There are no items in your cart
Add More
Add More
| Item Details | Price | ||
|---|---|---|---|

If you've ever tried scaling machine learning from proof-of-concept to production, you know it's a nightmare. Your beautiful Jupyter notebook works perfectly on sample data, but then comes the avalanche of production challenges: containerization, scaling, feature consistency, model monitoring, CI/CD integration, and maintaining performance under real-world load.
That's precisely where MLRun transforms your MLOps journey from chaos to orchestrated excellence. It's not just another tool in the crowded ML ecosystem – it's a comprehensive orchestration framework that handles the complete AI lifecycle with enterprise-grade reliability and minimal friction.
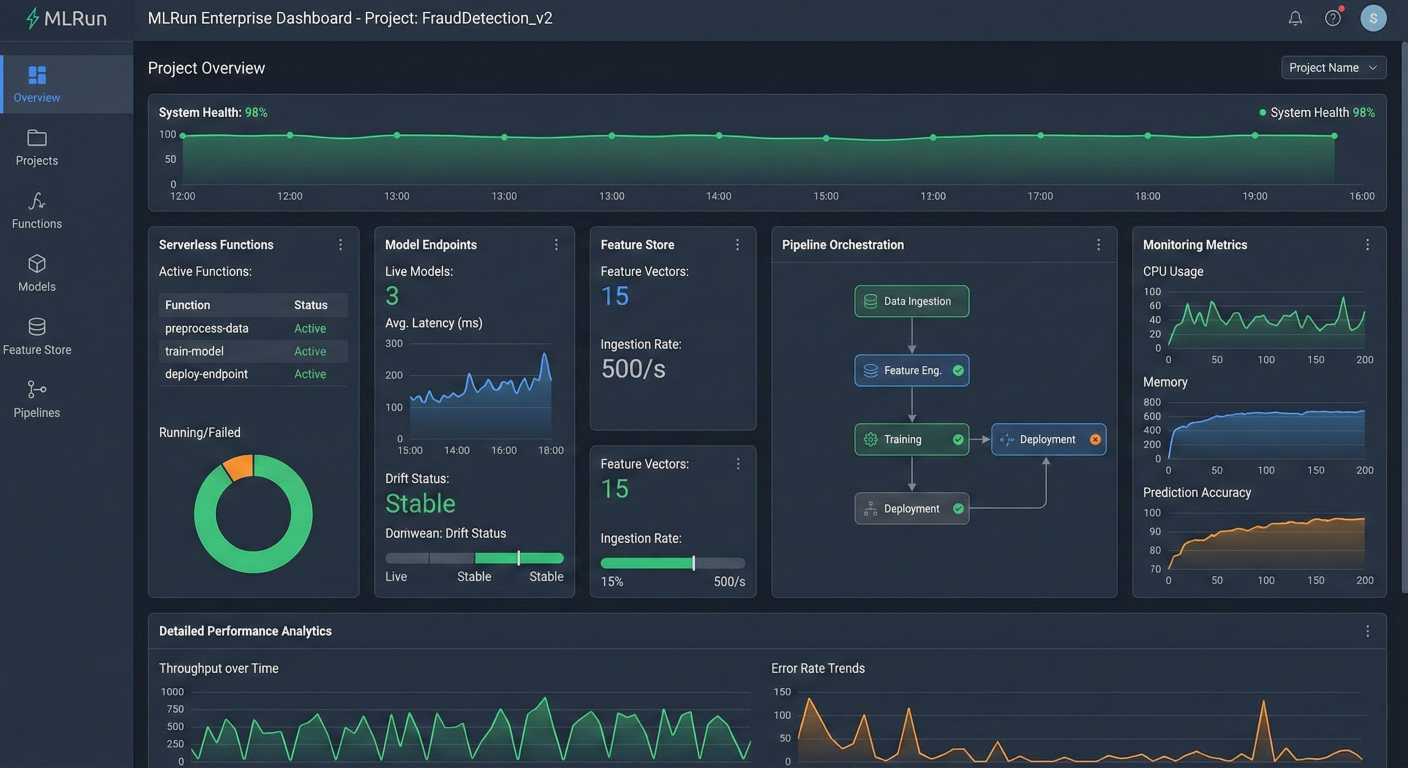
MLRun enterprise dashboard interface showing comprehensive project overview with serverless functions, model endpoints, feature store, monitoring metrics, and pipeline orchestration in a modern dark theme with detailed performance analytics
MLRun isn't trying to be everything to everyone. Instead, it laser-focuses on one critical mission: eliminating the gap between ML experimentation and production deployment while maintaining enterprise-grade reliability and scalability. Here's what sets it apart from every other MLOps solution:
🚀 True Serverless Architecture: Write your code once using standard Python semantics, then run it seamlessly from your laptop to massive Kubernetes clusters. No containerization headaches, no scaling complexity, no infrastructure management.
🏪 Production-Grade Feature Store: Build features once, use them everywhere with millisecond latency. Automatic consistency between training and serving environments eliminates the #1 cause of model performance degradation.
📊 Intelligent Model Monitoring: Real-time drift detection, performance tracking, and automated retraining triggers with customizable alerts and enterprise-grade observability.
🔄 Native CI/CD Integration: Designed from the ground up to work with modern DevOps workflows. Git-based deployments, automated testing, and blue-green rollouts built-in.
🎯 Curated Function Hub: Battle-tested, pre-optimized functions for every ML task. Why spend weeks building what's already been perfected?
⚡ Enterprise Scalability: From prototype to petabyte-scale deployments on any cloud or onpremises infrastructure.
The real magic happens when all these components work together as a unified orchestration platform. You're not juggling 15 different tools – you're using one integrated, enterprise-ready system.
Understanding MLRun's architecture is crucial for leveraging its full potential. Think of it as a four-layer orchestration system that handles every aspect of the ML lifecycle:
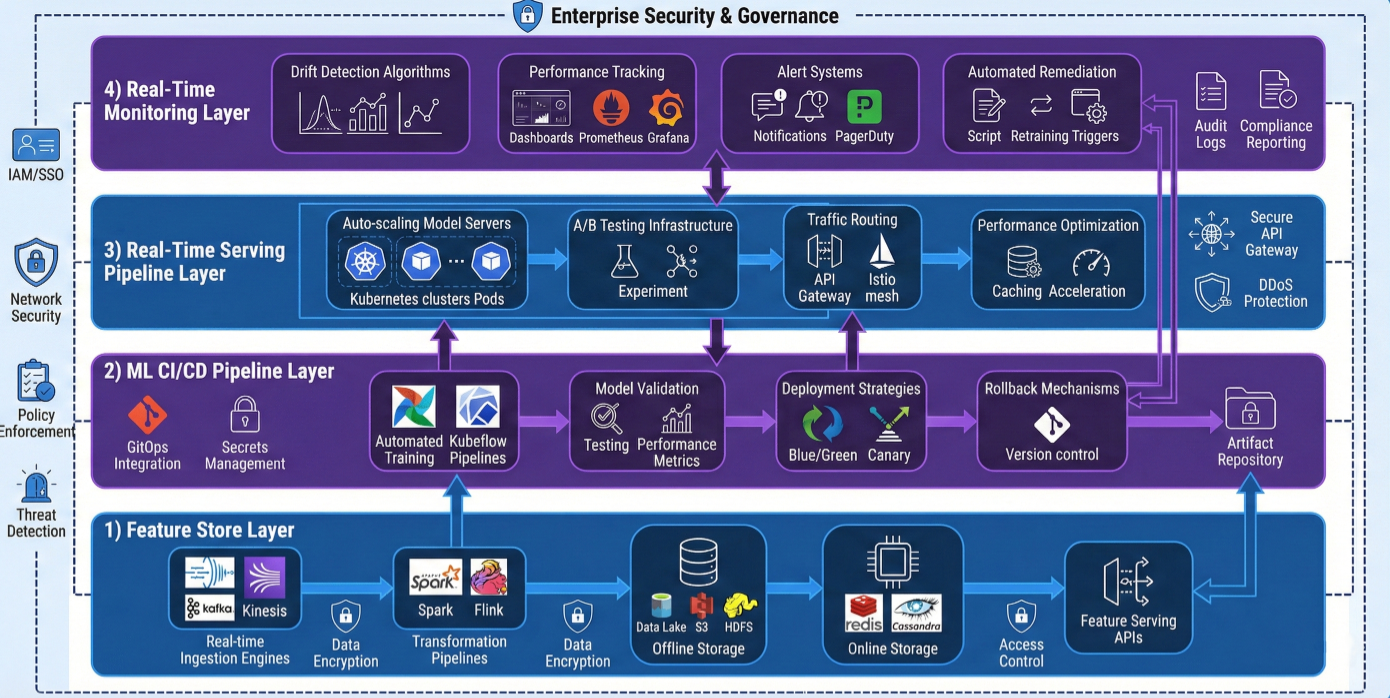
Comprehensive MLRun enterprise architecture diagram showing the four core layers with detailed components: 1) Feature Store Layer (real-time ingestion engines, transformation pipelines, offline/online storage, feature serving APIs), 2) ML CI/CD Pipeline Layer (automated training workflows, model validation, deployment strategies, rollback mechanisms), 3) Real-Time Serving Pipeline Layer (auto-scaling model servers, A/B testing infrastructure, traffic routing, performance optimization), and 4) Real-Time Monitoring Layer (drift detection algorithms, performance tracking, alert systems, automated remediation) with detailed data flow arrows and enterprise security components
The feature store isn't just storage – it's your intelligent data infrastructure that solves the most persistent ML production problems:
This layer orchestrates the complete model lifecycle with enterprise-grade reliability:
The serving layer handles production inference with enterprise-grade performance:
High-Performance Model Serving:
Continuous monitoring with intelligent automation:
Let's dive deep into setting up MLRun for enterprise deployment. I'll cover everything from development environments to production Kubernetes clusters.
# Create isolated environment for MLRun
conda create -n mlrun-env python=3.9
conda activate mlrun-env
# Core MLRun installation with all features
pip install mlrun[complete]
# For specific cloud providers (choose your stack)
pip install mlrun[s3,azure-blob-storage,google-cloud-storage]
# Development dependencies
pip install jupyter
pip install scikit-learn>=1.3.0
pip install pandas>=1.5.0
pip install numpy>=1.21.0
# Visualization and monitoring
pip install plotly
pip install matplotlib
pip install seaborn
# Optional: GPU support for deep learning
pip install torch torchvision # PyTorch
pip install tensorflow-gpu # TensorFlow
import mlrun
import os
from mlrun import code_to_function, mount_v3io
# Configure MLRun for different environments
def setup_mlrun_environment(env_type="development"):
"""Configure MLRun for different deployment scenarios"""
if env_type == "development":
# Local development with Docker
mlrun.set_environment(
api_base_url="http://localhost:8080",
artifact_path="./artifacts",
username="developer"
)
elif env_type == "staging":
# Staging cluster configuration
mlrun.set_environment(
api_base_url="https://mlrun-api-staging.company.com",
artifact_path="s3://ml-artifacts-staging/",
access_key=os.getenv("MLRUN_ACCESS_KEY"),
username=os.getenv("USERNAME")
)
elif env_type == "production":
# Production cluster with full security
mlrun.set_environment(
api_base_url="https://mlrun-api.company.com",
artifact_path="s3://ml-artifacts-prod/",
access_key=os.getenv("MLRUN_PROD_ACCESS_KEY"),
username=os.getenv("PROD_USERNAME"),
# Additional security configurations
verify_ssl=True,
timeout=30
)
print(f"MLRun configured for {env_type} environment")
return mlrun.get_or_create_project(f"project-{env_type}")
# Initialize development environment
project = setup_mlrun_environment("development")
# Create MLRun namespace with resource quotas
kubectl create namespace mlrun
# Apply resource quotas for production
cat << EOF | kubectl apply -f -
apiVersion: v1
kind: ResourceQuota
metadata:
name: mlrun-quota
namespace: mlrun
spec:
hard:
requests.cpu: "50"
requests.memory: 100Gi
limits.cpu: "100"
limits.memory: 200Gi
persistentvolumeclaims: "20"
EOF
# Create service accounts with proper RBAC
kubectl create serviceaccount mlrun-admin -n mlrun
# Add Helm repository for MLRun Community Edition
helm repo add mlrun-ce https://mlrun.github.io/ce
helm repo update
# Create registry credentials for private images
kubectl create secret docker-registry registry-credentials \
--namespace mlrun \
--docker-server=your-registry.company.com \
--docker-username=$REGISTRY_USERNAME \
--docker-password=$REGISTRY_PASSWORD \
--docker-email=$REGISTRY_EMAIL
# Production installation with enterprise configurations
helm install mlrun-ce mlrun-ce/mlrun-ce \
--namespace mlrun \
--wait \
--timeout 30m \
--set global.registry.url=your-registry.company.com \
--set global.registry.secretName=registry-credentials \
--set global.externalHostAddress=$(kubectl get nodes -o wide | awk 'NR==2{print $6}') \
--set nuclio.dashboard.externalIPAddresses={$(kubectl get nodes -o wide | awk 'NR==2{print $6}')} \
--set mlrun.api.replicas=3 \
--set mlrun.ui.replicas=2 \
--set postgresql.primary.persistence.size=100Gi \
--set minio.persistence.size=500Gi \
--set global.storage.storageClass=gp3 \
--values production-values.yaml
global:
# Enterprise security settings
security:
enabled: true
tls:
enabled: true
secretName: mlrun-tls-secret
# Resource management
resources:
api:
requests:
cpu: "2000m"
memory: "4Gi"
limits:
cpu: "4000m"
memory: "8Gi"
ui:
requests:
cpu: "500m"
memory: "1Gi"
limits:
cpu: "1000m"
memory: "2Gi"
# High availability configuration
mlrun:
api:
replicas: 3
autoscaling:
enabled: true
minReplicas: 3
maxReplicas: 10
targetCPUUtilizationPercentage: 70
ui:
replicas: 2
autoscaling:
enabled: true
minReplicas: 2
maxReplicas: 5
# Monitoring and observability
monitoring:
prometheus:
enabled: true
grafana:
enabled: true
persistence:
enabled: true
size: 10Gi
# Backup and disaster recovery
backup:
enabled: true
schedule: "0 2 * * *" # Daily at 2 AM retention: "30d"Serverless functions are the atomic units of computation in MLRun. They're intelligent, containerized units that automatically handle scaling, resource management, and deployment complexity.
