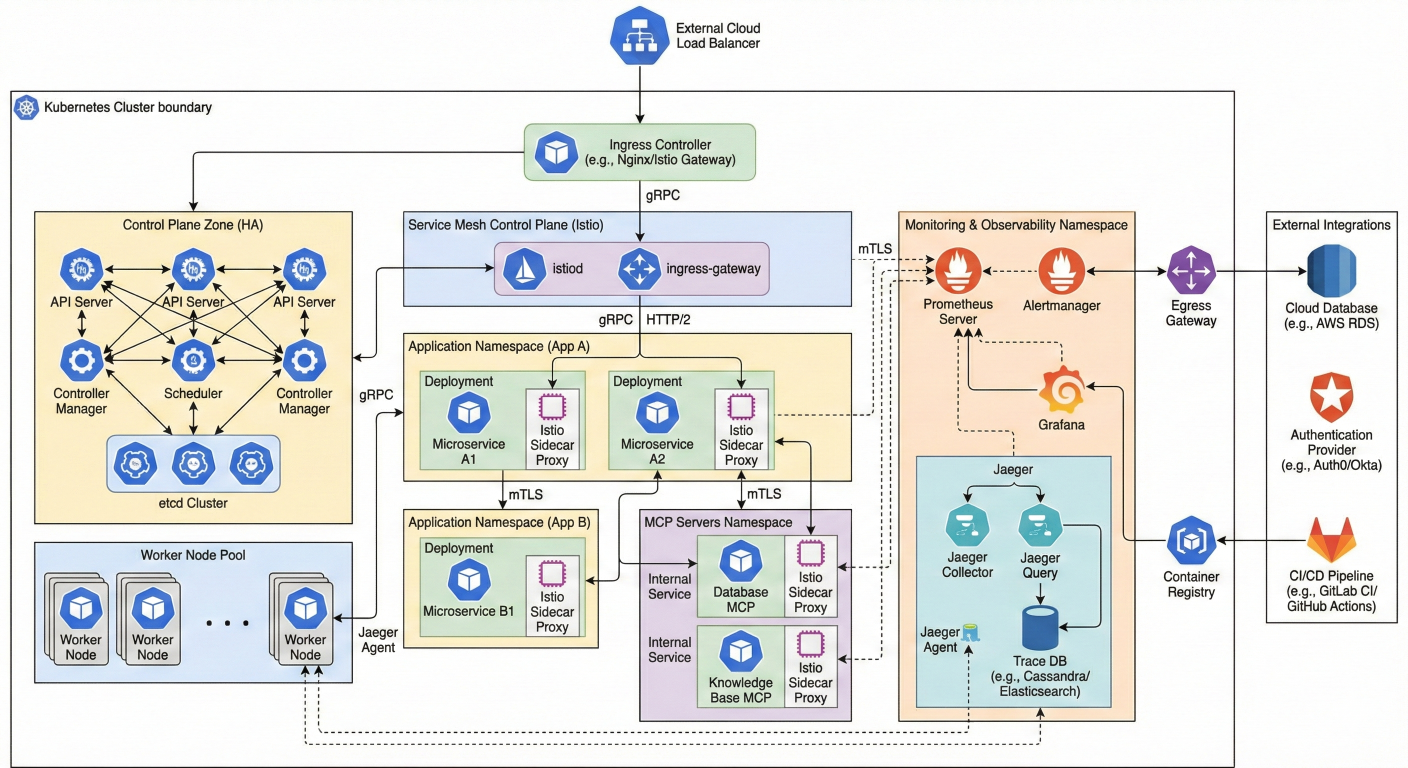
Production Deployment Architecture: Show Kubernetes cluster with MCP servers, load balancers, monitoring stack (Prometheus, Grafana, Jaeger), service mesh, and external integrations
Enterprise MCP deployments require multi-layered security approaches that protect against various threat vectors while maintaining usability and performance. The security framework must address authentication, authorization, input validation, network security, and audit requirements.
Defense-in-Depth Security Model
from cryptography.fernet import Fernet
from cryptography.hazmat.primitives import hashes
from cryptography.hazmat.primitives.kdf.pbkdf2 import PBKDF2HMAC
from cryptography.hazmat.backends import default_backend
import jwt
import hashlib
import time
from typing import Dict, List, Optional, Any
from dataclasses import dataclass
from enum import Enum
class ThreatLevel(Enum):
LOW = "low"
MEDIUM = "medium"
HIGH = "high"
CRITICAL = "critical"
@dataclass
class SecurityContext:
user_id: str
session_id: str
permissions: List[str]
risk_score: float
geo_location: Optional[str]
device_fingerprint: Optional[str]
threat_indicators: List[str]
class ComprehensiveSecurityFramework:
def __init__(self, config: SecurityConfig):
self.config = config
self.threat_detector = ThreatDetector(config.threat_detection)
self.access_controller = AccessController(config.access_control)
self.audit_logger = AuditLogger(config.audit)
self.crypto_manager = CryptoManager(config.encryption)
async def secure_request_pipeline(
self,
request: MCPRequest,
security_context: SecurityContext
) -> SecureRequestResult:
"""Complete security pipeline for MCP requests"""
# 1. Threat detection and risk assessment
threat_assessment = await self.threat_detector.assess_request(
request, security_context
)
if threat_assessment.threat_level == ThreatLevel.CRITICAL:
await self.audit_logger.log_security_event(
'request_blocked_critical_threat',
security_context.user_id,
{
'threat_indicators': threat_assessment.indicators,
'request_details': request.sanitized_summary()
}
)
raise SecurityException("Request blocked due to critical threat indicators")
# 2. Enhanced access control
access_decision = await self.access_controller.evaluate_access(
request, security_context, threat_assessment
)
if not access_decision.permitted:
await self.audit_logger.log_access_denied(
security_context.user_id,
request.tool_name,
access_decision.denial_reason
)
raise AuthorizationException(access_decision.denial_reason)
# 3. Input validation and sanitization
sanitized_request = await self.sanitize_and_validate_input(
request, threat_assessment
)
# 4. Apply runtime security controls
monitored_request = await self.apply_runtime_controls(
sanitized_request,
security_context,
access_decision
)
return SecureRequestResult(
request=monitored_request,
security_context=security_context,
access_decision=access_decision,
threat_assessment=threat_assessment
)
class ThreatDetector:
def __init__(self, config: ThreatDetectionConfig):
self.config = config
self.ml_model = self.load_threat_detection_model()
self.known_attack_patterns = self.load_attack_patterns()
async def assess_request(
self,
request: MCPRequest,
context: SecurityContext
) -> ThreatAssessment:
"""Comprehensive threat assessment using multiple detection methods"""
indicators = []
risk_score = 0.0
# 1. Pattern-based detection
pattern_indicators = self.detect_attack_patterns(request)
indicators.extend(pattern_indicators)
risk_score += len(pattern_indicators) * 0.2
# 2. Behavioral analysis
behavioral_risk = await self.analyze_user_behavior(
context.user_id, request
)
risk_score += behavioral_risk
if behavioral_risk > 0.7:
indicators.append("unusual_user_behavior")
# 3. ML-based anomaly detection
ml_risk = await self.ml_anomaly_detection(request, context)
risk_score += ml_risk
if ml_risk > 0.8:
indicators.append("ml_anomaly_detected")
# 4. Geographic and temporal analysis
geo_risk = self.analyze_geographic_anomalies(context)
temporal_risk = self.analyze_temporal_patterns(context, request)
risk_score += geo_risk + temporal_risk
if geo_risk > 0.5:
indicators.append("geographic_anomaly")
if temporal_risk > 0.5:
indicators.append("temporal_anomaly")
# Determine threat level
threat_level = self.calculate_threat_level(risk_score, indicators)
return ThreatAssessment(
threat_level=threat_level,
risk_score=min(risk_score, 1.0),
indicators=indicators,
confidence=self.calculate_confidence(indicators, risk_score)
)
def detect_attack_patterns(self, request: MCPRequest) -> List[str]:
"""Detect known attack patterns in request"""
indicators = []
request_text = str(request).lower()
# Prompt injection patterns
injection_patterns = [
r'ignore\s+previous\s+instructions',
r'forget\s+everything',
r'system\s*:\s*you\s+are',