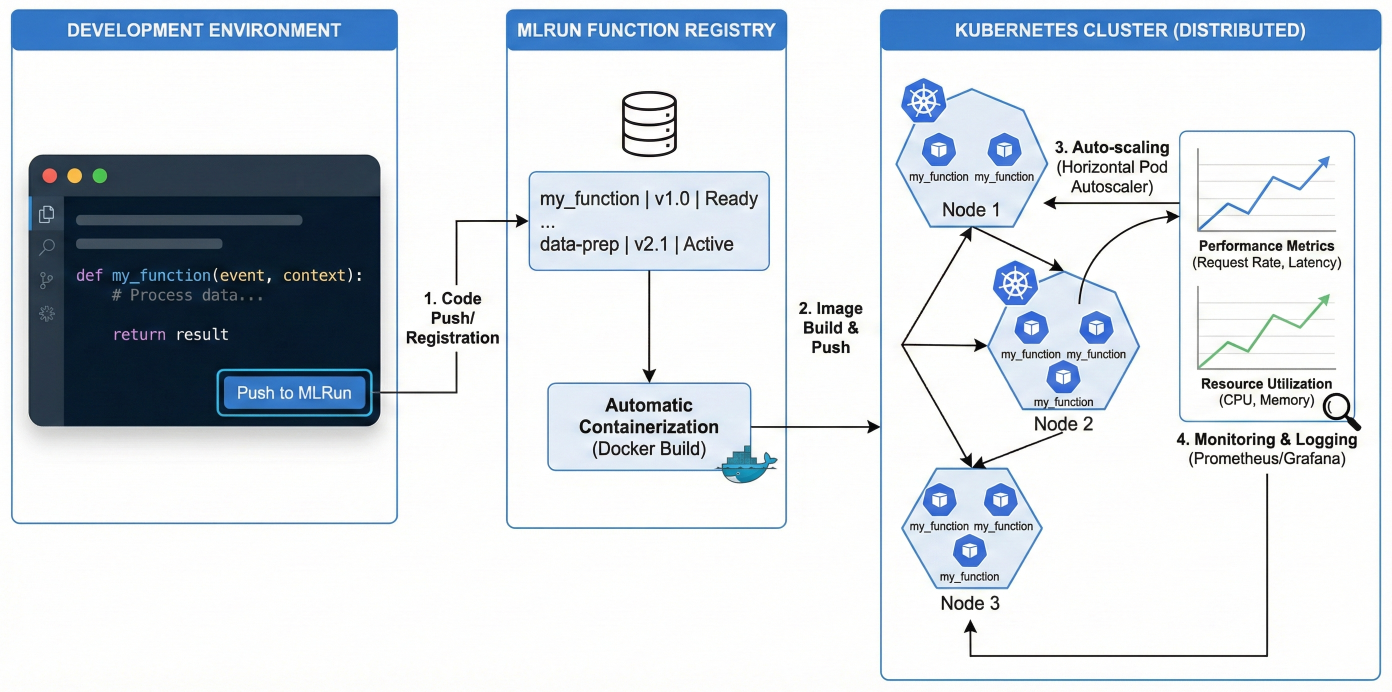
Detailed serverless function lifecycle diagram showing code development → function registration → automatic containerization → Kubernetes deployment → auto-scaling → monitoring, with code editor interface on left, MLRun function registry in center, and distributed Kubernetes cluster with auto-scaling pods on right, including performance metrics and resource utilization graphs
# advanced_data_processor.py
import pandas as pd
import numpy as np
import mlrun
from sklearn.preprocessing import StandardScaler, LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.impute import SimpleImputer
import joblib
import json
@mlrun.handler()
def advanced_data_processor(
context,
dataset_path: mlrun.DataItem,
target_column: str,
test_size: float = 0.2,
validation_size: float = 0.1,
outlier_threshold: float = 3.0,
missing_strategy: str = "median",
feature_selection: bool = True,
n_features: int = None,
random_state: int = 42
):
"""
Advanced data processing pipeline with comprehensive preprocessing
"""
# Initialize processing components
scaler = StandardScaler()
label_encoder = LabelEncoder()
imputer = SimpleImputer(strategy=missing_strategy)
# Load and validate data
try:
df = dataset_path.as_df()
context.log_result("original_shape", df.shape)
context.log_result("original_columns", list(df.columns))
except Exception as e:
context.logger.error(f"Failed to load data: {str(e)}")
raise ValueError(f"Data loading failed: {str(e)}")
# Data quality assessment
quality_metrics = {
"missing_values": df.isnull().sum().to_dict(),
"duplicate_rows": df.duplicated().sum(),
"data_types": df.dtypes.to_dict()
}
context.log_result("data_quality", quality_metrics)
# Handle missing values
numeric_cols = df.select_dtypes(include=[np.number]).columns.tolist()
categorical_cols = df.select_dtypes(include=['object']).columns.tolist()
if numeric_cols:
df[numeric_cols] = imputer.fit_transform(df[numeric_cols])
# Outlier detection and removal
if numeric_cols and outlier_threshold > 0:
z_scores = np.abs(stats.zscore(df[numeric_cols]))
outliers_mask = (z_scores < outlier_threshold).all(axis=1)
df = df[outliers_mask]
context.log_result("outliers_removed", len(df) - outliers_mask.sum())
# Encode categorical variables
encoded_cols = []
for col in categorical_cols:
if col != target_column:
df[f"{col}_encoded"] = label_encoder.fit_transform(df[col].astype(str))
encoded_cols.append(f"{col}_encoded")
# Save encoder for later use
context.log_model(
f"{col}_encoder",
body=label_encoder,
model_file=f"{col}_encoder.pkl"
)
# Feature engineering
if len(numeric_cols) > 1:
# Create interaction features
for i, col1 in enumerate(numeric_cols[:5]): # Limit to prevent explosion
for col2 in numeric_cols[i+1:6]:
df[f"{col1}_{col2}_interaction"] = df[col1] * df[col2]
# Prepare feature matrix
feature_cols = numeric_cols + encoded_cols
if feature_selection and n_features and len(feature_cols) > n_features:
from sklearn.feature_selection import SelectKBest, f_classif
selector = SelectKBest(score_func=f_classif, k=n_features)
X_selected = selector.fit_transform(df[feature_cols], df[target_column])
selected_features = [feature_cols[i] for i in selector.get_support(indices=True)]
feature_cols = selected_features
# Log feature selection results
context.log_model("feature_selector", body=selector, model_file="feature_selector")
context.log_result("selected_features", selected_features)
# Scale features
X = df[feature_cols]
X_scaled = scaler.fit_transform(X)
df_processed = pd.DataFrame(X_scaled, columns=feature_cols, index=df.index)
df_processed[target_column] = df[target_column].values
# Train-validation-test split
X_temp, X_test, y_temp, y_test = train_test_split(
df_processed[feature_cols],
df_processed[target_column],
test_size=test_size,
random_state=random_state,
stratify=df_processed[target_column] if df_processed[target_column].dtype == 'obj'
)
val_size_adjusted = validation_size / (1 - test_size)
X_train, X_val, y_train, y_val = train_test_split(
X_temp, y_temp,
test_size=val_size_adjusted,
random_state=random_state,
stratify=y_temp if y_temp.dtype == 'object' else None
)
# Create final datasets
train_df = pd.concat([X_train, y_train], axis=1)
val_df = pd.concat([X_val, y_val], axis=1)
test_df = pd.concat([X_test, y_test], axis=1)
# Log processing artifacts
context.log_model("scaler", body=scaler, model_file="scaler.pkl")
context.log_dataset("training_data", df=train_df, format="parquet")
context.log_dataset("validation_data", df=val_df, format="parquet")
context.log_dataset("test_data", df=test_df, format="parquet")
# Log comprehensive metrics
processing_metrics = {
"processed_shape": df_processed.shape,
"feature_count": len(feature_cols),
"train_size": len(train_df),
"validation_size": len(val_df),
"test_size": len(test_df),
"feature_columns": feature_cols,
"processing_strategy": missing_strategy,
"outlier_threshold": outlier_threshold
}
context.log_results(processing_metrics)
return {
"train_data": train_df,
"validation_data": val_df,
"test_data": test_df,
"feature_columns": feature_cols,
"processing_artifacts": {
"scaler": "scaler.pkl",
"encoders": [f"{col}_encoder.pkl" for col in categorical_cols if col != targe]
}
}
# Register the advanced data processor with enterprise configurations
data_processor = project.set_function(
name="advanced-data-processor",
func="advanced_data_processor.py",
kind="job",
image="mlrun/mlrun",
handler="advanced_data_processor"
)
# Configure compute resources based on workload
data_processor.with_requests(cpu="2000m", memory="8Gi")
data_processor.with_limits(cpu="4000m", memory="16Gi")
# Add GPU support if needed
# data_processor.gpus(1, gpu_type="nvidia.com/gpu")
# Configure storage volumes
data_processor.apply(mlrun.mount_v3io()) # For Iguazio users
# Or for standard PVC
# data_processor.apply(mlrun.platforms.mount_pvc("data-pvc", "/data"))
# Set environment variables
data_processor.set_env("OMP_NUM_THREADS", "4")
data_processor.set_env("CUDA_VISIBLE_DEVICES", "0")
# Configure security context for enterprise deployments
from kubernetes import client as k8s_client
security_context = k8s_client.V1SecurityContext(
run_as_user=1000,
run_as_group=1000,
run_as_non_root=True
)
data_processor.with_security_context(security_context)
# Add custom requirements
data_processor.build_config(
requirements=["scikit-learn==1.3.0", "scipy>=1.9.0", "pandas>=1.5.0"],
base_image="mlrun/mlrun:1.6.0",
commands=[
"apt-get update && apt-get install -y build-essential",
"pip install --upgrade pip"
]
)
# Save function configuration
project.save()
# Execute the advanced data processor
processor_run = project.run_function(
"advanced-data-processor",
inputs={"dataset_path": "s3://ml-data/raw/customer_data.csv"},
params={{
"target_column": "churn",
"test_size": 0.2,
"validation_size": 0.1,
"outlier_threshold": 2.5,
"missing_strategy": "median",
"feature_selection": True,
"n_features": 50,
"random_state": 42
}},
# Resource overrides for this specific run
resources={"requests": {"cpu": "3000m", "memory": "12Gi"}},
# Run on specific node types
node_selector={"node-type": "compute-optimized"},
# Add tolerations for dedicated nodes
tolerations=[{
"key": "dedicated",
"operator": "Equal",
"value": "ml-workloads",
"effect": "NoSchedule"
}],
# Set run priority
priority_class_name="high-priority",
# Enable spot instances for cost optimization
preemption_policy="PreemptLowerPriority"
)
# Monitor run progress
print(f"Run status: {processor_run.state()}")
print(f"Run logs: {processor_run.logs()}")
# Access results once complete
if processor_run.state() == "completed":
training_data = processor_run.outputs["training_data"]
validation_data = processor_run.outputs["validation_data"]
test_data = processor_run.outputs["test_data"]
print(f"Training data artifact: {training_data}")
print(f"Processing metrics: {processor_run.results}")
The MLRun feature store isn't just about storage – it's a complete data intelligence platform that solves the most critical ML production challenges with enterprise-grade reliability.
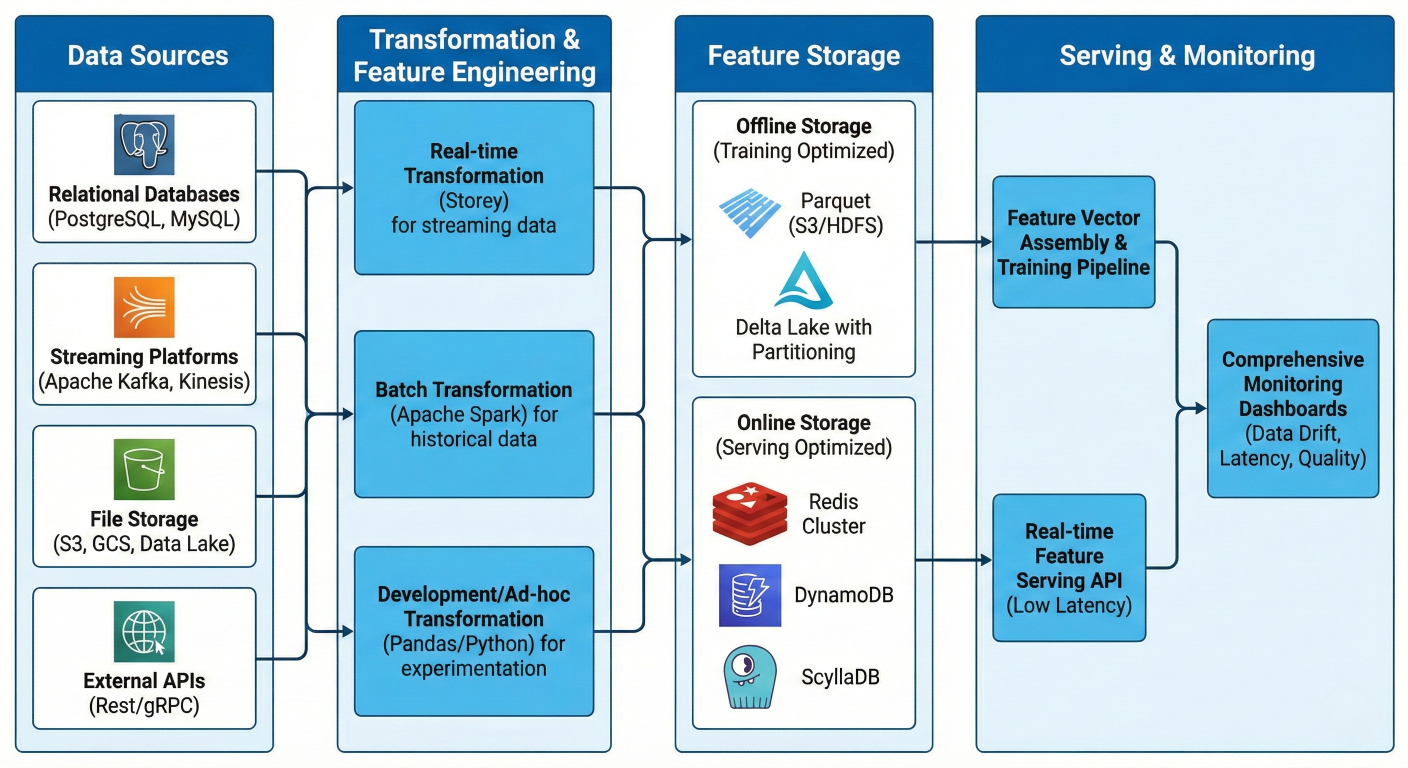
Comprehensive feature store architecture diagram showing multiple data sources (databases, streaming platforms, files, APIs) flowing through advanced transformation engines (Storey for real-time, Spark for batch, Pandas for development) into both offline storage optimized for training (Parquet, Delta Lake with partitioning) and online storage optimized for serving (Redis Cluster, DynamoDB, ScyllaDB) with feature vector assembly, real-time serving APIs, and comprehensive monitoring dashboards
import mlrun.feature_store as fs
from mlrun.feature_store.steps import *
import pandas as pd
from datetime import datetime, timedelta
# Define comprehensive user behavior feature set
user_behavior_features = fs.FeatureSet(
"user-behavior-v2",
entities=[fs.Entity("user_id")],
description="Advanced user behavioral features with real-time aggregations",
timestamp_key="event_timestamp"
)
# Configure advanced aggregation features
aggregation_configs = [
{
"name": "transaction_metrics",
"column": "transaction_amount",
"operations": ["sum", "count", "mean", "std", "min", "max"],
"windows": ["1h", "6h", "24h", "7d", "30d"],
"period": "1h"
},
{
"name": "session_behavior",
"column": "session_duration_minutes",
"operations": ["mean", "max", "count"],
"windows": ["3h", "24h", "7d"],
"period": "1h"
},
{
"name": "engagement_metrics",
"column": "page_views",
"operations": ["sum", "mean"],
"windows": ["1h", "6h", "24h"],
"period": "30m"
}
]
# Add complex aggregations
for config in aggregation_configs:
user_behavior_features.add_aggregation(
name=config["name"],
column=config["column"],
operations=config["operations"],
windows=config["windows"],
period=config["period"]
)
# Add calculated features
user_behavior_features.add_feature(
fs.Feature("avg_transaction_per_session", ValueType.FLOAT),
fs.Feature("user_segment", ValueType.STRING),
fs.Feature("risk_score", ValueType.FLOAT),
fs.Feature("lifetime_value", ValueType.FLOAT)
)
# Define advanced transformation graph
graph = user_behavior_features.graph
# Add custom transformation steps
@graph.to("CalculatedFeatures", name="feature_engineering")
class AdvancedFeatureEngineering:
def __init__(self):
self.risk_model = None # Load pre-trained risk model
def do(self, event):
# Calculate derived features
if event.get("transaction_count_24h", 0) > 0:
event["avg_transaction_per_session"] = (
event.get("transaction_sum_24h", 0) /
event.get("session_count_24h", 1)
)
else:
event["avg_transaction_per_session"] = 0.0
# User segmentation logic
ltv = event.get("lifetime_value", 0)
transaction_frequency = event.get("transaction_count_30d", 0)
if ltv > 10000 and transaction_frequency > 20:
event["user_segment"] = "premium"
elif ltv > 5000 and transaction_frequency > 10:
event["user_segment"] = "standard"
else:
event["user_segment"] = "basic"
# Risk scoring
recent_activity = event.get("transaction_count_1h", 0)
unusual_pattern = recent_activity > event.get("transaction_mean_24h", 0) * 3
if unusual_pattern:
event["risk_score"] = min(1.0, event.get("risk_score", 0.1) * 2)
else:
event["risk_score"] = max(0.0, event.get("risk_score", 0.1) * 0.9)
return event
# Configure multiple storage targets for different use cases
user_behavior_features.set_targets([
# Offline storage for training
fs.ParquetTarget(
name="offline",
path="s3://ml-features/user-behavior/offline/",
partitioned=True,
partition_cols=["year", "month", "day"],
max_events=10000
),
# Online storage for real-time serving
fs.RedisNoSqlTarget(
name="online",
path="redis://feature-store-cluster:6379/0",
key_bucketing_number=256, # For sharding
max_events=1000000
),
# Stream target for real-time monitoring
fs.StreamTarget(
name="monitoring",
path="kafka://feature-monitoring-topic",
after_state="online"
)
])
# Configure real-time data source
user_behavior_features.set_source(
path="kafka://user-events-topic",
timestamp_key="event_timestamp",
key_field="user_id"
)
# Save feature set with metadata
user_behavior_features.metadata.labels = {
"team": "data-science",
"environment": "production",
"criticality": "high"
}
user_behavior_features.save()
# Product-level features with advanced analytics
product_features = fs.FeatureSet(
"product-intelligence-v1",
entities=[fs.Entity("product_id"), fs.Entity("category_id")],
description="Product performance and trend analysis features"
)
# Multi-entity aggregations
product_features.add_aggregation(
name="sales_performance",
column="sales_amount",
operations=["sum", "count", "mean"],
windows=["1d", "7d", "30d"],
by=["product_id", "category_id"] # Group by multiple entities