r'\\n\\n#\s*new\s+instructions',
r'jailbreak\s+mode',
r'developer\s+mode',
r'god\s+mode'
]
for pattern in injection_patterns:
if re.search(pattern, request_text):
indicators.append(f"prompt_injection:{pattern}")
# Code injection patterns
code_patterns = [
r'eval\s*\(',
r'exec\s*\(',
r'__import__\s*\(',
r'subprocess\.',
r'os\.system',
r'shell\s*=\s*true'
]
for pattern in code_patterns:
if re.search(pattern, request_text):
indicators.append(f"code_injection:{pattern}")
# Data exfiltration patterns
exfil_patterns = [
r'dump\s+all\s+data',
r'export\s+database',
r'select\s+\*\s+from',
r'show\s+tables',
r'describe\s+\w+'
]
for pattern in exfil_patterns:
if re.search(pattern, request_text):
indicators.append(f"data_exfiltration:{pattern}")
return indicators
class AccessController:
def __init__(self, config: AccessControlConfig):
self.config = config
self.policy_engine = PolicyEngine(config.policies)
self.permission_cache = PermissionCache(config.cache)
async def evaluate_access(
self,
request: MCPRequest,
context: SecurityContext,
threat_assessment: ThreatAssessment
) -> AccessDecision:
"""Comprehensive access control evaluation"""
# 1. Basic permission check
basic_permission = await self.check_basic_permissions(
context.user_id, request.tool_name, request.parameters
)
if not basic_permission.granted:
return AccessDecision(
permitted=False,
denial_reason=basic_permission.reason,
required_permissions=basic_permission.missing_permissions
)
# 2. Risk-based access control
risk_decision = await self.evaluate_risk_based_access(
context, threat_assessment, request
)
if not risk_decision.permitted:
return risk_decision
# 3. Context-aware restrictions
contextual_decision = await self.apply_contextual_restrictions(
request, context, threat_assessment
)
if not contextual_decision.permitted:
return contextual_decision
# 4. Resource-level authorization
resource_decision = await self.check_resource_access(
context, request.parameters
)
return resource_decision
async def evaluate_risk_based_access(
self,
context: SecurityContext,
threat_assessment: ThreatAssessment,
request: MCPRequest
) -> AccessDecision:
"""Apply risk-based access controls"""
# High-risk requests require additional validation
if threat_assessment.threat_level in [ThreatLevel.HIGH, ThreatLevel.CRITICAL]:
# Check if user has high-risk operation permissions
has_high_risk_permission = await self.policy_engine.check_permission(
context.user_id,
f"high_risk_operations:{request.tool_name}"
)
if not has_high_risk_permission:
return AccessDecision(
permitted=False,
denial_reason="High-risk operation requires elevated permissions",
required_permissions=[f"high_risk_operations:{request.tool_name}"]
)
# Require MFA for critical operations
if threat_assessment.threat_level == ThreatLevel.CRITICAL:
mfa_verified = await self.verify_mfa_requirement(context)
if not mfa_verified:
return AccessDecision(
permitted=False,
denial_reason="Multi-factor authentication required for critical operations",
additional_auth_required=True
)
return AccessDecision(permitted=True)
class ComplianceFramework:
def __init__(self, regulations: List['str']):
self.regulations = regulations
self.compliance_rules = self.load_compliance_rules()
self.audit_requirements = self.load_audit_requirements()
async def ensure_compliance(
self,
request: MCPRequest,
context: SecurityContext,
response: Any
) -> ComplianceResult:
"""Ensure request and response meet all compliance requirements"""
compliance_checks = []
# GDPR compliance checks
if 'GDPR' in self.regulations:
gdpr_check = await self.check_gdpr_compliance(request, context, response)
compliance_checks.append(gdpr_check)
# HIPAA compliance checks
if 'HIPAA' in self.regulations:
hipaa_check = await self.check_hipaa_compliance(request, context, response)
compliance_checks.append(hipaa_check)
# SOX compliance checks
if 'SOX' in self.regulations:
sox_check = await self.check_sox_compliance(request, context, response)
compliance_checks.append(sox_check)
# PCI DSS compliance checks
if 'PCI_DSS' in self.regulations:
pci_check = await self.check_pci_compliance(request, context, response)
compliance_checks.append(pci_check)
# Aggregate results
overall_compliant = all(check.compliant for check in compliance_checks)
violations = [check for check in compliance_checks if not check.compliant]
return ComplianceResult(
compliant=overall_compliant,
violations=violations,
audit_trail=self.generate_audit_trail(request, context, compliance_checks),
retention_requirements=self.calculate_retention_requirements(compliance_checks)
)
async def check_gdpr_compliance(
self,
request: MCPRequest,
context: SecurityContext,
response: Any
) -> ComplianceCheck:
"""Check GDPR compliance requirements"""
violations = []
# Check for personal data processing
if self.contains_personal_data(request.parameters):
# Verify lawful basis
lawful_basis = await self.verify_lawful_basis(
context.user_id,
request.tool_name
)
if not lawful_basis:
violations.append("No lawful basis for processing personal data")
# Check data minimization
if not self.meets_data_minimization(request.parameters):
violations.append("Request violates data minimization principle")
# Verify consent if required
if lawful_basis == 'consent':
consent_valid = await self.verify_consent(
context.user_id,
request.tool_name
)
if not consent_valid:
violations.append("Valid consent not found for personal data processing")
# Check for data subject rights
if self.is_data_subject_request(request):
if not await self.can_fulfill_data_subject_request(request, context):
violations.append("Cannot fulfill data subject rights request")
return ComplianceCheck(
regulation="GDPR",
compliant=len(violations) == 0,
violations=violations,
requirements_met=self.gdpr_requirements_met(request, context),
evidence=self.collect_gdpr_evidence(request, context, response)
)
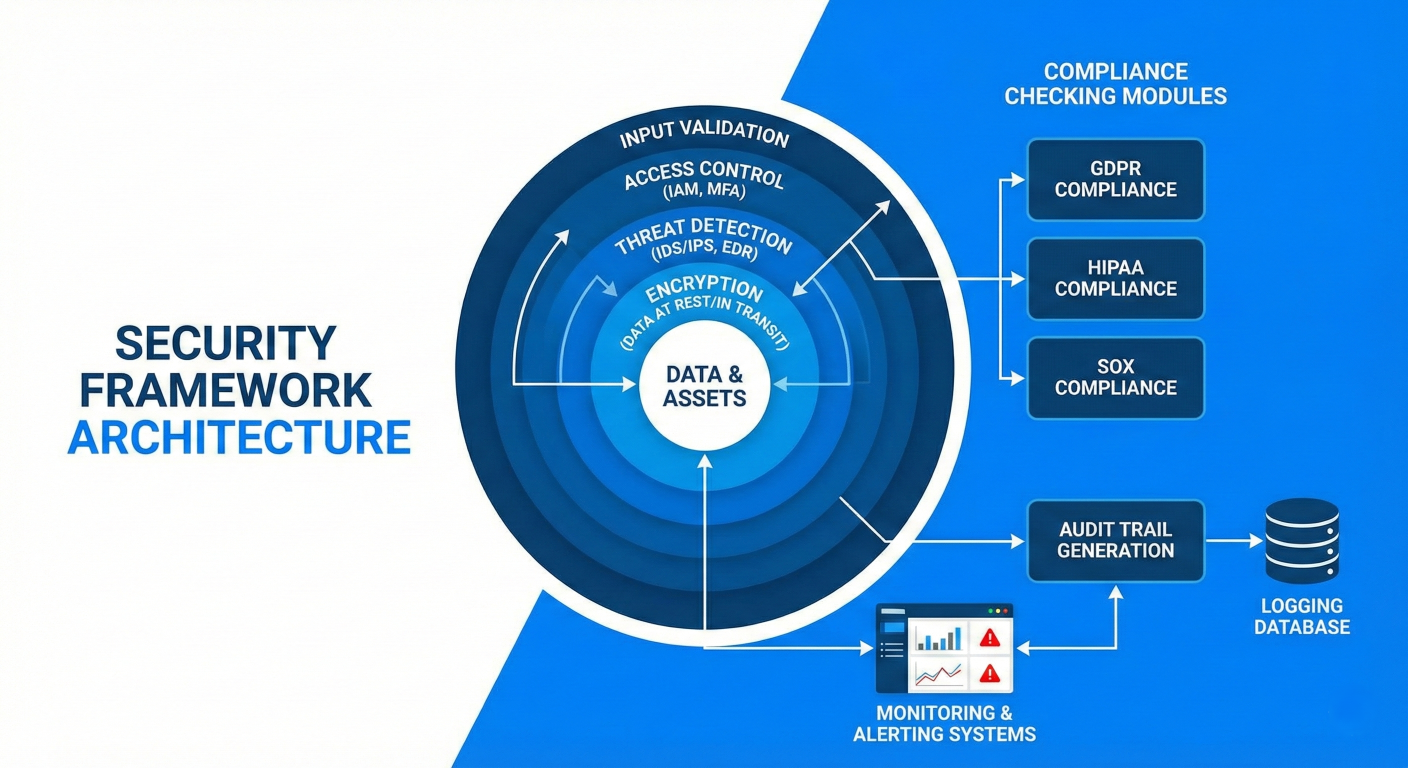
Security Framework Architecture: Show defense-in-depth layers (threat detection, access control, input validation, encryption), compliance checking modules (GDPR, HIPAA, SOX), audit trail generation, and monitoring/alerting systems
Comprehensive Audit Trail System
from typing import Dict, List, Any, Optional
from dataclasses import dataclass, asdict
from datetime import datetime, timedelta
import json
import hashlib
from cryptography.hazmat.primitives import serialization, hashes
from cryptography.hazmat.primitives.asymmetric import rsa, padding
@dataclass
class AuditEvent:
event_id: str
timestamp: datetime
user_id: str
session_id: str
event_type: str
resource: str
action: str
outcome: str
risk_score: float
ip_address: str
user_agent: str
request_details: Dict[str, Any]
response_summary: Dict[str, Any]
compliance_tags: List[str]
retention_period: int # days
hash_chain_previous: Optional[str] = None
digital_signature: Optional[str] = None
class AuditLogger:
def __init__(self, config: AuditConfig):
self.config = config
self.storage = AuditStorage(config.storage)
self.crypto = AuditCrypto(config.encryption)
self.previous_hash = None
async def log_mcp_request(
self,
request: MCPRequest,
context: SecurityContext,
response: MCPResponse,
compliance_result: ComplianceResult
) -> str:
"""Log MCP request with full audit trail"""
event = AuditEvent(
event_id=self.generate_event_id(),
timestamp=datetime.utcnow(),
user_id=context.user_id,
session_id=context.session_id,
event_type="mcp_request",
resource=f"mcp://{request.server_name}/{request.tool_name}",
action=request.action,
outcome="success" if response.success else "failure",
risk_score=context.risk_score,
ip_address=request.client_ip,
user_agent=request.user_agent,
request_details=self.sanitize_request_details(request),
response_summary=self.create_response_summary(response),
compliance_tags=compliance_result.applicable_regulations,
retention_period=compliance_result.retention_requirements.days,
hash_chain_previous=self.previous_hash
)
# Create hash chain for integrity
event_hash = self.create_event_hash(event)
self.previous_hash = event_hash
# Digital signature for non-repudiation
event.digital_signature = await self.crypto.sign_event(event)
# Store with encryption
await self.storage.store_event(event)
# Real-time compliance reporting
if self.requires_immediate_reporting(event):
await self.send_compliance_alert(event)
return event.event_id
async def generate_compliance_report(
self,
regulation: str,
start_date: datetime,
end_date: datetime,
include_personal_data: bool = False
) -> ComplianceReport:
"""Generate comprehensive compliance report"""
# Retrieve relevant audit events
events = await self.storage.query_events({
'compliance_tags': regulation,
'timestamp_range': (start_date, end_date)
})
# Analyze compliance metrics
metrics = await self.calculate_compliance_metrics(events, regulation)
# Identify violations and risks
violations = await self.identify_compliance_violations(events, regulation)
# Generate remediation recommendations
recommendations = await self.generate_remediation_plan(violations)
# Create executive summary
executive_summary = self.create_executive_summary(
metrics, violations, recommendations
)
report = ComplianceReport(
regulation=regulation,
period=(start_date, end_date),
generated_at=datetime.utcnow(),
executive_summary=executive_summary,
metrics=metrics,
violations=violations,
recommendations=recommendations,
supporting_evidence=self.collect_supporting_evidence(events),
certification_status=self.assess_certification_status(metrics, violations)
)
# Digital signature for report integrity
report.digital_signature = await self.crypto.sign_report(report)