)
# Trend analysis features
product_features.add_aggregation(
name="inventory_turnover",
column="inventory_level",
operations=["last", "min", "max"],
windows=["1d", "7d"],
period="4h"
)
# Define complex transformation for trend detection
@product_features.graph.to("TrendAnalysis", name="trend_detector")
class ProductTrendAnalyzer:
def __init__(self):
self.trend_window = 7 # Days
def do(self, event):
# Calculate sales trend
recent_sales = event.get("sales_sum_7d", 0)
previous_sales = event.get("sales_sum_14d", 0) - recent_sales
if previous_sales > 0:
trend = (recent_sales - previous_sales) / previous_sales
event["sales_trend_7d"] = trend
if trend > 0.2:
event["trend_category"] = "growing"
elif trend < -0.2:
event["trend_category"] = "declining"
else:
event["trend_category"] = "stable"
else:
event["sales_trend_7d"] = 0.0
event["trend_category"] = "new"
return event
# Create sophisticated feature vector for recommendation system recommendation_features = fs.FeatureVector( "recommendation-features-v3", features=[ # User behavioral features "user-behavior-v2.transaction_sum_24h", "user-behavior-v2.transaction_count_7d", "user-behavior-v2.session_duration_mean_24h", "user-behavior-v2.user_segment", "user-behavior-v2.risk_score", # Product intelligence features "product-intelligence-v1.sales_sum_7d", "product-intelligence-v1.inventory_turnover_last_1d", "product-intelligence-v1.sales_trend_7d", "product-intelligence-v1.trend_category", # Cross-feature interactions "user-behavior-v2.lifetime_value", "product-intelligence-v1.sales_count_30d" ], description="Comprehensive feature vector for recommendation engine", label_feature="conversion_probability" ) # Configure feature vector with advanced options recommendation_features.metadata.labels = { "model_type": "recommendation", "version": "3.0", "data_scientist": "team-lead" } # Save feature vector recommendation_features.save()
# Deploy high-performance real-time ingestion service
from mlrun import serving
from mlrun.serving.server import create_graph
# Create advanced ingestion pipeline
ingestion_function = project.set_function(
name="user-behavior-ingestion",
kind="serving",
image="mlrun/mlrun",
requirements=[
"kafka-python>=2.0.2",
"redis>=4.0.0",
"pandas>=1.5.0"
]
)
# Configure for high-throughput ingestion
ingestion_function.with_limits(cpu="4000m", memory="8Gi")
ingestion_function.with_requests(cpu="2000m", memory="4Gi")
# Set up for horizontal scaling
ingestion_function.spec.min_replicas = 3
ingestion_function.spec.max_replicas = 20
ingestion_function.spec.target_cpu = 70
# Deploy the ingestion service with advanced configuration
ingestion_service = user_behavior_features.deploy_ingestion_service(
source=fs.sources.KafkaSource(
brokers="kafka-cluster:9092",
topics=["user-events", "transaction-events"],
consumer_group="mlrun-ingestion",
initial_offset="latest",
max_events=1000,
key_field="user_id"
),
run_config=fs.RunConfig(
function=ingestion_function,
local=False
),
# Advanced ingestion parameters
max_events=10000,
flush_after_seconds=30,
targets=["online", "offline"],
return_df=False
)
print(f"Ingestion service deployed: {ingestion_service.status}")
# Set up high-performance feature serving
class AdvancedFeatureService:
def __init__(self):
self.feature_service = fs.get_online_feature_service(
recommendation_features,
# Advanced caching configuration
cache_ttl=300, # 5 minutes
cache_size=10000,
prefetch_features=True
)
async def get_features_batch(self, entity_rows, timeout=1.0):
"""Get features for multiple entities with timeout"""
try:
features = await asyncio.wait_for(
self.feature_service.get_async(entity_rows),
timeout=timeout
)
return features
except asyncio.TimeoutError:
# Fallback to cached or default values
return self._get_fallback_features(entity_rows)
def get_features_with_fallback(self, entity_rows):
"""Get features with intelligent fallback strategy"""
try:
# Try online store first
features = self.feature_service.get(entity_rows)
# Validate feature completeness
if self._validate_features(features):
return features
else:
# Fallback to offline store for missing features
return self._enrich_from_offline(features, entity_rows)
except Exception as e:
logging.warning(f"Feature serving error: {e}")
return self._get_fallback_features(entity_rows)
def _validate_features(self, features):
"""Validate that all required features are present"""
required_features = ["user_segment", "risk_score", "sales_trend_7d"]
return all(feat in features for feat in required_features)
# Initialize advanced feature serving
feature_service = AdvancedFeatureService()
# Example usage in production
entity_batch = [
{"user_id": "user_123", "product_id": "prod_456"},
{"user_id": "user_789", "product_id": "prod_101"}
]
features = feature_service.get_features_with_fallback(entity_batch)
The MLRun Function Hub provides battle-tested, enterprise-ready functions that eliminate weeks of development work. Let's explore advanced usage patterns and customizations.
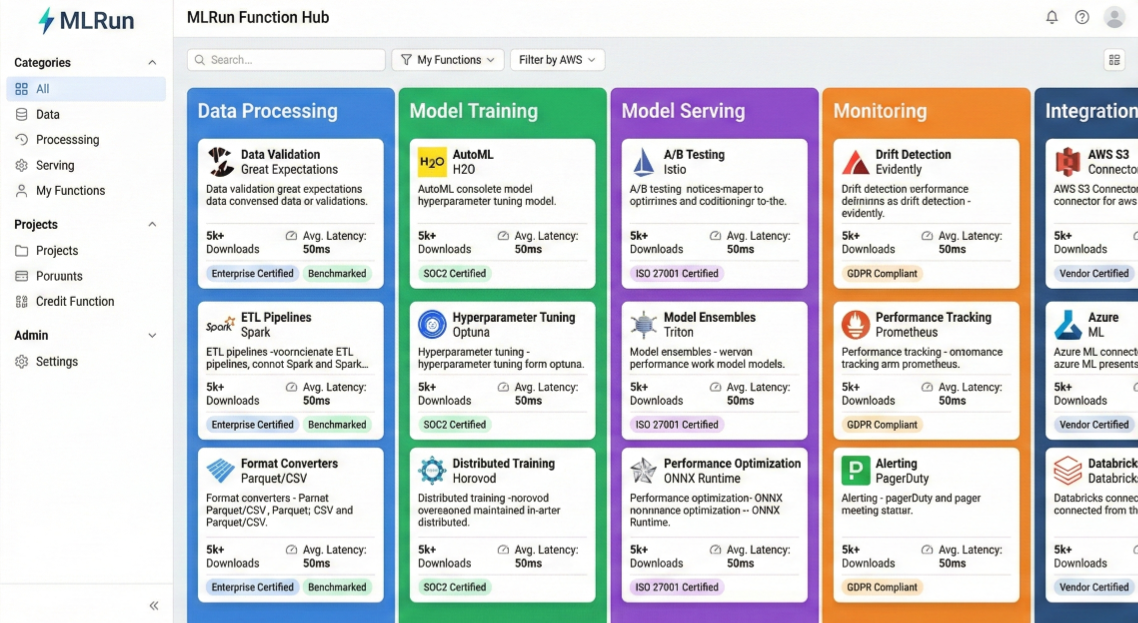
MLRun function hub enterprise interface showing categorized functions: Data Processing (data validation, ETL pipelines, format converters), Model Training (AutoML, hyperparameter tuning, distributed training), Model Serving (A/B testing, model ensembles, performance optimization), Monitoring (drift detection, performance tracking, alerting), and Integration functions with detailed descriptions, usage statistics, performance benchmarks, and enterprise certifications
Distributed Training with Hyperparameter Optimization:
# Import enterprise-grade training function
distributed_trainer = mlrun.import_function("hub://xgb_trainer_v2")
# Configure for distributed training
distributed_trainer.with_limits(cpu="8000m", memory="32Gi")
distributed_trainer.with_replicas(min=2, max=10)
# Set up advanced hyperparameter search space
hyperparameter_grid = {
# XGBoost parameters
"n_estimators": [100, 200, 500, 1000],
"max_depth": [3, 6, 10, 15],
"learning_rate": [0.01, 0.1, 0.2, 0.3],
"subsample": [0.8, 0.9, 1.0],
"colsample_bytree": [0.8, 0.9, 1.0],
"reg_alpha": [0, 0.1, 1.0],
"reg_lambda": [1, 1.5, 2.0],
# Training parameters
"early_stopping_rounds": [10, 20, 50],
"eval_metric": ["auc", "logloss"],
# Cross-validation parameters
"cv_folds": [3, 5],
"stratified": [True],
}
# Advanced training run with enterprise configurations
training_run = project.run_function(
distributed_trainer,
name="enterprise-model-training",
inputs={
"dataset": processor_run.outputs["training_data"],
"validation_set": processor_run.outputs["validation_data"],
"test_set": processor_run.outputs["test_data"]
},
hyperparams=hyperparameter_grid,
params={
"label_columns": "churn",
"model_name": "churn_predictor_v2",
"sample_set_size": 10000, # For model monitoring
# Advanced training configurations
"optimize_metric": "auc",
"optimization_direction": "maximize",
"max_trials": 100,
"parallel_trials": 4,
# Model explainability
"feature_importance": True,
"shap_analysis": True,
"partial_dependence": True,
# Enterprise compliance
"model_governance": True,
"audit_trail": True,
"data_lineage": True
},
# Resource scheduling
selector="max.auc",
resources={
"requests": {"cpu": "4000m", "memory": "16Gi"},
"limits": {"cpu": "8000m", "memory": "32Gi"}
},
# Advanced scheduling
node_selector={"instance-type": "c5.4xlarge"},
tolerations=[{
"key": "training-workloads",
"operator": "Equal",
"value": "true",
"effect": "NoSchedule"
}],
# Cost optimization
spot_instances=True,
preemption_policy="PreemptLowerPriority"
)
# Monitor training progress with advanced metrics
training_metrics = training_run.get_results()
print(f"Best AUC: {training_metrics.get('best_auc', 'N/A')}")
print(f"Best parameters: {training_metrics.get('best_params', 'N/A')}")
print(f"Training duration: {training_metrics.get('training_duration', 'N/A')}")
# Access model artifacts
best_model = training_run.outputs.get("model")
feature_importance = training_run.artifacts.get("feature_importance")
shap_analysis = training_run.artifacts.get("shap_analysis")
# Import model validation function
model_validator = mlrun.import_function("hub://model_validator_enterprise")
# Configure comprehensive validation suite
validation_run = project.run_function(
model_validator,
name="enterprise-model-validation",
inputs={
"model": training_run.outputs["model"],
"test_data": processor_run.outputs["test_data"],
"validation_data": processor_run.outputs["validation_data"],
"feature_metadata": processor_run.outputs["feature_columns"]
},
params={
"validation_suite": "comprehensive",
# Performance thresholds
"min_auc": 0.75,
"min_precision": 0.70,
"min_recall": 0.65,
"max_prediction_latency": 100, # milliseconds
# Bias and fairness testing
"fairness_testing": True,
"protected_attributes": ["age_group", "gender"],
"fairness_metrics": ["demographic_parity", "equalized_odds"],
# Robustness testing
"adversarial_testing": True,
"data_drift_simulation": True,
"stress_testing": True,
# Compliance testing
"gdpr_compliance": True,
"model_interpretability": True,
"right_to_explanation": True
}
)
# Check validation results
validation_results = validation_run.get_results()
model_approved = validation_results.get("validation_passed", False)
if model_approved:
print("✅ Model passed all validation tests")
print(f"Performance score: {validation_results.get('performance_score')}")
print(f"Fairness score: {validation_results.get('fairness_score')}")
else:
print("❌ Model failed validation")
print(f"Failed tests: {validation_results.get('failed_tests', [ ])}")
# Create enterprise-specific function
@mlrun.handler()
def enterprise_model_deployment(
context,
model_path: mlrun.DataItem,
deployment_strategy: str = "blue_green",
canary_percentage: float = 10.0,
validation_dataset: mlrun.DataItem = None,
business_metrics: dict = None,
compliance_checks: bool = True
):
"""
Enterprise model deployment with advanced strategies
"""
import json
import time
from datetime import datetime
# Load and validate model
model = context.get_dataitem(model_path).get_model()
# Run compliance checks
if compliance_checks:
compliance_results = run_compliance_validation(model, context)
if not compliance_results["passed"]:
raise ValueError(f"Compliance validation failed: {compliance_results['issues']}")
# Deploy based on strategy
if deployment_strategy == "blue_green":
deployment_result = deploy_blue_green(
model=model,
context=context,
validation_dataset=validation_dataset
)
elif deployment_strategy == "canary":
deployment_result = deploy_canary(
model=model,
context=context,
canary_percentage=canary_percentage,
business_metrics=business_metrics
)
else:
deployment_result = deploy_standard(model=model, context=context)
# Log deployment metrics
context.log_results({
"deployment_strategy": deployment_strategy,
"deployment_time": datetime.utcnow().isoformat(),
"model_version": model.metadata.get("version", "unknown"),
"endpoint_url": deployment_result["endpoint_url"],
"health_check_passed": deployment_result["health_check"],
"compliance_approved": compliance_checks
})
return deployment_result
def run_compliance_validation(model, context):
"""Run enterprise compliance validation"""
# Implement your enterprise-specific compliance checks
return {"passed": True, "issues": []}
def deploy_blue_green(model, context, validation_dataset):
"""Implement blue-green deployment strategy"""
# Your blue-green deployment logic
return {
"endpoint_url": "https://model-api.company.com/v2/predict",
"health_check": True,
"deployment_type": "blue_green"
}
def deploy_canary(model, context, canary_percentage, business_metrics):
"""Implement canary deployment strategy"""
# Your canary deployment logic
return {
"endpoint_url": "https://model-api.company.com/v2/predict",
"health_check": True,
"deployment_type": "canary",
"canary_percentage": canary_percentage
}
# Register custom enterprise function
enterprise_deployer = project.set_function(
name="enterprise-model-deployer",
func=enterprise_model_deployment,
kind="job",
image="your-registry.com/mlrun-enterprise:latest",
requirements=[
"kubernetes>=24.0.0",
"requests>=2.28.0",
"pydantic>=1.10.0"
]
)
# Configure with enterprise security
enterprise_deployer.with_security_context(
k8s_client.V1SecurityContext(
run_as_user=1001,
run_as_group=1001,
run_as_non_root=True,
read_only_root_filesystem=True
)
)
# Add service account with deployment permissions
enterprise_deployer.spec.service_account = "mlrun-deployer"
MLRun's serving capabilities transform your trained models into enterprise-grade, auto-scaling inference services with advanced features like A/B testing, model ensembles, and intelligent routing.