return report
async def calculate_compliance_metrics(
self,
events: List[AuditEvent],
regulation: str
) -> Dict[str, Any]:
"""Calculate key compliance metrics"""
if regulation == "GDPR":
return await self.calculate_gdpr_metrics(events)
elif regulation == "HIPAA":
return await self.calculate_hipaa_metrics(events)
elif regulation == "SOX":
return await self.calculate_sox_metrics(events)
else:
return await self.calculate_general_metrics(events)
async def calculate_gdpr_metrics(self, events: List[AuditEvent]) -> Dict[str, Any]:
"""Calculate GDPR-specific compliance metrics"""
total_events = len(events)
personal_data_events = [e for e in events if self.involves_personal_data(e)]
# Data subject requests
dsr_events = [e for e in events if e.event_type == "data_subject_request"]
dsr_response_times = [
self.calculate_response_time(e) for e in dsr_events
]
# Consent management
consent_events = [e for e in events if "consent" in e.request_details]
consent_withdrawal_events = [
e for e in consent_events
if e.request_details.get("action") == "withdraw"
]
# Data breaches
breach_events = [e for e in events if e.event_type == "security_incident"]
return {
"total_personal_data_processing_events": len(personal_data_events),
"data_subject_requests": {
"total": len(dsr_events),
"average_response_time_hours": sum(dsr_response_times) / len(dsr_response_times) if dsr_response_times else 0,
"within_72_hours": len([t for t in dsr_response_times if t <= 72]),
"compliance_rate": len([t for t in dsr_response_times if t <= 72]) / len(dsr_response_times) if dsr_response_times else 1.0
},
"consent_management": {
"consent_recorded": len(consent_events),
"consent_withdrawn": len(consent_withdrawal_events),
"withdrawal_rate": len(consent_withdrawal_events) / len(consent_events) if consent_events else 0
},
"data_minimization": {
"compliant_requests": len([e for e in personal_data_events if self.meets_data_minimization(e)]),
"compliance_rate": len([e for e in personal_data_events if self.meets_data_minimization(e)]) / len(personal_data_events) if personal_data_events else 1.0
},
"security_incidents": {
"total_breaches": len(breach_events),
"notified_within_72_hours": len([e for e in breach_events if self.notified_within_72_hours(e)]),
"notification_compliance_rate": len([e for e in breach_events if self.notified_within_72_hours(e)]) / len(breach_events) if breach_events else 1.0
},
"data_retention": {
"retention_policy_compliance": await self.check_retention_compliance(personal_data_events),
"automatic_deletion_events": len([e for e in events if e.event_type == "automatic_deletion"])
}
}
# Compliance reporting dashboard
class ComplianceDashboard:
def __init__(self, audit_logger: AuditLogger):
self.audit_logger = audit_logger
async def generate_real_time_dashboard(self) -> Dict[str, Any]:
"""Generate real-time compliance dashboard"""
now = datetime.utcnow()
last_30_days = now - timedelta(days=30)
# Get recent events
recent_events = await self.audit_logger.storage.query_events({
'timestamp_range': (last_30_days, now)
})
# Calculate key metrics
metrics = {
"overview": {
"total_events": len(recent_events),
"unique_users": len(set(e.user_id for e in recent_events)),
"success_rate": len([e for e in recent_events if e.outcome == "success"]) / len(recent_events) if recent_events else 1.0,
"average_risk_score": sum(e.risk_score for e in recent_events) / len(recent_events) if recent_events else 0.0
},
"security": {
"high_risk_events": len([e for e in recent_events if e.risk_score > 0.7]),
"failed_authentications": len([e for e in recent_events if e.event_type == "authentication" and e.outcome == "failure"]),
"policy_violations": len([e for e in recent_events if "policy_violation" in e.compliance_tags])
},
"compliance_by_regulation": {}
}
# Compliance status by regulation
regulations = ["GDPR", "HIPAA", "SOX", "PCI_DSS"]
for regulation in regulations:
reg_events = [e for e in recent_events if regulation in e.compliance_tags]
if reg_events:
violations = await self.audit_logger.identify_compliance_violations(reg_events, regulation)
metrics["compliance_by_regulation"][regulation] = {
"total_events": len(reg_events),
"violations": len(violations),
"compliance_rate": (len(reg_events) - len(violations)) / len(reg_events)
}
return metrics
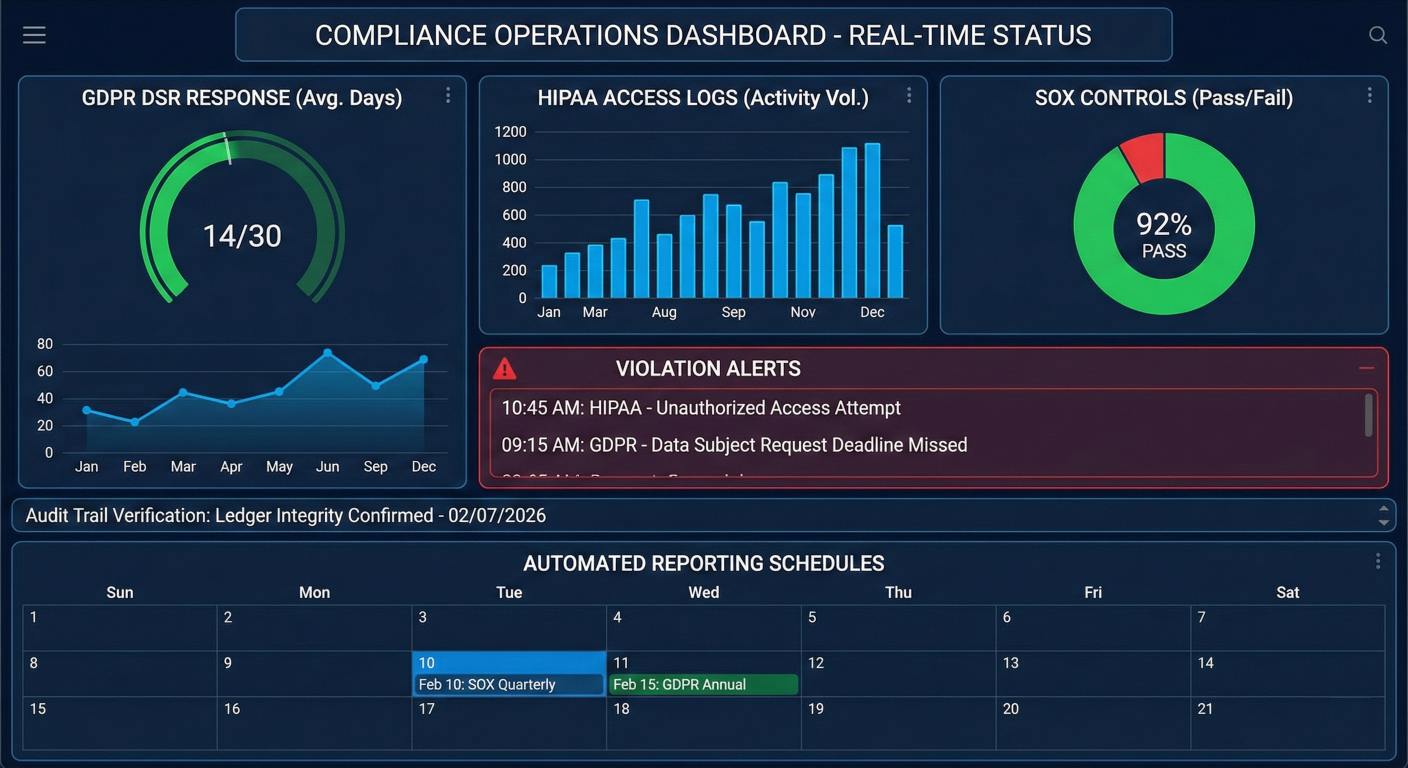
Compliance Dashboard: Show real-time metrics (GDPR data subject request response times, HIPAA access logs, SOX financial data controls), violation alerts, audit trail integrity verification, and automated reporting schedules
The MCP ecosystem continues evolving rapidly, with new patterns emerging for agentic workflows, federated deployments, and edge computing integration. Understanding these trends enables organizations to build forward-compatible architectures.