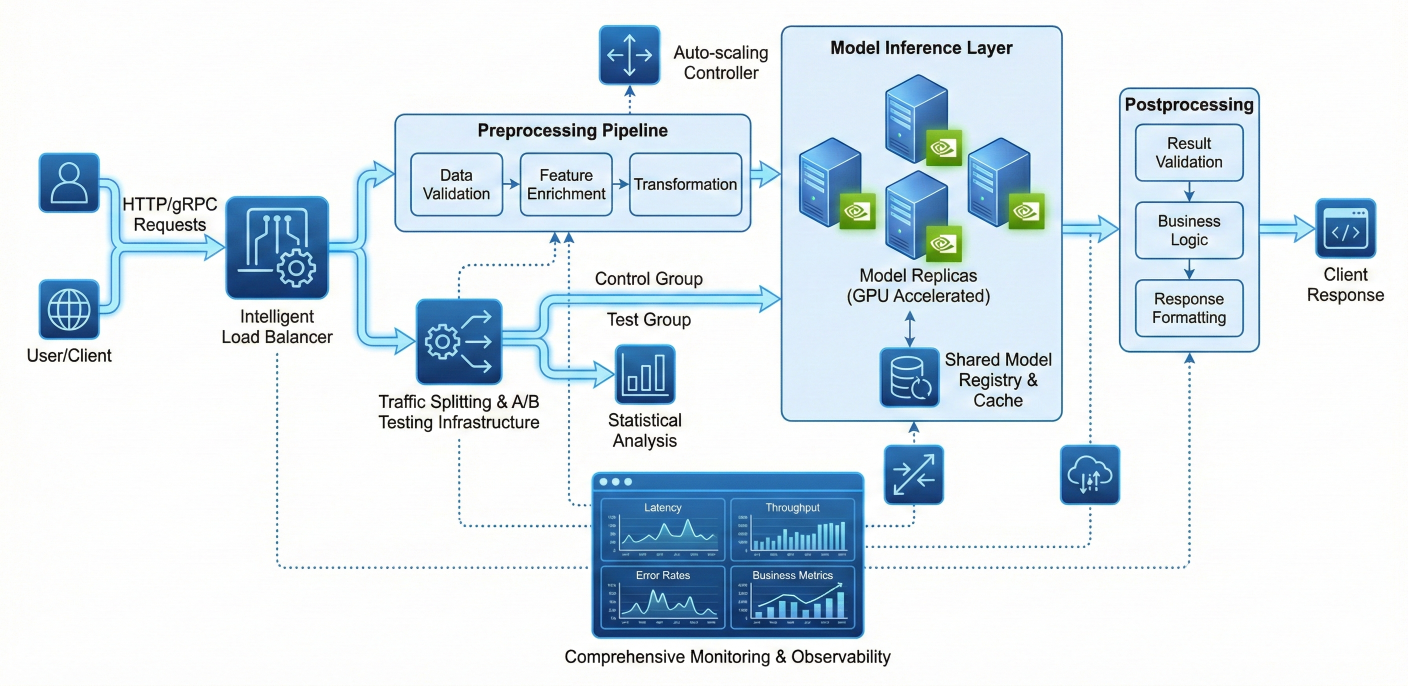
Advanced model serving architecture diagram showing HTTP/gRPC requests flowing through intelligent load balancer to preprocessing pipeline (data validation, feature enrichment, transformation), then through model inference layer with multiple model replicas and GPU acceleration, followed by postprocessing (result validation, business logic, response formatting), with comprehensive monitoring (latency, throughput, error rates, business metrics), auto-scaling controllers, and A/B testing infrastructure with traffic splitting and statistical analysis
import mlrun.serving as serving
import numpy as np
import pandas as pd
from typing import Dict, List, Any
import asyncio
import logging
# Create sophisticated serving pipeline
class EnterpriseChurnPredictionPipeline(serving.V2ModelServer):
"""
Enterprise-grade churn prediction serving pipeline with:
- Input validation and sanitization
- Feature enrichment from multiple sources
- Model ensemble predictions
- Business rule application
- Comprehensive logging and monitoring
"""
def load(self):
"""Initialize the serving pipeline components"""
# Load primary model
self.primary_model = self.get_model("churn_predictor_v2.pkl")
# Load ensemble models
self.ensemble_models = {
"xgb": self.get_model("xgb_churn_model.pkl"),
"lgb": self.get_model("lgb_churn_model.pkl"),
"rf": self.get_model("rf_churn_model.pkl")
}
# Load preprocessing artifacts
self.scaler = self.get_model("feature_scaler.pkl")
self.feature_selector = self.get_model("feature_selector.pkl")
# Load business rules engine
self.business_rules = self.load_business_rules()
# Initialize feature service
self.feature_service = mlrun.feature_store.get_online_feature_service(
"recommendation-features-v3"
)
# Initialize monitoring
self.metrics_collector = self.init_metrics_collector()
logging.info("Enterprise churn prediction pipeline loaded successfully")
def preprocess(self, request: Dict[str, Any]) -> Dict[str, Any]:
"""
Advanced preprocessing with validation and enrichment
"""
start_time = time.time()
try:
# Input validation
validated_input = self.validate_input(request)
# Extract customer ID
customer_id = validated_input.get("customer_id")
if not customer_id:
raise ValueError("customer_id is required")
# Enrich with real-time features
enriched_features = self.enrich_with_features(customer_id, validated_input)
# Apply preprocessing transformations
processed_features = self.apply_transformations(enriched_features)
# Log preprocessing metrics
preprocessing_time = time.time() - start_time
self.metrics_collector.log_metric("preprocessing_time", preprocessing_time)
return {
"customer_id": customer_id,
"features": processed_features,
"metadata": {
"preprocessing_time": preprocessing_time,
"feature_count": len(processed_features),
"enrichment_source": "real_time"
}
}
except Exception as e:
self.metrics_collector.log_error("preprocessing_error", str(e))
raise
def predict(self, request: Dict[str, Any]) -> Dict[str, Any]:
"""
Advanced prediction with ensemble and confidence scoring
"""
start_time = time.time()
try:
features = request["features"]
customer_id = request["customer_id"]
# Run ensemble predictions
ensemble_predictions = {}
for model_name, model in self.ensemble_models.items():
pred_proba = model.predict_proba(features.reshape(1, -1))[0]
ensemble_predictions[model_name] = {
"churn_probability": pred_proba[1],
"confidence": max(pred_proba) # Confidence as max probability
}
# Calculate weighted ensemble prediction
ensemble_result = self.calculate_ensemble_prediction(ensemble_predictions)
# Apply business rules
final_prediction = self.apply_business_rules(
customer_id=customer_id,
base_prediction=ensemble_result,
features=features
)
# Log prediction metrics
prediction_time = time.time() - start_time
self.metrics_collector.log_metric("prediction_time", prediction_time)
self.metrics_collector.log_prediction(customer_id, final_prediction)
return {
"customer_id": customer_id,
"churn_probability": final_prediction["churn_probability"],
"risk_level": final_prediction["risk_level"],
"confidence_score": final_prediction["confidence_score"],
"ensemble_details": ensemble_predictions,
"business_rules_applied": final_prediction.get("rules_applied", []),
"metadata": {
"prediction_time": prediction_time,
"model_version": "2.1.0",
"timestamp": time.time()
}
}
except Exception as e:
self.metrics_collector.log_error("prediction_error", str(e))
raise
def postprocess(self, request: Dict[str, Any]) -> Dict[str, Any]:
"""
Advanced postprocessing with business logic and recommendations
"""
try:
# Generate personalized recommendations
recommendations = self.generate_recommendations(
customer_id=request["customer_id"],
churn_probability=request["churn_probability"],
risk_level=request["risk_level"]
)
# Format response according to API contract
response = {
"prediction": {
"customer_id": request["customer_id"],
"churn_probability": round(request["churn_probability"], 4),
"risk_level": request["risk_level"],
"confidence": round(request["confidence_score"], 4)
},
"recommendations": recommendations,
"model_info": {
"version": request["metadata"]["model_version"],
"prediction_time_ms": round(request["metadata"]["prediction_time"] *
"timestamp": request["metadata"]["timestamp"]
}
}
# Log business metrics
self.metrics_collector.log_business_metric(
"churn_prediction_served",
request["risk_level"]
)
return response
except Exception as e:
self.metrics_collector.log_error("postprocessing_error", str(e))
raise
def validate_input(self, request: Dict[str, Any]) -> Dict[str, Any]:
"""Validate and sanitize input data"""
required_fields = ["customer_id"]
for field in required_fields:
if field not in request:
raise ValueError(f"Required field '{field}' is missing")
# Additional validation logic
return request
def enrich_with_features(self, customer_id: str, base_input: Dict[str, Any]) -> np.nd:
"""Enrich input with real-time features"""
try:
# Get real-time features
feature_vector = self.feature_service.get([{"customer_id": customer_id}])
# Combine with input features
enriched = {**base_input, **feature_vector}
# Convert to feature array
feature_array = self.feature_selector.transform([list(enriched.values())])
return feature_array[0]
except Exception as e:
logging.warning(f"Feature enrichment failed for {customer_id}: {e}")
# Fallback to basic features
return np.array(list(base_input.values()))
def apply_transformations(self, features: np.ndarray) -> np.ndarray:
"""Apply preprocessing transformations"""
return self.scaler.transform(features.reshape(1, -1))[0]
def calculate_ensemble_prediction(self, ensemble_predictions: Dict) -> Dict:
"""Calculate weighted ensemble prediction"""
# Model weights based on validation performance
model_weights = {"xgb": 0.4, "lgb": 0.35, "rf": 0.25}
weighted_probability = sum(
ensemble_predictions[model]["churn_probability"] * model_weights[model]
for model in model_weights
)
avg_confidence = np.mean([
pred["confidence"] for pred in ensemble_predictions.values()
])
return {
"churn_probability": weighted_probability,
"confidence_score": avg_confidence
}
def apply_business_rules(self, customer_id: str, base_prediction: Dict, features: np.):
"""Apply business rules to prediction"""
churn_prob = base_prediction["churn_probability"]
confidence = base_prediction["confidence_score"]
rules_applied = []
# High-value customer rule
if self.is_high_value_customer(customer_id):
if churn_prob > 0.3: # Lower threshold for high-value customers
churn_prob = min(churn_prob * 1.2, 0.95) # Increase urgency
rules_applied.append("high_value_customer_adjustment")
# Recent interaction rule
if self.has_recent_positive_interaction(customer_id):
churn_prob = churn_prob * 0.8 # Reduce churn probability
rules_applied.append("recent_positive_interaction")
# Determine risk level
if churn_prob >= 0.7:
risk_level = "HIGH"
elif churn_prob >= 0.4:
risk_level = "MEDIUM"
else:
risk_level = "LOW"
return {
"churn_probability": churn_prob,
"risk_level": risk_level,
"confidence_score": confidence,
"rules_applied": rules_applied
}
def generate_recommendations(self, customer_id: str, churn_probability: float, risk_l):
"""Generate personalized retention recommendations"""
recommendations = []
if risk_level == "HIGH":
recommendations.extend([
{"action": "immediate_personal_outreach", "priority": 1},
{"action": "exclusive_offer_25_percent", "priority": 1},
{"action": "schedule_retention_call", "priority": 2}
])
elif risk_level == "MEDIUM":
recommendations.extend([
{"action": "targeted_email_campaign", "priority": 2},
{"action": "loyalty_program_invite", "priority": 2},
{"action": "usage_survey", "priority": 3}
])
else:
recommendations.extend([
{"action": "general_satisfaction_survey", "priority": 3},
{"action": "product_recommendation", "priority": 4}
])
return recommendations
# Create and configure enterprise serving function
serving_function = project.set_function(
name="enterprise-churn-predictor",
kind="serving",
image="your-registry.com/mlrun-serving:latest",
requirements=[
"scikit-learn==1.3.0",
"pandas>=1.5.0",
"numpy>=1.21.0",
"redis>=4.0.0"
]
)
# Configure enterprise-grade resources
serving_function.with_limits(cpu="4000m", memory="8Gi")
serving_function.with_requests(cpu="1000m", memory="2Gi")
# Configure auto-scaling for production load
serving_function.spec.min_replicas = 3
serving_function.spec.max_replicas = 50
serving_function.spec.target_cpu = 70
serving_function.spec.target_memory = 80
# Add models to the serving function
serving_function.add_model(
"churn_predictor_v2",
model_path=training_run.outputs["model"],
class_name="EnterpriseChurnPredictionPipeline"
)
# Configure advanced networking
serving_function.with_annotations({
"nginx.ingress.kubernetes.io/rate-limit": "1000",
"nginx.ingress.kubernetes.io/rate-limit-window": "1m"
})
# Set up health checks
serving_function.set_env("HEALTH_CHECK_ENDPOINT", "/health")
serving_function.set_env("READINESS_TIMEOUT", "30")
# Configure monitoring and observability
serving_function.set_env("METRICS_ENABLED", "true")
serving_function.set_env("DETAILED_LOGGING", "true")
serving_function.set_env("TRACE_SAMPLING", "0.1")
# Deploy with blue-green strategy
deployment = project.deploy_function(
serving_function,
# Blue-green deployment configuration
deployment_mode="blue_green",
readiness_timeout=60,
# Advanced health checking
health_check_path="/health",
health_check_initial_delay=30
)
print(f"Model endpoint deployed: {deployment.status.address}")
print(f"Health check: {deployment.status.state}")
# Set up A/B testing infrastructure
class ABTestingPipeline(serving.V2ModelServer):
"""A/B testing pipeline for model comparison"""
def load(self):
# Load model variants
self.model_a = self.get_model("churn_model_v1.pkl") # Current champion
self.model_b = self.get_model("churn_model_v2.pkl") # New challenger
# A/B testing configuration
self.ab_config = {
"traffic_split": 0.9, # 90% to A, 10% to B
"minimum_samples": 1000,
"significance_level": 0.05,
"metrics": ["accuracy", "precision", "recall", "business_impact"]
}
# Initialize experiment tracker
self.experiment_tracker = ABExperimentTracker()
def predict(self, request: Dict[str, Any]) -> Dict[str, Any]:
customer_id = request["customer_id"]
# Determine which model to use
model_variant = self.select_model_variant(customer_id)
if model_variant == "A":
prediction = self.model_a.predict_proba(request["features"])[0]
model_version = "1.0"
else:
prediction = self.model_b.predict_proba(request["features"])[0]
model_version = "2.0"
result = {
"customer_id": customer_id,
"churn_probability": prediction[1],
"model_variant": model_variant,
"model_version": model_version
}
# Log for A/B testing analysis
self.experiment_tracker.log_prediction(
customer_id=customer_id,
model_variant=model_variant,
prediction=prediction[1],
features=request["features"]
)
return result
def select_model_variant(self, customer_id: str) -> str:
"""Determine which model variant to use"""
# Consistent hashing for stable assignment
import hashlib
hash_value = int(hashlib.md5(customer_id.encode()).hexdigest(), 16)
if hash_value % 100 < int(self.ab_config["traffic_split"] * 100):
return "A"
else:
return "B"
# Deploy A/B testing pipeline
ab_serving_function = project.set_function(
name="churn-ab-testing",
kind="serving",
image="mlrun/mlrun"
)
ab_serving_function.add_model(
"churn_ab_test",
class_name="ABTestingPipeline"
)
ab_deployment = project.deploy_function(ab_serving_function)
MLRun's pipeline capabilities enable sophisticated workflow orchestration with conditional logic, parallel processing, and enterprise-grade reliability.
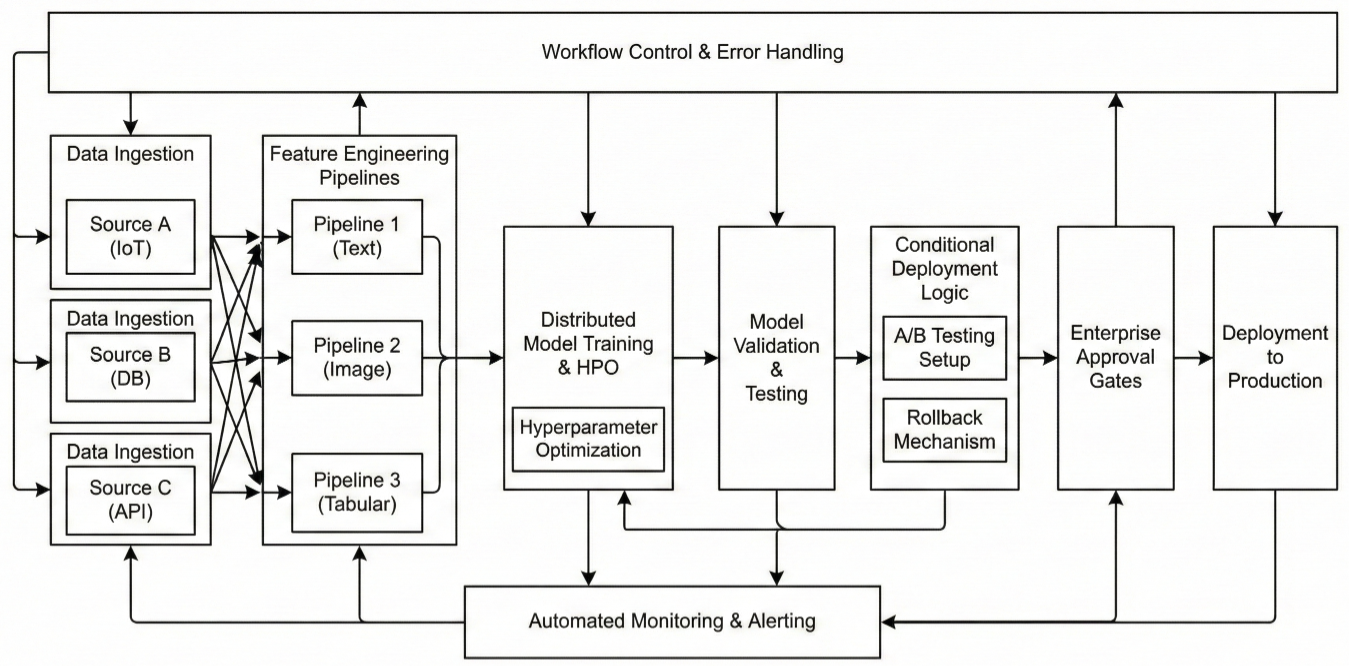
Complex ML pipeline orchestration diagram showing multiple parallel branches: data ingestion from multiple sources, parallel feature engineering pipelines, distributed model training with hyperparameter optimization, comprehensive model validation and testing, conditional deployment logic with A/B testing setup, automated monitoring and alerting, with detailed workflow control, error handling, rollback mechanisms, and enterprise approval gates
from kfp import dsl
from kfp.components import InputPath, OutputPath
import mlrun
from typing import Dict, List
@dsl.pipeline(
name="enterprise-ml-pipeline-v3",
description="Production ML pipeline with advanced orchestration and governance"
)
def enterprise_ml_pipeline(
# Data parameters
data_sources: List[str] = ["s3://raw-data/customers/", "s3://raw-data/transactions/"],
data_validation_rules: str = "strict",
feature_engineering_version: str = "v2",
# Training parameters
model_types: List[str] = ["xgboost", "lightgbm", "random_forest"],
optimization_budget: int = 100,
cross_validation_folds: int = 5,
# Deployment parameters
deployment_strategy: str = "blue_green",
canary_percentage: float = 10.0,
approval_required: bool = True,
# Governance parameters
compliance_checks: bool = True,
bias_testing: bool = True,
explainability_required: bool = True
):
# Stage 1: Data Ingestion and Validation
data_ingestion = mlrun.run_function(
"enterprise-data-ingestion",
name="data-ingestion",
params={
"data_sources": data_sources,
"validation_rules": data_validation_rules,
"quality_thresholds": {
"completeness": 0.95,
"consistency": 0.98,
"validity": 0.99
}
},
outputs=["raw_data", "data_quality_report"]
)
# Stage 2: Parallel Feature Engineering
user_features = mlrun.run_function(
"user-feature-engineering",
name="user-features",
inputs={"dataset": data_ingestion.outputs["raw_data"]},
params={{
"feature_set": "user_behavioral_v2",
"time_windows": ["1h", "6h", "24h", "7d", "30d"],
"aggregation_functions": ["sum", "mean", "std", "count", "max", "min"]
}},
outputs=["user_features"]
)
transaction_features = mlrun.run_function(
"transaction-feature-engineering",
name="transaction-features",
inputs={"dataset": data_ingestion.outputs["raw_data"]},
params={{
"feature_set": "transaction_patterns_v2",
"anomaly_detection": True,
"risk_scoring": True
}},
outputs=["transaction_features"]
)
# Stage 3: Feature Integration and Selection
feature_integration = mlrun.run_function(
"feature-integration",
name="integrate-features",
inputs={{
"user_features": user_features.outputs["user_features"],
"transaction_features": transaction_features.outputs["transaction_features"]
}},
params={{
"join_strategy": "outer",
"feature_selection_method": "mutual_info_classif",
"max_features": 100,
"correlation_threshold": 0.95
}},
outputs=["integrated_features", "feature_metadata"]
)
# Stage 4: Data Quality Validation Gate
with dsl.Condition(
data_ingestion.outputs["data_quality_report"].get("overall_quality", 0) > 0.90
) as quality_gate:
# Stage 5: Parallel Model Training
training_jobs = {}
for model_type in model_types:
training_jobs[model_type] = mlrun.run_function(
f"{model_type}-trainer",
name=f"train-{model_type}",
inputs={"dataset": feature_integration.outputs["integrated_features"]},
params={{
"model_type": model_type,
"optimization_trials": optimization_budget // len(model_types),
"cv_folds": cross_validation_folds,
"target_metric": "auc",
"enable_shap": explainability_required
}},
outputs=["model", "metrics", "validation_results"]
)
# Stage 6: Model Evaluation and Selection
model_evaluation = mlrun.run_function(
"model-evaluation-ensemble",
name="evaluate-models",
inputs={{
f"{model_type}_model": training_jobs[model_type].outputs["model"]
for model_type in model_types
}},
params={{
"evaluation_metrics": ["auc", "precision", "recall", "f1", "business_impact"],
"ensemble_methods": ["voting", "stacking", "blending"],
"cross_validation": True
}},
outputs=["best_model", "ensemble_model", "evaluation_report"]
).after(*training_jobs.values())
# Stage 7: Comprehensive Model Testing
with dsl.Condition(
model_evaluation.outputs["evaluation_report"].get("best_auc", 0) > 0.75
) as performance_gate:
# Bias and Fairness Testing
if bias_testing:
bias_test = mlrun.run_function(
"bias-fairness-testing",
name="bias-testing",
inputs={{"model": model_evaluation.outputs["best_model"]}},
params={{
"protected_attributes": ["age_group", "gender", "geography"],
"fairness_metrics": ["demographic_parity", "equalized_odds", "calibration"],
"bias_threshold": 0.1
}},
outputs=["bias_report"]
)
# Compliance and Governance Testing
if compliance_checks:
compliance_test = mlrun.run_function(
"compliance-testing",
name="compliance-check",
inputs={{"model": model_evaluation.outputs["best_model"]}},
params={{
"gdpr_compliance": True,
"right_to_explanation": explainability_required,
"audit_trail": True,
"data_lineage": True
}},
outputs=["compliance_report"]
)
# Stage 8: Model Approval Gate (if required)
if approval_required:
approval_task = mlrun.run_function(
"model-approval-workflow",
name="model-approval",
inputs={{
"model": model_evaluation.outputs["best_model"],
"evaluation_report": model_evaluation.outputs["evaluation_report"],
"bias_report": bias_test.outputs["bias_report"] if bias_testing else None,
"compliance_report": compliance_test.outputs["compliance_report"] if compliance_checks else None
}},
params={{
"approval_workflow": "automated_with_human_oversight",
"stakeholder_groups": ["data_science", "compliance", "business"],
"approval_timeout": "48h"
}},
outputs=["approval_decision", "approval_metadata"]
)
# Stage 9: Conditional Deployment
with dsl.Condition(
approval_task.outputs["approval_decision"] == "approved"
) as approval_gate:
deployment_job = mlrun.run_function(
"enterprise-model-deployer",
name="model-deployment",
inputs={"model": model_evaluation.outputs["best_model"]},
params={{
"deployment_strategy": deployment_strategy,
"canary_percentage": canary_percentage,
"health_check_timeout": 300,
"rollback_threshold": 0.95 # Rollback if performance drops below 95%
}},
outputs=["deployment_endpoint", "deployment_metadata"]
)
else:
# Direct deployment without approval
deployment_job = mlrun.run_function(
"enterprise-model-deployer",
name="model-deployment-direct",
inputs={"model": model_evaluation.outputs["best_model"]},
params={{
"deployment_strategy": deployment_strategy,
"canary_percentage": canary_percentage
}},
outputs=["deployment_endpoint", "deployment_metadata"]
).after(model_evaluation)
# Stage 10: Post-Deployment Setup
monitoring_setup = mlrun.run_function(
"setup-model-monitoring",
name="enable-monitoring",
inputs={"endpoint": deployment_job.outputs["deployment_endpoint"]},
params={{
"drift_detection": True,
"performance_monitoring": True,
"business_metrics_tracking": True,
"alert_thresholds": {{
"drift_score": 0.2,
"performance_degradation": 0.1,
"latency_threshold": 500 # ms
}}
}},
outputs=["monitoring_config"]
).after(deployment_job)
# Stage 11: Integration Testing
integration_test = mlrun.run_function(
"integration-testing",
name="post-deployment-testing",
inputs={"endpoint": deployment_job.outputs["deployment_endpoint"]},
params={{
"test_suite": "comprehensive",
"load_testing": True,
"concurrent_users": 100,
"test_duration": "10m"
}},
outputs=["test_results"]
).after(deployment_job)
# Stage 12: Pipeline Completion Notification
notification = mlrun.run_function(
"pipeline-notification",
name="completion-notification",
inputs={
"deployment_metadata": deployment_job.outputs["deployment_metadata"],
"test_results": integration_test.outputs["test_results"],
"monitoring_config": monitoring_setup.outputs["monitoring_config"]
},
params={
"notification_channels": ["slack", "email", "teams"],
"stakeholders": ["ml_team", "business_stakeholders", "ops_team"],
"include_performance_summary": True
}
).after(integration_test, monitoring_setup)
# Run the comprehensive pipeline
pipeline_run = project.run(
workflow_path="enterprise_ml_pipeline",
arguments={
"data_sources": ["s3://prod-data/customers/2024/", "s3://prod-data/transactions/2"],
"model_types": ["xgboost", "lightgbm"],
"optimization_budget": 200,
"deployment_strategy": "blue_green",
"approval_required": True,
"compliance_checks": True,
"bias_testing": True
},
# Pipeline-level configurations
resources={ "requests": {"cpu": "2000m", "memory": "4Gi"} },
ttl_seconds_after_finished=86400, # 24 hours
backoff_limit=3, # Retry failed steps up to 3 times
watch=True
)
print(f"Pipeline running: {pipeline_run.state()}")
@dsl.pipeline( name="robust-ml-pipeline-with-error-handling", description="ML pipeline with comprehensive error handling and recovery" ) def robust_ml_pipeline( fallback_model_path: str = "s3://models/fallback/churn_model_v1.pkl", max_retries: int = 3, error_notification_webhook: str = "https://hooks.slack.com/..." ): # Data processing with retry logic data_processing = mlrun.run_function( "robust-data-processor", name="data-processing", params={{ "max_retries": max_retries, "retry_delay": 60, # seconds "fallback_strategy": "use_cached_data" }}, outputs=["processed_data", "processing_status"] ) # Conditional training based on data quality with dsl.Condition( data_processing.outputs["processing_status"] == "success" ) as data_success: # Attempt primary training primary_training = mlrun.run_function( "primary-training", name="primary-model-training", inputs={{"dataset": data_processing.outputs["processed_data"]}}, params={{"training_mode": "full"}}, outputs=["model", "training_status", "metrics"] ) # Check training success with dsl.Condition( primary_training.outputs["training_status"] == "failed" ) as training_failed: # Fallback to simpler model fallback_training = mlrun.run_function( "fallback-training", name="fallback-model-training", inputs={{"dataset": data_processing.outputs["processed_data"]}}, params={{"model_type": "linear", "quick_mode": True}}, outputs=["fallback_model", "fallback_metrics"] ) # Error notification error_notification = mlrun.run_function( "error-handler", name="training-failure-notification", params={{ "error_type": "training_failure", "webhook_url": error_notification_webhook, "severity": "high" }} ).after(fallback_training) # Alternative data processing path with dsl.Condition( data_processing.outputs["processing_status"] == "failed" ) as data_failed: # Use fallback model fallback_deployment = mlrun.run_function( "deploy-fallback-model", name="emergency-fallback-deployment", params={{ "model_path": fallback_model_path, "deployment_mode": "emergency" }}, outputs=["emergency_endpoint"] ) # Critical error notification critical_notification = mlrun.run_function( "critical-error-handler", name="data-processing-failure", params={{ "error_type": "data_processing_failure", "webhook_url": error_notification_webhook, "severity": "critical", "escalation_required": True }} ).after(fallback_deployment)
MLRun provides sophisticated monitoring capabilities that go beyond basic drift detection to provide comprehensive production intelligence.