Federated MCP Networks
# Your federated MCP network implementation
from typing import Dict, List, Any, Optional
from dataclasses import dataclass
from enum import Enum
import asyncio
import aiohttp
from cryptography.hazmat.primitives import hashes
from cryptography.hazmat.primitives.asymmetric import rsa, padding
class FederationRole(Enum):
HUB = "hub" # Central coordination
SPOKE = "spoke" # Edge deployment
PEER = "peer" # Equal participant
@dataclass
class FederatedEndpoint:
node_id: str
role: FederationRole
endpoint_url: str
capabilities: List[str]
trust_level: float
last_heartbeat: Optional[datetime]
public_key: bytes
region: str
compliance_certifications: List[str]
class FederatedMCPNetwork:
"""Manages federated network of MCP deployments across regions/organizations"""
def __init__(self, node_config: FederatedNodeConfig):
self.node_id = node_config.node_id
self.role = node_config.role
self.capabilities = node_config.capabilities
self.trust_manager = TrustManager(node_config.trust)
self.routing_table = FederatedRoutingTable()
self.consensus_manager = ConsensusManager(node_config.consensus)
self.known_nodes = {}
async def join_federation(self, bootstrap_nodes: List[str]) -> bool:
"""Join existing federated network"""
# Discover network topology
network_map = await self.discover_network_topology(bootstrap_nodes)
# Establish trust relationships
trust_established = await self.establish_trust_relationships(network_map)
if not trust_established:
raise FederationException("Failed to establish sufficient trust relationships")
# Register capabilities with network
await self.register_node_capabilities()
# Start participating in consensus
await self.consensus_manager.start_participation()
# Begin heartbeat process
asyncio.create_task(self.heartbeat_loop())
return True
async def route_federated_request(
self,
request: MCPRequest,
routing_constraints: Dict[str, Any]
) -> MCPResponse:
"""Route request across federated network"""
# Find capable nodes
capable_nodes = await self.find_capable_nodes(
request.tool_name,
request.parameters,
routing_constraints
)
if not capable_nodes:
raise RoutingException(f"No capable nodes found for {request.tool_name}")
# Apply routing policy
selected_node = await self.select_optimal_node(
capable_nodes,
routing_constraints
)
# Execute with failover
try:
response = await self.execute_remote_request(selected_node, request)
# Update node performance metrics
await self.update_node_metrics(selected_node.node_id, response)
return response
except Exception as e:
# Attempt failover to backup nodes
return await self.execute_with_failover(
capable_nodes[1:], request, original_error=e
)
async def find_capable_nodes(
self,
tool_name: str,
parameters: Dict[str, Any],
constraints: Dict[str, Any]
) -> List[FederatedEndpoint]:
"""Find nodes capable of handling specific request"""
capable_nodes = []
for node in self.known_nodes.values():
# Check basic capability
if tool_name not in node.capabilities:
continue
# Check compliance requirements
required_certs = constraints.get('compliance_certifications', [])
if not set(required_certs).issubset(set(node.compliance_certifications)):
continue
# Check geographic constraints
if 'region' in constraints:
if constraints['region'] != node.region:
continue
# Check data residency requirements
if 'data_residency' in constraints:
allowed_regions = constraints['data_residency']
if node.region not in allowed_regions:
continue
# Check trust level
min_trust = constraints.get('min_trust_level', 0.5)
if node.trust_level < min_trust:
continue
# Verify node is responsive
if await self.verify_node_health(node):
capable_nodes.append(node)
return capable_nodes
async def establish_cross_organizational_governance(
self,
participating_organizations: List["str"]
) -> GovernanceFramework:
"""Establish governance framework for cross-org federation"""
# Define shared policies
shared_policies = await self.negotiate_shared_policies(
participating_organizations
)
# Establish audit framework
audit_framework = await self.create_federated_audit_framework(
participating_organizations
)
# Create compliance mapping
compliance_mapping = await self.map_regulatory_requirements(
participating_organizations
)
# Set up dispute resolution
dispute_resolution = await self.establish_dispute_resolution(
participating_organizations
)
return GovernanceFramework(
shared_policies=shared_policies,
audit_framework=audit_framework,
compliance_mapping=compliance_mapping,
dispute_resolution=dispute_resolution,
participating_orgs=participating_organizations
)
class EdgeMCPDeployment:
"""Edge computing deployment for low-latency MCP services"""
def __init__(self, edge_config: EdgeConfig):
self.edge_config = edge_config
self.local_cache = EdgeCache(edge_config.cache)
self.sync_manager = EdgeSyncManager(edge_config.sync)
self.offline_capabilities = OfflineCapabilityManager()
async def deploy_edge_servers(
self,
geographic_regions: List[str],
capability_requirements: Dict[str, List[str]]
) -> Dict[str, EdgeDeployment]:
"""Deploy MCP servers to edge locations"""
deployments = {}
for region in geographic_regions:
# Determine optimal edge locations
edge_locations = await self.find_optimal_edge_locations(
region,
capability_requirements[region]
)
for location in edge_locations:
# Deploy lightweight MCP servers
deployment = await self.deploy_to_edge_location(
location,
capability_requirements[region]
)
# Configure local caching
await self.configure_edge_caching(deployment, region)
# Set up sync with central hub
await self.configure_hub_synchronization(deployment)
deployments[f"{region}-{location.id}"] = deployment
return deployments
async def handle_offline_scenarios(
self,
request: MCPRequest,
available_capabilities: List[str]
) -> MCPResponse:
"""Handle requests when disconnected from central hub"""
# Check if request can be handled locally
if request.tool_name in available_capabilities:
# Use local cached data
cached_data = await self.local_cache.get_relevant_data(request)
if cached_data and not self.requires_real_time_data(request):
return await self.process_with_cached_data(request, cached_data)
# Queue for later processing
await self.offline_capabilities.queue_request(request)
# Return best-effort response if possible
if self.can_provide_fallback_response(request):
return await self.generate_fallback_response(request)
# Return offline notice
return MCPResponse(
success=False,
error="Service temporarily offline - request queued for processing",
metadata={
"queued": True,
"estimated_processing_time": "when connectivity restored"
}
)
Advanced Agent Mesh Architectures
# Advanced multi-agent coordination with mesh networking
class AgentMeshNetwork:
"""Advanced multi-agent coordination with mesh networking"""
def __init__(self, mesh_config: MeshConfig):
self.mesh_config = mesh_config
self.service_discovery = MeshServiceDiscovery()
self.load_balancer = AgentLoadBalancer()
self.circuit_breaker = CircuitBreakerManager()
self.mesh_security = MeshSecurity(mesh_config.security)
async def create_agent_mesh(
self,
agent_specifications: List[AgentSpec]
) -> MeshTopology:
"""Create mesh network of specialized agents"""
mesh_topology = MeshTopology()
# Deploy agents with mesh networking
for spec in agent_specifications:
# Create agent with mesh capabilities
agent = await self.create_mesh_agent(spec)
# Register with service discovery
await self.service_discovery.register_agent(agent)
# Configure traffic policies
await self.configure_traffic_policies(agent, spec.traffic_policy)
# Set up health checking
await self.setup_health_monitoring(agent)
mesh_topology.add_agent(agent)
# Configure inter-agent communication patterns
await self.configure_communication_patterns(mesh_topology)
# Enable service mesh features
await self.enable_mesh_features(mesh_topology)
return mesh_topology
async def configure_communication_patterns(
self,
mesh: MeshTopology
):
"""Configure sophisticated agent communication patterns"""
# Request-response patterns
await self.configure_request_response_patterns(mesh)
# Publish-subscribe patterns
await self.configure_pubsub_patterns(mesh)
# Event sourcing patterns
await self.configure_event_sourcing(mesh)
# Saga patterns for distributed transactions
await self.configure_saga_patterns(mesh)
async def implement_advanced_routing(
self,
mesh: MeshTopology
) -> AdvancedRouter:
"""Implement advanced routing capabilities"""
router = AdvancedRouter()
# Traffic splitting for A/B testing
await router.configure_traffic_splitting({
'agent_v1': 0.7,
'agent_v2': 0.3
})
# Canary deployments
await router.configure_canary_routing({
'canary_version': 'v2',
'stable_version': 'v1',
'canary_percentage': 10,
'success_criteria': {
'error_rate': '<1%',
'response_time_p95': '<500ms'
}
})
# Intelligent load balancing
await router.configure_intelligent_load_balancing({
'algorithm': 'least_loaded_with_capability_awareness',
'health_check_interval': 30,
'failure_threshold': 3
})
# Circuit breaker patterns
await router.configure_circuit_breakers({
'failure_threshold': 5,
'recovery_timeout': 60,
'half_open_max_calls': 3
})
# Advanced orchestration for complex AI workflows
class AIWorkflowOrchestrator:
"""Advanced orchestration for complex AI workflows"""
def __init__(self, orchestrator_config: OrchestratorConfig):
self.config = orchestrator_config
self.workflow_engine = WorkflowEngine()
self.state_manager = DistributedStateManager()
self.compensation_manager = CompensationManager()
async def create_complex_workflow(
self,
workflow_definition: WorkflowDefinition
) -> Workflow:
"""Create complex AI workflow with advanced patterns"""
workflow = await self.workflow_engine.create_workflow(workflow_definition)
# Configure error handling and compensation
await self.configure_error_handling(workflow)
# Set up state management
await self.configure_state_management(workflow)
# Configure monitoring and observability
await self.configure_workflow_monitoring(workflow)
return workflow
async def execute_adaptive_workflow(
self,
workflow: Workflow,
initial_context: Dict[str, Any]
) -> WorkflowResult:
"""Execute workflow with adaptive behavior"""
execution_context = ExecutionContext(
workflow_id=workflow.id,
initial_context=initial_context,
adaptation_strategy=self.config.adaptation_strategy
)
# Start execution with monitoring
execution = await self.workflow_engine.start_execution(
workflow,
execution_context
)
# Monitor and adapt during execution
async for step_result in execution:
# Analyze step performance
performance_metrics = await self.analyze_step_performance(step_result)
# Determine if adaptation is needed
if await self.requires_adaptation(performance_metrics, execution_context):
# Apply adaptive changes
adaptation = await self.determine_adaptation(
performance_metrics,
execution_context
)
await self.apply_workflow_adaptation(execution, adaptation)
# Update execution context
execution_context.update_from_step_result(step_result)
# Collect final results
final_result = await execution.get_final_result()
return WorkflowResult(
workflow_id=workflow.id,
execution_id=execution.id,
result=final_result,
performance_metrics=await self.collect_execution_metrics(execution),
adaptations_applied=execution_context.adaptations_applied
)
return router
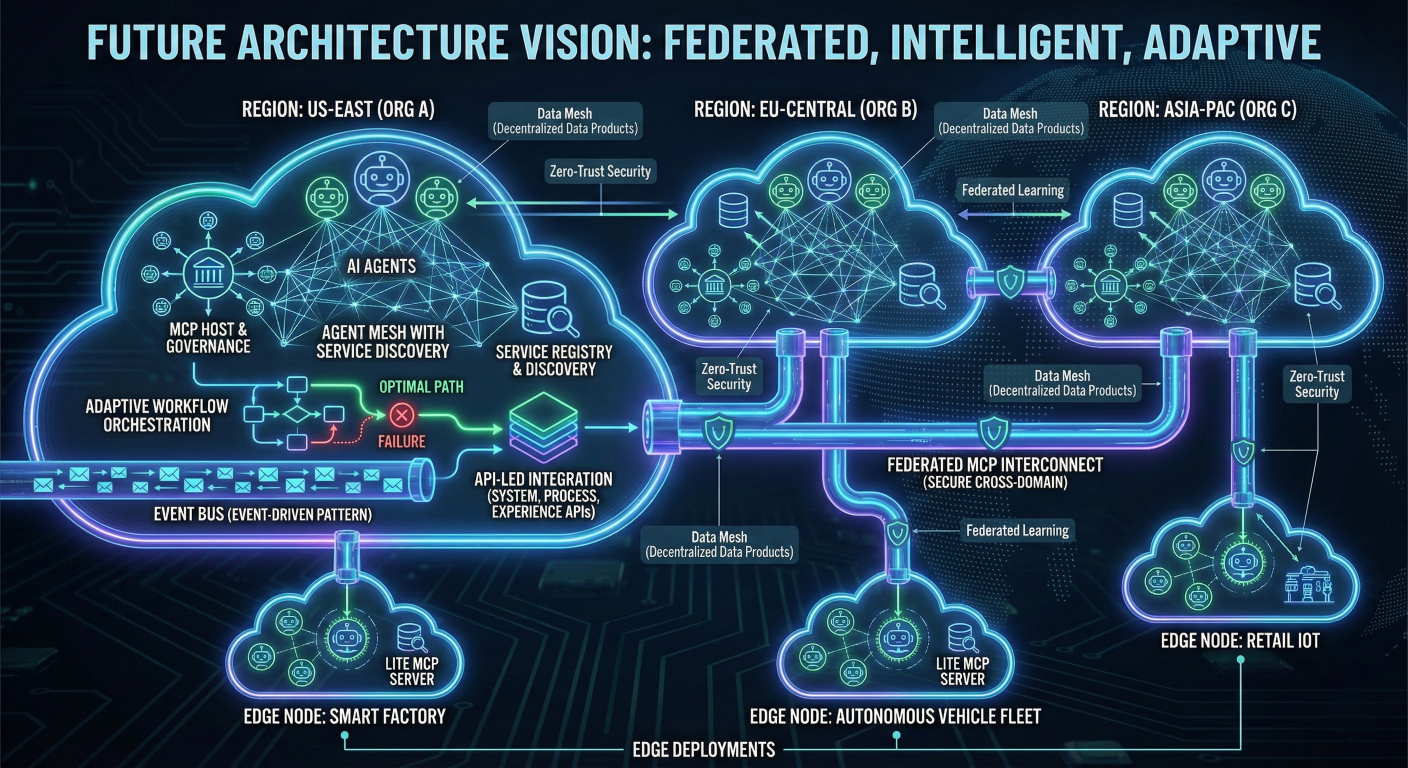
Future Architecture Vision: Show federated MCP networks across regions/organizations, edge deployments, agent mesh with service discovery, adaptive workflow orchestration, and emerging integration patterns