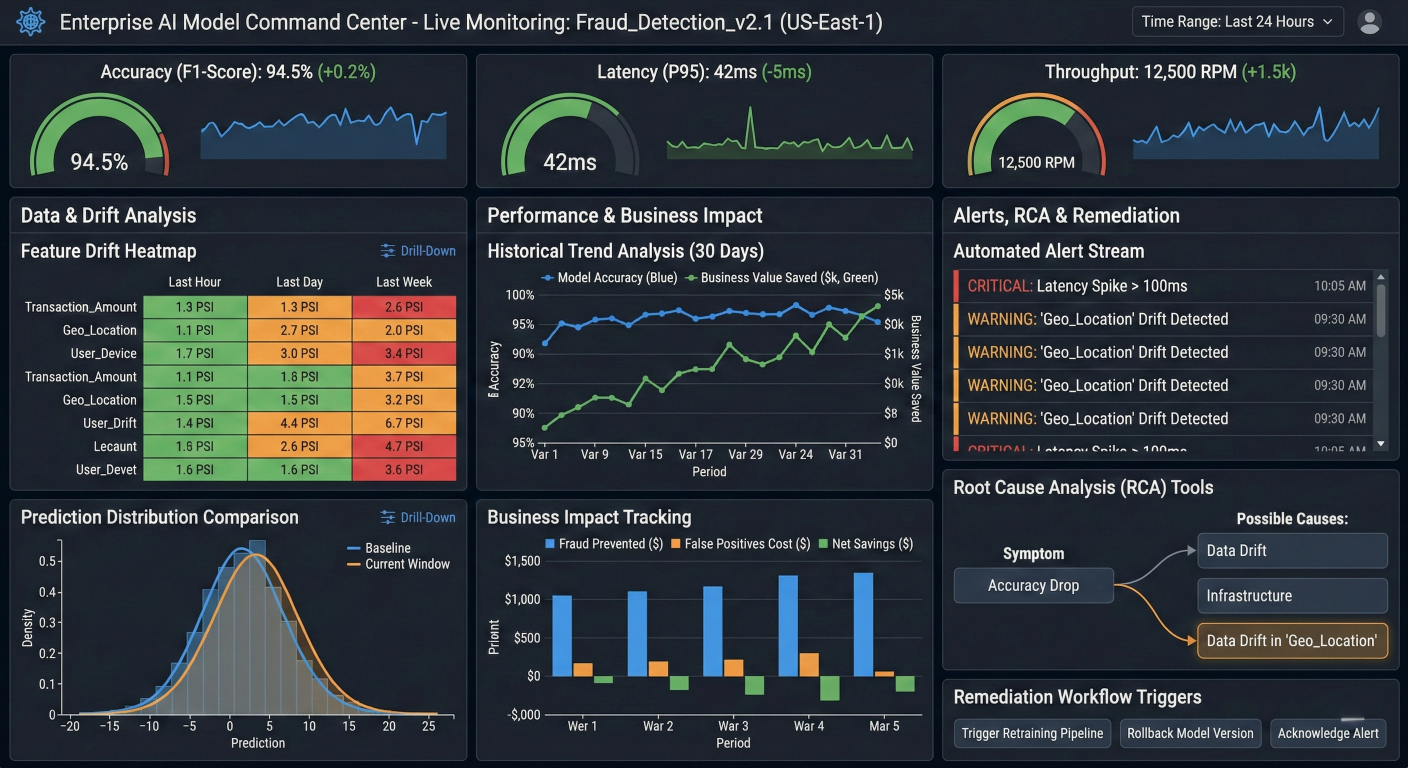
Comprehensive model monitoring dashboard showing real-time performance metrics (accuracy, latency, throughput), data drift analysis with feature-level heatmaps, prediction distribution comparisons, business impact tracking, automated alert configurations, root cause analysis tools, and remediation workflow triggers, with detailed drill-down capabilities and historical trend analysis
from mlrun.model_monitoring.applications import ModelMonitoringApplicationBase
from mlrun.common.schemas.model_monitoring import ResultKindApp, ResultStatusApp
import numpy as np
import pandas as pd
from scipy import stats
import json
from typing import Dict, List, Any
class EnterpriseModelMonitoringApp(ModelMonitoringApplicationBase):
"""
Comprehensive model monitoring application with:
- Multi-dimensional drift detection
- Performance degradation analysis
- Business impact monitoring
- Automated remediation triggers
"""
def __init__(self,
drift_threshold: float = 0.2,
performance_threshold: float = 0.1,
business_impact_threshold: float = 0.05,
remediation_enabled: bool = True):
super().__init__()
self.drift_threshold = drift_threshold
self.performance_threshold = performance_threshold
self.business_impact_threshold = business_impact_threshold
self.remediation_enabled = remediation_enabled
# Initialize monitoring components
self.drift_detectors = {
"ks_test": self.kolmogorov_smirnov_test,
"psi": self.population_stability_index,
"wasserstein": self.wasserstein_distance_test,
"js_divergence": self.jensen_shannon_divergence
}
def do_tracking(self, monitoring_context) -> List:
"""Comprehensive model monitoring analysis"""
results = []
try:
# Get current and reference data
current_data = monitoring_context.get_current_batch()
reference_data = monitoring_context.get_reference_data()
if current_data.empty or reference_data.empty:
return [self._create_warning_result("Insufficient data for monitoring")]
# 1. Data Drift Detection
drift_results = self.detect_data_drift(current_data, reference_data, monitori
results.extend(drift_results)
# 2. Prediction Drift Analysis
prediction_drift = self.analyze_prediction_drift(current_data, reference_data
results.extend(prediction_drift)
# 3. Performance Analysis
performance_results = self.analyze_model_performance(current_data, monitoring
results.extend(performance_results)
# 4. Business Impact Assessment
business_impact = self.assess_business_impact(current_data, monitoring_contex
results.extend(business_impact)
# 5. Automated Remediation
if self.remediation_enabled:
remediation_actions = self.trigger_remediation(results, monitoring_contex
results.extend(remediation_actions)
except Exception as e:
results.append(self._create_error_result(f"Monitoring failed: {str(e)}"))
return results
def detect_data_drift(self, current_data, reference_data, monitoring_context) -> List:
"""Advanced multi-method drift detection"""
drift_results = []
# Get numerical features
numerical_features = current_data.select_dtypes(include=[np.number]).columns
# Feature-level drift detection
feature_drift_scores = {}
for feature in numerical_features:
if feature in reference_data.columns:
current_values = current_data[feature].dropna()
reference_values = reference_data[feature].dropna()
if len(current_values) > 0 and len(reference_values) > 0:
# Apply multiple drift detection methods
drift_scores = {}
for method_name, method_func in self.drift_detectors.items():
try:
score = method_func(reference_values, current_values)
drift_scores[method_name] = score
except Exception as e:
monitoring_context.logger.warning(f"Drift detection failed fo")
# Aggregate drift scores
if drift_scores:
avg_drift_score = np.mean(list(drift_scores.values()))
feature_drift_scores[feature] = {
"score": avg_drift_score,
"methods": drift_scores,
"drift_detected": avg_drift_score > self.drift_threshold
}
# Overall drift assessment
if feature_drift_scores:
overall_drift_score = np.mean([f["score"] for f in feature_drift_scores.value])
drifted_features = [f for f, s in feature_drift_scores.items() if s["drift_de"]]
# Log detailed drift analysis
monitoring_context.log_artifact(
"feature_drift_analysis",
body=json.dumps(feature_drift_scores, indent=2),
format="json"
)
# Create drift result
drift_status = ResultStatusApp.anomaly_detected if overall_drift_score > self else None
drift_results.append({
"name": "data_drift_detection",
"value": overall_drift_score,
"status": drift_status,
"kind": ResultKindApp.mm_app_anomaly,
"extra_data": {
"drifted_features": drifted_features,
"drift_threshold": self.drift_threshold,
"total_features_analyzed": len(feature_drift_scores)
}
})
# Feature-specific alerts
for feature, drift_info in feature_drift_scores.items():
if drift_info["drift_detected"]:
drift_results.append({
"name": f"feature_drift_{feature}",
"value": drift_info["score"],
"status": ResultStatusApp.anomaly_detected,
"kind": ResultKindApp.mm_app_anomaly,
"extra_data": {"methods_used": list(drift_info["methods"].keys())}
})
return drift_results
def analyze_prediction_drift(self, current_data, reference_data, monitoring_context):
"""Analyze drift in model predictions"""
prediction_results = []
prediction_column = "prediction" # Assuming predictions are logged
if prediction_column in current_data.columns and prediction_column in reference_d:
current_predictions = current_data[prediction_column].dropna()
reference_predictions = reference_data[prediction_column].dropna()
if len(current_predictions) > 0 and len(reference_predictions) > 0:
# Statistical comparison of predictions
ks_stat, ks_pval = stats.ks_2samp(reference_predictions, current_predicti)
# Calculate prediction statistics
current_mean = current_predictions.mean()
reference_mean = reference_predictions.mean()
relative_change = abs(current_mean - reference_mean) / reference_mean if reference_mean else 0
# Determine if significant shift occurred
prediction_drift_detected = ks_pval < 0.05 or relative_change > 0.1
prediction_results.append({
"name": "prediction_drift",
"value": relative_change,
"status": ResultStatusApp.anomaly_detected if prediction_drift_detected else ResultStatusApp.no_anomaly,
"kind": ResultKindApp.mm_app_anomaly,
"extra_data": {
"current_mean": current_mean,
"reference_mean": reference_mean,
"ks_statistic": ks_stat,
"ks_pvalue": ks_pval
}
})
return prediction_results
def analyze_model_performance(self, current_data, monitoring_context) -> List:
"""Analyze real-time model performance metrics"""
performance_results = []
# Analyze prediction latency
if "prediction_latency" in current_data.columns:
latency_data = current_data["prediction_latency"].dropna()
if len(latency_data) > 0:
avg_latency = latency_data.mean()
p95_latency = latency_data.quantile(0.95)
p99_latency = latency_data.quantile(0.99)
# Check latency thresholds
latency_alert = p95_latency > 500 # 500ms threshold
performance_results.append({
"name": "prediction_latency",
"value": avg_latency,
"status": ResultStatusApp.anomaly_detected if latency_alert else ResultStatusApp.no_anomaly,
"kind": ResultKindApp.mm_app_performance,
"extra_data": {
"p95_latency": p95_latency,
"p99_latency": p99_latency,
"samples": len(latency_data)
}
})
# Analyze throughput
if "timestamp" in current_data.columns:
time_window = monitoring_context.end_infer_time - monitoring_context.start_in
throughput = len(current_data) / time_window.total_seconds() * 60 # per minute
performance_results.append({
"name": "throughput",
"value": throughput,
"status": ResultStatusApp.no_anomaly,
"kind": ResultKindApp.mm_app_performance,
"extra_data": {
"requests_per_minute": throughput,
"time_window_seconds": time_window.total_seconds()
}
})
return performance_results
def assess_business_impact(self, current_data, monitoring_context) -> List:
"""Assess business impact of model performance"""
business_results = []
# Business-specific metrics (customize based on use case)
if "conversion_rate" in current_data.columns:
current_conversion = current_data["conversion_rate"].mean()
# Compare with historical benchmark
benchmark_conversion = 0.15 # Example benchmark
impact_ratio = (current_conversion - benchmark_conversion) / benchmark_conversion
business_results.append({
"name": "business_conversion_impact",
"value": impact_ratio,
"status": ResultStatusApp.anomaly_detected if abs(impact_ratio) > self.bu else ResultStatusApp.no_anomaly,
"kind": ResultKindApp.mm_app_business,
"extra_data": {
"current_conversion_rate": current_conversion,
"benchmark_conversion_rate": benchmark_conversion
}
})
return business_results
def trigger_remediation(self, monitoring_results, monitoring_context) -> List:
"""Trigger automated remediation actions based on monitoring results"""
remediation_results = []
# Check if critical issues detected
critical_issues = [r for r in monitoring_results if r.get("status") == ResultStat]
if critical_issues:
# Trigger retraining if data drift detected
data_drift_issues = [r for r in critical_issues if "drift" in r.get("name", "")]
if data_drift_issues:
# Schedule retraining job
try:
self.schedule_retraining(monitoring_context)
remediation_results.append({
"name": "retraining_scheduled",
"value": 1,
"status": ResultStatusApp.no_anomaly,
"kind": ResultKindApp.mm_app_remediation,
"extra_data": {"trigger": "data_drift_detected"}
})
except Exception as e:
remediation_results.append({
"name": "retraining_failed_to_schedule",
"value": 0,
"status": ResultStatusApp.anomaly_detected,
"kind": ResultKindApp.mm_app_remediation,
"extra_data": {"error": str(e)}
})
return remediation_results
def schedule_retraining(self, monitoring_context):
"""Schedule automatic model retraining"""
project = monitoring_context.project
# Trigger retraining pipeline
retraining_run = project.run(
workflow_path="retraining_pipeline",
arguments={
"trigger_reason": "data_drift_detected",
"model_endpoint": monitoring_context.model_endpoint.metadata.name,
"drift_score": "high" # Pass drift severity
},
schedule="now"
)
monitoring_context.logger.info(f"Retraining scheduled: {retraining_run.uid}")
# Drift detection methods
def kolmogorov_smirnov_test(self, reference_data, current_data):
"""Kolmogorov-Smirnov test for drift detection"""
statistic, pvalue = stats.ks_2samp(reference_data, current_data)
return statistic
def population_stability_index(self, reference_data, current_data, buckets=10):
"""Population Stability Index calculation"""
try:
# Create bins based on reference data
_, bin_edges = np.histogram(reference_data, bins=buckets)
# Calculate distributions
ref_counts, _ = np.histogram(reference_data, bins=bin_edges)
cur_counts, _ = np.histogram(current_data, bins=bin_edges)
# Convert to percentages
ref_percents = ref_counts / len(reference_data) + 1e-8
cur_percents = cur_counts / len(current_data) + 1e-8
# Calculate PSI
psi = np.sum((cur_percents - ref_percents) * np.log(cur_percents / ref_percents))
return psi
except:
return 0.0
def wasserstein_distance_test(self, reference_data, current_data):
"""Wasserstein distance calculation"""
return stats.wasserstein_distance(reference_data, current_data)
def jensen_shannon_divergence(self, reference_data, current_data, bins=50):
"""Jensen-Shannon divergence calculation"""
try:
combined_data = np.concatenate([reference_data, current_data])
bin_edges = np.histogram_bin_edges(combined_data, bins=bins)
ref_hist, _ = np.histogram(reference_data, bins=bin_edges, density=True)
cur_hist, _ = np.histogram(current_data, bins=bin_edges, density=True)
ref_prob = ref_hist / np.sum(ref_hist) + 1e-8
cur_prob = cur_hist / np.sum(cur_hist) + 1e-8
m = 0.5 * (ref_prob + cur_prob)
js_div = 0.5 * stats.entropy(ref_prob, m) + 0.5 * stats.entropy(cur_prob, m)
return js_div
except:
return 0.0
def _create_warning_result(self, message):
"""Create warning result"""
return {
"name": "monitoring_warning",
"value": 0,
"status": ResultStatusApp.irrelevant,
"kind": ResultKindApp.mm_app_anomaly,
"extra_data": {"message": message}
}
def _create_error_result(self, message):
"""Create error result"""
return {
"name": "monitoring_error",
"value": 1,
"status": ResultStatusApp.anomaly_detected,
"kind": ResultKindApp.mm_app_anomaly,
"extra_data": {"error": message}
}
# Deploy the enterprise monitoring application
enterprise_monitoring_app = project.set_model_monitoring_function(
func=EnterpriseModelMonitoringApp(
drift_threshold=0.15,
performance_threshold=0.1,
business_impact_threshold=0.05,
remediation_enabled=True
),
name="enterprise-model-monitoring",
image="mlrun/mlrun",
requirements=["scipy>=1.9.0", "pandas>=1.5.0"]
)
# Enable comprehensive model monitoring
project.enable_model_monitoring(
base_period=5, # Check every 5 minutes
default_batch_image="mlrun/mlrun:1.6.0",
deploy_histogram_data_drift_app=True,
deploy_drift_stream=True
)
# Configure monitoring for specific endpoint
serving_fn.set_tracking(
stream_path="kafka://model-monitoring-stream",
batch_window="1h",
sample_window="10m"
)
print("Advanced model monitoring enabled")
from mlrun.alerts import AlertConfig, AlertSeverity
from mlrun.common.schemas.alert import EventKind, EventEntityKind
# Configure comprehensive alerting system
def setup_enterprise_alerts(project, model_endpoint_id):
"""
Set up comprehensive alerting for enterprise model monitoring
"""
# High-severity alerts
high_severity_alerts = [
{
"name": "critical_data_drift",
"summary": "Critical data drift detected - immediate attention required",
"severity": AlertSeverity.HIGH,
"events": [EventKind.DATA_DRIFT_DETECTED],
"condition": "drift_score > 0.3",
"notifications": [
"slack://ml-alerts-critical",
"email://ml-team-leads@company.com",
"pagerduty://ml-oncall"
],
"auto_remediation": True
},
{
"name": "model_performance_degradation",
"summary": "Significant model performance degradation detected",
"severity": AlertSeverity.HIGH,
"events": [EventKind.MODEL_PERFORMANCE_DRIFT_DETECTED],
"condition": "performance_drop > 0.15",
"notifications": [
"slack://ml-alerts-critical",
"email://business-stakeholders@company.com"
],
"escalation_policy": "ml_team_escalation"
}
]
# Medium-severity alerts
medium_severity_alerts = [
{
"name": "feature_drift_warning",
"summary": "Feature drift detected in multiple features",
"severity": AlertSeverity.MEDIUM,
"events": [EventKind.DATA_DRIFT_DETECTED],
"condition": "drifted_features_count > 3",
"notifications": [
"slack://ml-alerts",
"email://data-science-team@company.com"
]
},
{
"name": "prediction_latency_high",
"summary": "Model prediction latency exceeding SLA",
"severity": AlertSeverity.MEDIUM,
"events": [EventKind.MODEL_PERFORMANCE_DRIFT_DETECTED],
"condition": "p95_latency > 500",
"notifications": ["slack://ml-alerts-performance"]
}
]
# Low-severity alerts
low_severity_alerts = [
{
"name": "throughput_anomaly",
"summary": "Unusual traffic pattern detected",
"severity": AlertSeverity.LOW,
"events": [EventKind.DATA_DRIFT_DETECTED],
"condition": "throughput_change > 0.5",
"notifications": ["slack://ml-monitoring"]
}
]
# Create and store all alerts
all_alerts = high_severity_alerts + medium_severity_alerts + low_severity_alerts
for alert_config in all_alerts:
alert = AlertConfig(
project=project.metadata.name,
name=alert_config["name"],
summary=alert_config["summary"],
severity=alert_config["severity"],
entities={
"kind": EventEntityKind.MODEL_ENDPOINT_RESULT,
"project": project.metadata.name,
"ids": [model_endpoint_id]
},
trigger={
"events": alert_config["events"]
},
notifications=alert_config["notifications"]
)
project.store_alert_config(alert)
print(f"✅ Alert configured: {alert_config['name']}")
# Set up alerts for deployed model
setup_enterprise_alerts(project, deployment.status.model_endpoint_id)
MLRun provides enterprise-grade security, scalability, and integration capabilities essential for production deployments.