Advanced Caching and Optimization
import asyncio
import hashlib
import pickle
from typing import Dict, List, Any, Optional, Tuple
from dataclasses import dataclass
from datetime import datetime, timedelta
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
@dataclass
class CacheEntry:
key: str
value: Any
created_at: datetime
last_accessed: datetime
access_count: int
ttl: Optional[int]
tags: List[str]
similarity_vector: Optional[np.ndarray]
class IntelligentMCPCache:
"""Advanced caching system with semantic similarity and predictive prefetching"""
def __init__(self, cache_config: CacheConfig):
self.config = cache_config
self.cache_store = {}
self.access_patterns = AccessPatternAnalyzer()
self.similarity_index = SimilarityIndex()
self.prefetch_predictor = PrefetchPredictor()
async def get_with_semantic_fallback(
self,
cache_key: str,
query_vector: Optional[np.ndarray] = None,
similarity_threshold: float = 0.85
) -> Optional[CacheEntry]:
"""Get cached value with semantic similarity fallback"""
# Try exact match first
if cache_key in self.cache_store:
entry = self.cache_store[cache_key]
entry.last_accessed = datetime.utcnow()
entry.access_count += 1
return entry
# Try semantic similarity match if vector provided
if query_vector is not None:
similar_entries = await self.find_similar_entries(
query_vector,
similarity_threshold
)
if similar_entries:
best_match = similar_entries[0]
best_match.last_accessed = datetime.utcnow()
best_match.access_count += 1
# Log semantic cache hit for analysis
await self.log_semantic_cache_hit(cache_key, best_match.key)
return best_match
# Cache miss - trigger predictive prefetch
await self.trigger_predictive_prefetch(cache_key, query_vector)
return None
async def store_with_intelligence(
self,
cache_key: str,
value: Any,
metadata: Dict[str, Any],
query_vector: Optional[np.ndarray] = None
):
"""Store value with intelligent caching decisions"""
# Analyze value importance
importance_score = await self.calculate_importance_score(
cache_key, value, metadata
)
# Determine optimal TTL
optimal_ttl = await self.calculate_optimal_ttl(
cache_key, metadata, importance_score
)
# Create cache entry
entry = CacheEntry(
key=cache_key,
value=value,
created_at=datetime.utcnow(),
last_accessed=datetime.utcnow(),
access_count=1,
ttl=optimal_ttl,
tags=metadata.get('tags', []),
similarity_vector=query_vector
)
# Check if we need to evict entries
if len(self.cache_store) >= self.config.max_entries:
await self.intelligent_eviction()
# Store entry
self.cache_store[cache_key] = entry
# Update similarity index
if query_vector is not None:
await self.similarity_index.add_vector(cache_key, query_vector)
# Update access patterns
await self.access_patterns.record_access(cache_key, metadata)
async def intelligent_eviction(self):
"""Evict cache entries using multiple factors"""
entries_to_consider = list(self.cache_store.values())
# Calculate eviction scores
eviction_scores = []
for entry in entries_to_consider:
score = await self.calculate_eviction_score(entry)
eviction_scores.append((entry.key, score))
# Sort by score (lower is more likely to evict)
eviction_scores.sort(key=lambda x: x[1])
# Evict bottom 10%
entries_to_evict = int(len(entries_to_consider) * 0.1)
for i in range(entries_to_evict):
key_to_evict = eviction_scores[i][0]
await self.evict_entry(key_to_evict)
async def calculate_eviction_score(self, entry: CacheEntry) -> float:
"""Calculate eviction score based on multiple factors"""
now = datetime.utcnow()
# Recency factor (more recent = higher score)
recency_score = 1.0 / (1.0 + (now - entry.last_accessed).total_seconds() / 3600)
# Frequency factor (more accessed = higher score)
frequency_score = min(entry.access_count / 100.0, 1.0)
# Size factor (smaller = higher score)
entry_size = len(pickle.dumps(entry.value))
size_score = 1.0 / (1.0 + entry_size / 1024) # KB normalization
# Importance factor (business importance)
importance_score = await self.get_business_importance(entry.key)
# Predictive factor (likely to be accessed again)
future_access_probability = await self.prefetch_predictor.predict_future_access(
entry.key
)
# Weighted combination
total_score = (
recency_score * 0.25 +
frequency_score * 0.25 +
size_score * 0.1 +
importance_score * 0.2 +
future_access_probability * 0.2
)
return total_score
class PerformanceOptimizer:
"""System-wide performance optimization for MCP deployments"""
def __init__(self, optimizer_config: OptimizerConfig):
self.config = optimizer_config
self.metrics_collector = MetricsCollector()
self.bottleneck_analyzer = BottleneckAnalyzer()
self.auto_scaler = AutoScaler()
async def continuous_optimization(self):
"""Continuous performance optimization loop"""
while True:
try:
# Collect current performance metrics
metrics = await self.metrics_collector.collect_all_metrics()
# Identify performance bottlenecks
bottlenecks = await self.bottleneck_analyzer.analyze(metrics)
# Apply optimizations
for bottleneck in bottlenecks:
optimization = await self.determine_optimization(bottleneck)
if optimization:
await self.apply_optimization(optimization)
# Check if scaling is needed
scaling_decision = await self.auto_scaler.evaluate_scaling_needs(metrics)
if scaling_decision.action != 'none':
await self.execute_scaling_action(scaling_decision)
# Wait before next optimization cycle
await asyncio.sleep(self.config.optimization_interval)
except Exception as e:
self.logger.error(f"Optimization cycle failed: {e}")
await asyncio.sleep(60) # Wait longer on error
async def determine_optimization(
self,
bottleneck: PerformanceBottleneck
) -> Optional[OptimizationAction]:
"""Determine best optimization for identified bottleneck"""
if bottleneck.type == "high_latency":
# Consider caching, connection pooling, or geographic distribution
if bottleneck.component == "database":
return OptimizationAction(
type="enable_query_caching",
parameters={
"cache_size": "1GB",
"ttl": 3600,
"queries": bottleneck.slow_queries
}
)
elif bottleneck.component == "mcp_server":
return OptimizationAction(
type="increase_connection_pool",
parameters={
"pool_size": bottleneck.current_pool_size * 2,
"server": bottleneck.server_id
}
)
elif bottleneck.type == "high_cpu":
return OptimizationAction(
type="horizontal_scale",
parameters={
"component": bottleneck.component,
"scale_factor": 1.5
}
)
elif bottleneck.type == "memory_pressure":
return OptimizationAction(
type="optimize_memory_usage",
parameters={
"component": bottleneck.component,
"actions": ["reduce_cache_size", "enable_compression"]
}
)
return None
async def predictive_scaling(
self,
historical_metrics: List[MetricsSnapshot],
forecast_horizon: int = 3600 # 1 hour
) -> ScalingForecast:
"""Predict future scaling needs based on historical patterns"""
# Extract time series data
timestamps = [m.timestamp for m in historical_metrics]
cpu_usage = [m.cpu_usage for m in historical_metrics]
memory_usage = [m.memory_usage for m in historical_metrics]
request_rate = [m.request_rate for m in historical_metrics]
# Use time series forecasting
cpu_forecast = await self.forecast_metric(timestamps, cpu_usage, forecast_horizon)
memory_forecast = await self.forecast_metric(timestamps, memory_usage, forecast_horizon)
request_forecast = await self.forecast_metric(timestamps, request_rate, forecast_horizon)
# Determine scaling needs
scaling_needs = []
if max(cpu_forecast.values) > 0.8:
scaling_needs.append(ScalingNeed(
metric="cpu",
predicted_peak=max(cpu_forecast.values),
recommended_action="scale_up",
urgency="high" if max(cpu_forecast.values) > 0.9 else "medium"
))
if max(memory_forecast.values) > 0.85:
scaling_needs.append(ScalingNeed(
metric="memory",
predicted_peak=max(memory_forecast.values),
recommended_action="scale_up",
urgency="high" if max(memory_forecast.values) > 0.95 else "medium"
))
# Predict optimal instance configuration
optimal_config = await self.calculate_optimal_configuration(
cpu_forecast, memory_forecast, request_forecast
)
return ScalingForecast(
forecast_horizon=forecast_horizon,
scaling_needs=scaling_needs,
optimal_configuration=optimal_config,
confidence_score=self.calculate_forecast_confidence(
cpu_forecast, memory_forecast, request_forecast
)
)
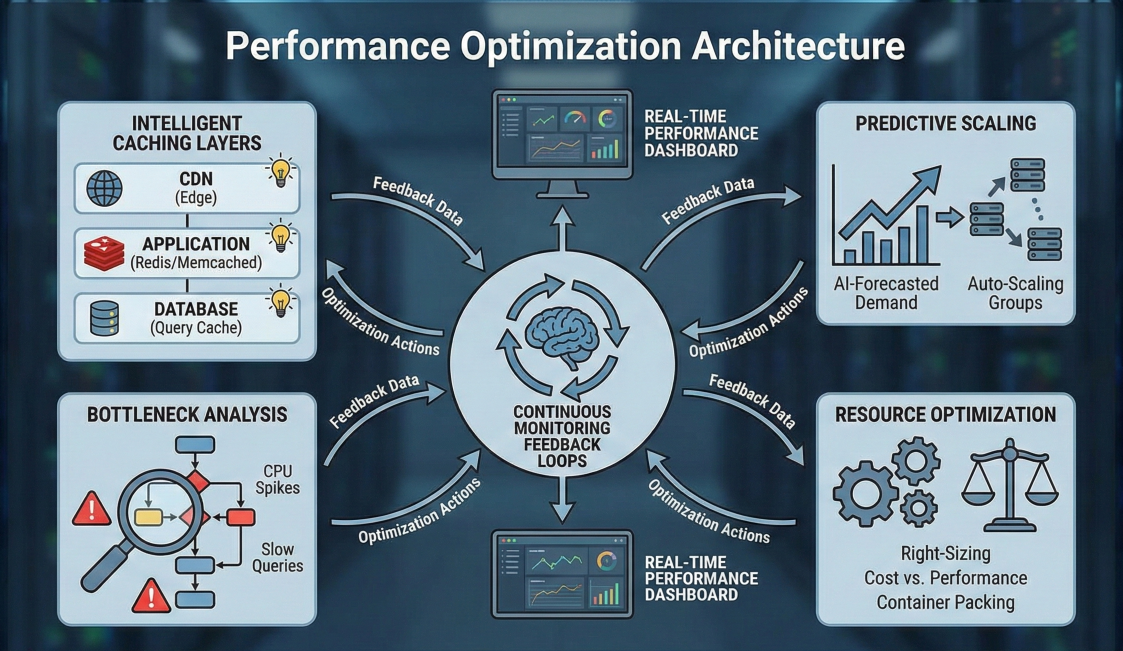
Performance Optimization Architecture: Show intelligent caching layers, bottleneck analysis, predictive scaling, resource optimization, and continuous monitoring feedback loops
Implementing MCP architecture successfully requires a phased approach that balances immediate value delivery with long-term architectural goals. Organizations should start with foundational components and progressively add sophistication as teams gain experience and requirements mature.
Phase 1: Foundation (Months 1-3)
Phase 2: Expansion (Months 4-6)
Phase 3: Scaling (Months 7-12)
Phase 4: Innovation (Months 12+)
Technical Excellence: Prioritize robust engineering practices including comprehensive testing, monitoring, and documentation. MCP systems must be reliable and maintainable as they become critical infrastructure components.
Security by Design: Implement security controls from the beginning rather than adding them later. The distributed nature of MCP architectures creates unique security challenges that require proactive planning.
Organizational Alignment: Ensure stakeholders across engineering, security, compliance, and business teams understand MCP benefits and requirements. Success requires coordination across multiple organizational functions.
Continuous Learning: MCP technology evolves rapidly. Establish processes for staying current with new capabilities, security practices, and architectural patterns through community engagement and experimentation.
Start Your MCP Journey Today: Begin by inventorying your current AI models and tools to understand integration complexity. Identify the highest-impact use cases where MCP architecture would provide immediate value through improved governance, cost control, or user experience.
Build the Foundation: Implement a basic Model Control Plane with policy-based routing for your existing model endpoints. Add observability and audit logging to establish governance baselines. Create your first MCP server for a critical tool or data source.
Measure and Iterate: Track key metrics including cost savings, response time improvements, and compliance posture. Use these measurements to justify continued investment and guide architectural decisions.
Scale with Confidence: As you gain experience, expand to multi-agent coordination, advanced security controls, and predictive optimization. The modular nature of MCP architecture enables incremental capability addition without disrupting existing systems.
The future of enterprise AI depends on robust, scalable, and governed architectures. MCP provides the foundation for this future, enabling organizations to move beyond experimental AI to production systems that deliver sustained business value. Start building your MCP architecture today, and position your organization to capitalize on the continuing evolution of artificial intelligence technology.
The investment in MCP architecture pays dividends through improved operational efficiency, reduced risk, and accelerated AI innovation. Organizations that establish strong MCP foundations now will have significant competitive advantages as AI capabilities continue expanding and becoming more central to business operations.

{{AUTHOR}}
 Launch your Graphy
Launch your Graphy