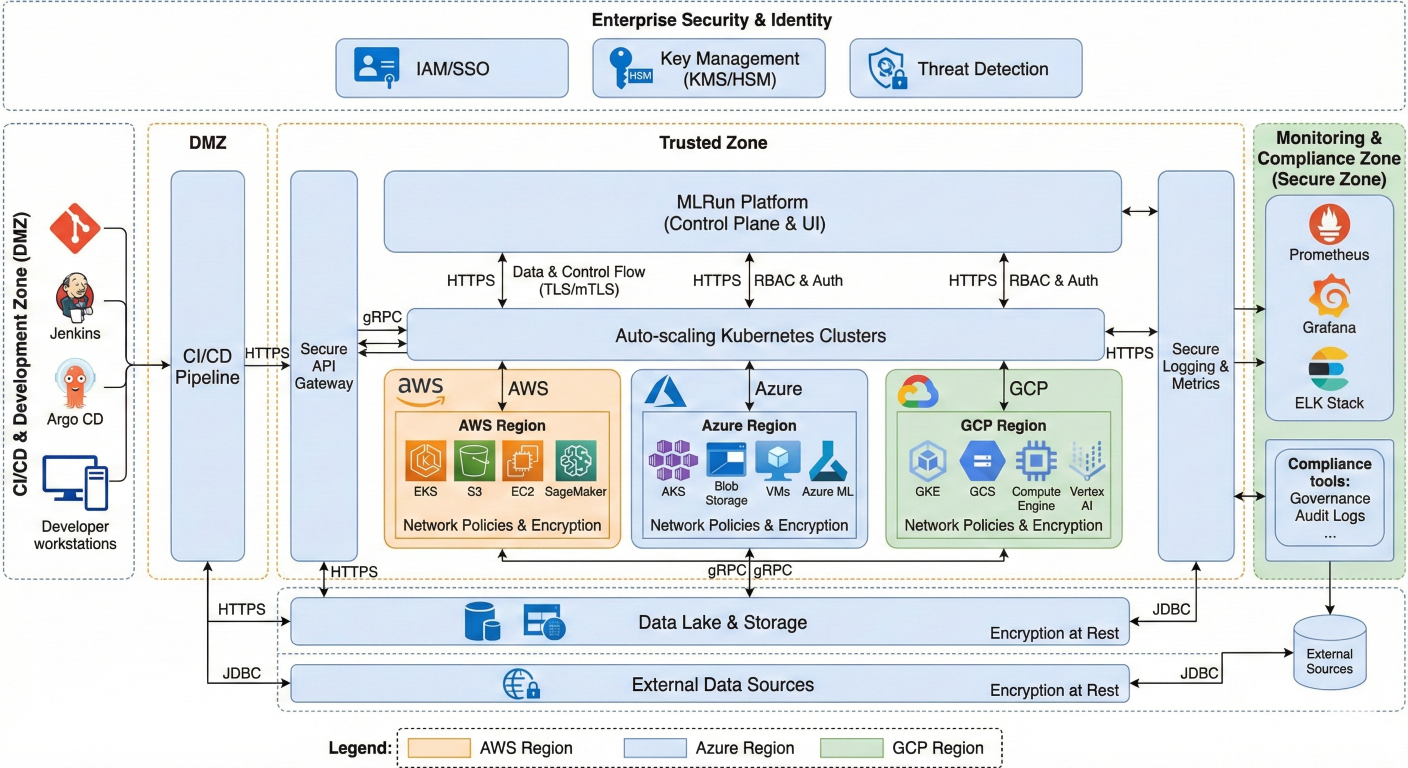
Enterprise MLRun deployment architecture showing multi-cloud setup with security layers (RBAC, encryption, network policies), auto-scaling infrastructure, integration points with major cloud providers (AWS, Azure, GCP), CI/CD pipelines, monitoring systems, and compliance frameworks, displayed as a comprehensive enterprise architecture diagram with security zones and data flow paths
# mlrun-rbac.yaml - Enterprise RBAC Configuration
apiVersion: v1
kind: ServiceAccount
metadata:
name: mlrun-data-scientist
namespace: mlrun
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: mlrun
name: mlrun-data-scientist
rules:
- apiGroups: [""]
resources: ["pods", "pods/log", "configmaps", "secrets"]
verbs: ["get", "list", "create", "update", "patch", "delete"]
- apiGroups: ["apps"]
resources: ["deployments"]
verbs: ["get", "list", "create", "update", "patch"]
- apiGroups: ["mlrun.org"]
resources: ["functions", "models", "features"]
verbs: ["get", "list", "create", "update", "patch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: mlrun-data-scientist-binding
namespace: mlrun
subjects:
- kind: ServiceAccount
name: mlrun-data-scientist
namespace: mlrun
roleRef:
kind: Role
name: mlrun-data-scientist
apiGroup: rbac.authorization.k8s.io
from kubernetes import client as k8s_client
def configure_enterprise_security(function):
"""Configure enterprise-grade security for MLRun functions"""
# Security context with non-root user
security_context = k8s_client.V1SecurityContext(
run_as_user=1000,
run_as_group=1000,
run_as_non_root=True,
read_only_root_filesystem=True,
allow_privilege_escalation=False,
capabilities=k8s_client.V1Capabilities(
drop=["ALL"]
),
seccomp_profile=k8s_client.V1SeccompProfile(type="RuntimeDefault")
)
function.with_security_context(security_context)
# Pod security context
pod_security_context = k8s_client.V1PodSecurityContext(
run_as_user=1000,
run_as_group=1000,
run_as_non_root=True,
fs_group=2000,
seccomp_profile=k8s_client.V1SeccompProfile(type="RuntimeDefault")
)
function.spec.pod_security_context = pod_security_context
# Network policies
function.with_annotations({
"network-policy.kubernetes.io/ingress": "restricted",
"network-policy.kubernetes.io/egress": "restricted"
})
# Resource constraints for security
function.with_limits(cpu="4000m", memory="8Gi")
function.with_requests(cpu="100m", memory="256Mi")
return function
# Apply security to all functions
secure_function = configure_enterprise_security(data_processor)
# Enterprise secrets management
def setup_secure_secrets(project):
"""Set up secure secrets management"""
# Database credentials
project.set_secrets({
"DB_CONNECTION_STRING": "postgresql://user:pass@db-host:5432/mlrun",
"REDIS_URL": "redis://redis-cluster:6379/0",
"S3_ACCESS_KEY": "AKIA...",
"S3_SECRET_KEY": "...",
"API_KEY": "secret-api-key"
}, provider="kubernetes")
# TLS certificates
project.create_secret(
"tls-certificate",
secret_data={
"tls.crt": "certificate-content",
"tls.key": "private-key-content"
},
secret_type="kubernetes.io/tls"
)
# Docker registry credentials
project.create_secret(
"docker-registry-secret",
secret_data={
".dockerconfigjson": json.dumps({
"auths": {
"your-registry.com": {
"username": "registry-user",
"password": "registry-pass",
"auth": "encoded-auth"
}
}
})
},
secret_type="kubernetes.io/dockerconfigjson"
)
# Configure secure function with secrets
secure_function.with_secrets("kubernetes", ["DB_CONNECTION_STRING", "API_KEY"])
# Enterprise auto-scaling configuration
def configure_enterprise_scaling(function, workload_type="ml_training"):
"""Configure enterprise-grade auto-scaling and resource management"""
scaling_configs = {
"ml_training": {
"min_replicas": 1,
"max_replicas": 20,
"target_cpu": 70,
"target_memory": 80,
"scale_up_delay": "30s",
"scale_down_delay": "300s",
"requests": {"cpu": "2000m", "memory": "8Gi"},
"limits": {"cpu": "8000m", "memory": "32Gi"}
},
"model_serving": {
"min_replicas": 3,
"max_replicas": 50,
"target_cpu": 60,
"target_memory": 70,
"scale_up_delay": "10s",
"scale_down_delay": "60s",
"requests": {"cpu": "500m", "memory": "2Gi"},
"limits": {"cpu": "2000m", "memory": "4Gi"}
},
"feature_serving": {
"min_replicas": 2,
"max_replicas": 30,
"target_cpu": 65,
"target_memory": 75,
"scale_up_delay": "15s",
"scale_down_delay": "120s",
"requests": {"cpu": "1000m", "memory": "4Gi"},
"limits": {"cpu": "4000m", "memory": "8Gi"}
}
}
config = scaling_configs.get(workload_type, scaling_configs["ml_training"])
# Configure auto-scaling
function.spec.min_replicas = config["min_replicas"]
function.spec.max_replicas = config["max_replicas"]
function.spec.target_cpu = config["target_cpu"]
# Resource allocation
function.with_requests(**config["requests"])
function.with_limits(**config["limits"])
# Advanced scaling behavior
function.with_annotations({
"autoscaling.knative.dev/scale-up-delay": config["scale_up_delay"],
"autoscaling.knative.dev/scale-down-delay": config["scale_down_delay"],
"autoscaling.knative.dev/target-utilization-percentage": str(config["target_cpu"])
})
# Node affinity for optimal placement
function.with_node_selection({
"node.kubernetes.io/instance-type": "c5.2xlarge",
"topology.kubernetes.io/zone": "us-west-2a"
})
# Pod disruption budget
function.with_annotations({
"pod-disruption-budget.kubernetes.io/min-available": "50%"
})
return function
# Apply scaling configuration
scaled_serving_function = configure_enterprise_scaling(
serving_function,
workload_type="model_serving"
)
# Multi-cloud deployment configuration
class MultiCloudMLRunDeployment:
"""Manage MLRun deployments across multiple cloud providers"""
def __init__(self):
self.cloud_configs = {
"aws": {
"cluster_endpoint": "https://eks-cluster.us-west-2.amazonaws.com",
"storage_class": "gp3",
"node_groups": ["ml-optimized", "cpu-optimized"],
"availability_zones": ["us-west-2a", "us-west-2b", "us-west-2c"]
},
"azure": {
"cluster_endpoint": "https://aks-cluster.eastus.cloudapp.azure.com",
"storage_class": "premium-ssd",
"node_groups": ["ml-nodes", "general-purpose"],
"availability_zones": ["1", "2", "3"]
},
"gcp": {
"cluster_endpoint": "https://gke-cluster.us-central1.googleapis.com",
"storage_class": "ssd",
"node_groups": ["ml-pool", "preemptible-pool"],
"availability_zones": ["us-central1-a", "us-central1-b", "us-central1-c"]
}
}
def deploy_to_cloud(self, project, cloud_provider, deployment_config):
"""Deploy MLRun project to specific cloud provider"""
cloud_config = self.cloud_configs[cloud_provider]
# Set cloud-specific configurations
project.set_annotation("cloud.provider", cloud_provider)
project.set_annotation("cluster.endpoint", cloud_config["cluster_endpoint"])
# Configure storage
for function in project.functions:
function.with_annotation("storage.class", cloud_config["storage_class"])
# Cloud-specific optimizations
if cloud_provider == "aws":
function.with_node_selection({"node.kubernetes.io/instance-type": "c5.2xl"})
function.with_annotation("cluster-autoscaler.kubernetes.io/safe-to-evict")
elif cloud_provider == "azure":
function.with_node_selection({"agentpool": "ml-nodes"})
function.with_annotation("kubernetes.azure.com/scalesetpriority", "regular")
elif cloud_provider == "gcp":
function.with_node_selection({"cloud.google.com/machine-family": "c2"})
function.with_annotation("cluster-autoscaler.kubernetes.io/safe-to-evict")
# Deploy with cloud-specific parameters
deployment_result = project.deploy(
target=cloud_provider,
wait_for_completion=True,
**deployment_config
)
return deployment_result
def setup_cross_cloud_replication(self, primary_cloud, backup_clouds):
"""Set up cross-cloud replication for high availability"""
# Configure data replication
replication_config = {
"primary": primary_cloud,
"replicas": backup_clouds,
"sync_interval": "1h",
"consistency_level": "eventual"
}
# Set up model registry replication
model_registry_replication = {
"enabled": True,
"cross_region": True,
"encryption": True
}
return {
"data_replication": replication_config,
"model_registry": model_registry_replication
}
# Deploy to multiple clouds
multi_cloud_deployer = MultiCloudMLRunDeployment()
# Primary deployment on AWS
aws_deployment = multi_cloud_deployer.deploy_to_cloud(
project,
"aws",
{
"high_availability": True,
"auto_scaling": True,
"monitoring": "enhanced"
}
)
# Backup deployment on Azure
azure_deployment = multi_cloud_deployer.deploy_to_cloud(
project,
"azure",
{
"high_availability": False,
"auto_scaling": True,
"monitoring": "standard"
}
)
# .github/workflows/enterprise-ml-pipeline.yml
name: Enterprise ML Pipeline
on:
push:
branches: [main, develop]
pull_request:
branches: [main]
schedule:
- cron: '0 2 * * *' # Daily retraining
env:
MLRUN_DBPATH: ${{ secrets.MLRUN_DBPATH }}
MLRUN_ACCESS_KEY: ${{ secrets.MLRUN_ACCESS_KEY }}
DOCKER_REGISTRY: your-registry.company.com
jobs:
security-scan:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Security scan
uses: securecodewarrior/github-action-security-scan@v1
with:
api-key: ${{ secrets.SCW_API_KEY }}
- name: Dependency vulnerability scan
run: |
pip install safety
safety check -r requirements.txt
code-quality:
runs-on: ubuntu-latest
needs: security-scan
steps:
- uses: actions/checkout@v3
- name: Code quality analysis
uses: sonarqube-quality-gate-action@master
env:
SONAR_TOKEN: ${{ secrets.SONAR_TOKEN }}
build-and-test:
runs-on: ubuntu-latest
needs: [security-scan, code-quality]
steps:
- uses: actions/checkout@v3
- name: Setup Python
uses: actions/setup-python@v4
with:
python-version: '3.9'
- name: Install dependencies
run: |
pip install mlrun[complete]
pip install -r requirements.txt
- name: Run unit tests
run: |
pytest tests/unit/ --cov=src --cov-report=xml
- name: Run integration tests
run: |
pytest tests/integration/ --maxfail=1
ml-pipeline-staging:
runs-on: ubuntu-latest
needs: build-and-test
if: github.ref == 'refs/heads/develop'
steps:
- uses: actions/checkout@v3
- name: Deploy to staging
run: |
python -m mlrun project ./ \
--run-pipeline enterprise_ml_pipeline \
--env staging \
--wait \
--arguments '{
"deployment_strategy": "blue_green",
"approval_required": false,
"compliance_checks": true
}'
ml-pipeline-production:
runs-on: ubuntu-latest
needs: build-and-test
if: github.ref == 'refs/heads/main'
environment: production
steps:
- uses: actions/checkout@v3
- name: Deploy to production
run: |
python -m mlrun project ./ \
--run-pipeline enterprise_ml_pipeline \
--env production \
--wait \
--arguments '{
"deployment_strategy": "blue_green",
"approval_required": true,
"compliance_checks": true,
"bias_testing": true,
"explainability_required": true
}'
- name: Post-deployment validation
run: |
python scripts/validate_deployment.py \
--endpoint ${{ env.MODEL_ENDPOINT }} \
--test-data data/validation/test_cases.json
- name: Update documentation
run: |
python scripts/update_model_catalog.py \
--model-version ${{ github.sha }} \
--deployment-timestamp $(date -Iseconds)
monitoring-setup:
runs-on: ubuntu-latest
needs: ml-pipeline-production
if: github.ref == 'refs/heads/main'
steps:
- name: Enable enhanced monitoring
run: |
python scripts/setup_production_monitoring.py \
--model-endpoint ${{ env.MODEL_ENDPOINT }} \
--monitoring-level enterprise \
--alert-channels slack,email,pagerduty
# Financial risk assessment pipeline
class FinancialRiskAssessmentPipeline(serving.V2ModelServer):
"""Real-time financial risk assessment with regulatory compliance"""
def load(self):
# Load multiple specialized models
self.fraud_model = self.get_model("fraud_detection_v3.pkl")
self.credit_risk_model = self.get_model("credit_risk_v2.pkl")
self.aml_model = self.get_model("aml_screening_v1.pkl")
self.market_risk_model = self.get_model("market_risk_v1.pkl")
# Load regulatory rules engine
self.regulatory_engine = RegulatoryComplianceEngine()
# Initialize real-time feature services
self.customer_features = mlrun.feature_store.get_online_feature_service("customer")
self.transaction_features = mlrun.feature_store.get_online_feature_service("transaction")
self.market_features = mlrun.feature_store.get_online_feature_service("market-context")
def predict(self, request):
transaction = request["transaction"]
customer_id = transaction["customer_id"]
# Get real-time features
customer_profile = self.customer_features.get([{"customer_id": customer_id}])
transaction_context = self.transaction_features.get([{"customer_id": customer_id, "merchant_id": transaction["merchant_id"]}])
market_conditions = self.market_features.get([{"timestamp": transaction["timestamp"]}])
# Combined feature vector
features = {**transaction, **customer_profile, **transaction_context, **market_conditions}
# Multi-model risk assessment
risk_scores = {
"fraud_score": self.fraud_model.predict_proba(features)[0][1],
"credit_risk": self.credit_risk_model.predict_proba(features)[0][1],
"aml_risk": self.aml_model.predict_proba(features)[0][1],
"market_risk": self.market_risk_model.predict(features)[0]
}
# Apply regulatory compliance rules
compliance_result = self.regulatory_engine.evaluate(
transaction=transaction,
risk_scores=risk_scores,
customer_profile=customer_profile
)
# Calculate overall risk and decision
overall_risk = self.calculate_composite_risk(risk_scores)
decision = self.make_risk_decision(overall_risk, compliance_result)
return {
"transaction_id": transaction["transaction_id"],
"overall_risk_score": overall_risk,
"individual_risks": risk_scores,
"decision": decision,
"compliance_status": compliance_result,
"processing_time": time.time() - request.get("start_time", time.time())
}
# Clinical decision support system
class ClinicalDecisionSupportPipeline(serving.V2ModelServer):
""" HIPAA-compliant clinical decision support with explainability """
def load(self):
# Load clinical models
self.diagnosis_model = self.get_model("clinical_diagnosis_v2.pkl")
self.treatment_recommendation = self.get_model("treatment_optimizer_v1.pkl")
self.risk_stratification = self.get_model("patient_risk_v2.pkl")
# Load medical knowledge base
self.knowledge_base = MedicalKnowledgeBase()
self.drug_interaction_checker = DrugInteractionChecker()
# HIPAA compliance components
self.audit_logger = HIPAAAuditLogger()
self.data_anonymizer = MedicalDataAnonymizer()
def predict(self, request):
# Anonymize patient data for compliance
anonymized_data = self.data_anonymizer.anonymize(request["patient_data"])
# Log access for HIPAA compliance
self.audit_logger.log_access(
user_id=request["user_id"],
patient_id=request["patient_data"]["patient_id"],
access_type="clinical_decision_support"
)
# Extract clinical features
clinical_features = self.extract_clinical_features(anonymized_data)
# Multi-model predictions
diagnosis_prediction = self.diagnosis_model.predict_proba(clinical_features)
risk_score = self.risk_stratification.predict(clinical_features)[0]
# Generate treatment recommendations
treatment_options = self.treatment_recommendation.predict(clinical_features)
# Check drug interactions
interaction_warnings = self.drug_interaction_checker.check_interactions(
current_medications=anonymized_data.get("medications", []),
proposed_treatments=treatment_options
)
# Generate explanations for clinical decisions
explanations = self.generate_clinical_explanations(
diagnosis_prediction,
clinical_features,
treatment_options
)
return {
"diagnosis_probabilities": diagnosis_prediction,
"risk_stratification": risk_score,
"treatment_recommendations": treatment_options,
"drug_interaction_warnings": interaction_warnings,
"clinical_explanations": explanations,
"confidence_intervals": self.calculate_confidence_intervals(),
"evidence_quality": self.assess_evidence_quality(clinical_features)
}
class EnterpriseDeploymentValidator:
"""Comprehensive validation for enterprise MLRun deployments"""
def __init__(self):
self.validation_checks = [
self.validate_security_configuration,
self.validate_resource_allocation,
self.validate_monitoring_setup,
self.validate_backup_strategy,
self.validate_compliance_requirements,
self.validate_disaster_recovery,
self.validate_performance_requirements,
self.validate_integration_points
]
def validate_deployment(self, project, deployment_config):
"""Run comprehensive deployment validation"""
validation_results = {
"overall_status": "PASSED",
"checks": {},
"recommendations": [],
"critical_issues": []
}
for check in self.validation_checks:
try:
result = check(project, deployment_config)
validation_results["checks"][check.__name__] = result
if result["status"] == "FAILED":
validation_results["overall_status"] = "FAILED"
validation_results["critical_issues"].extend(result.get("issues", []))
validation_results["recommendations"].extend(result.get("recommendations", []))
except Exception as e:
validation_results["checks"][check.__name__] = {
"status": "ERROR",
"error": str(e)
}
validation_results["overall_status"] = "FAILED"
return validation_results
def validate_security_configuration(self, project, config):
"""Validate security configuration"""
issues = []
recommendations = []
# Check RBAC configuration
if not config.get("rbac_enabled"):
issues.append("RBAC not enabled")
# Check security contexts
for function in project.functions:
if not hasattr(function.spec, 'security_context'):
issues.append(f"Security context not configured for {function.metadata.name}")
# Check secrets management
if not project.secrets:
recommendations.append("Consider using Kubernetes secrets for sensitive data")
# Check network policies
if not config.get("network_policies_enabled"):
recommendations.append("Enable network policies for enhanced security")
return {
"status": "FAILED" if issues else "PASSED",
"issues": issues,
"recommendations": recommendations
}
def validate_resource_allocation(self, project, config):
"""Validate resource allocation and limits"""
issues = []
recommendations = []
for function in project.functions:
# Check resource limits
if not function.spec.resources.get("limits"):
issues.append(f"No resource limits set for {function.metadata.name}")
# Check requests
if not function.spec.resources.get("requests"):
recommendations.append(f"Consider setting resource requests for {function}")
# Check auto-scaling configuration
if function.kind == "serving" and not hasattr(function.spec, 'min_replicas'):
recommendations.append(f"Configure auto-scaling for serving function {function}")
return {
"status": "FAILED" if issues else "PASSED",
"issues": issues,
"recommendations": recommendations
}
def validate_monitoring_setup(self, project, config):
"""Validate monitoring and observability setup"""
issues = []
recommendations = []
# Check if monitoring is enabled
if not config.get("monitoring_enabled"):
issues.append("Model monitoring not enabled")
# Check alert configuration
if not project.get_alerts():
recommendations.append("Configure alerts for production monitoring")
# Check logging configuration
if not config.get("structured_logging"):
recommendations.append("Enable structured logging for better observability")
return {
"status": "FAILED" if issues else "PASSED",
"issues": issues,
"recommendations": recommendations
}
# Use the validator before production deployment
validator = EnterpriseDeploymentValidator()
validation_result = validator.validate_deployment(project, {
"rbac_enabled": True,
"network_policies_enabled": True,
"monitoring_enabled": True,
"structured_logging": True
})
if validation_result["overall_status"] == "FAILED":
print("❌ Deployment validation failed:")
for issue in validation_result["critical_issues"]:
print(f - {issue})
else:
print("✅ Deployment validation passed")
# MLRunTroubleshooter class for deployment diagnostics
class MLRunTroubleshooter:
"""Comprehensive troubleshooting for MLRun deployments"""
def __init__(self):
self.diagnostic_checks = {
"function_build_failures": self.diagnose_build_issues,
"memory_issues": self.diagnose_memory_problems,
"performance_degradation": self.diagnose_performance_issues,
"feature_store_latency": self.diagnose_feature_store_issues,
"model_serving_errors": self.diagnose_serving_issues
}
def run_diagnostics(self, project):
"""Run comprehensive diagnostics on MLRun project"""
diagnostic_results = {}
for check_name, check_func in self.diagnostic_checks.items():
try:
result = check_func(project)
diagnostic_results[check_name] = result
except Exception as e:
diagnostic_results[check_name] = {
"status": "ERROR",
"message": f"Diagnostic check failed: {str(e)}"
}
return diagnostic_results
def diagnose_build_issues(self, project):
"""Diagnose function build failures"""
issues = []
solutions = []
for function in project.functions:
try:
# Check build logs
if function.status.build_pod:
build_logs = function.get_build_logs()
if "ERROR" in build_logs or "FAILED" in build_logs:
issues.append(f"Build failed for {function.metadata.name}")
# Common build issue patterns
if "requirements" in build_logs.lower():
solutions.append("Check requirements.txt format and package versions")
if "base image" in build_logs.lower():
solutions.append("Verify base image accessibility and compatibility")
if "memory" in build_logs.lower():
solutions.append("Increase build memory limits")
except Exception as e:
issues.append(f"Could not check build status for {function.metadata.name}")
return {
"status": "ISSUES_FOUND" if issues else "OK",
"issues": issues,
"solutions": solutions
}
def diagnose_memory_problems(self, project):
"""Diagnose memory-related issues"""
issues = []
solutions = []
for function in project.functions:
# Check resource utilization
metrics = self.get_function_metrics(function)
if metrics:
memory_usage = metrics.get("memory_usage_percent", 0)
if memory_usage > 90:
issues.append(f"High memory usage in {function.metadata.name}: {memor")
solutions.append(f"Increase memory limits for {function.name}")
# Check for OOM kills
if metrics.get("oom_kills", 0) > 0:
issues.append(f"OOM kills detected in {function.metadata.name}")
solutions.append("Optimize data processing or increase memory allocat")
return {
"status": "ISSUES_FOUND" if issues else "OK",
"issues": issues,
"solutions": solutions
}
def optimize_performance(self, project):
"""Apply performance optimizations"""
optimizations = []
for function in project.functions:
# CPU optimization
if function.kind == "job":
function.set_env("OMP_NUM_THREADS", "4")
function.set_env("MKL_NUM_THREADS", "4")
optimizations.append(f"Applied CPU threading optimization to {function.name}")
# Memory optimization
if function.kind == "serving":
function.spec.build.commands.append("pip install --no-cache-dir ...")
optimizations.append(f"Enabled no-cache pip installation for {function.name}")
# Storage optimization
function.with_annotation("storage.class", "gp3")
optimizations.append(f"Configured high-performance storage for {function.meta}")
return {
"optimizations_applied": len(optimizations),
"details": optimizations
}
# Run comprehensive troubleshooting
troubleshooter = MLRunTroubleshooter()
diagnostic_results = troubleshooter.run_diagnostics(project)
# Apply performance optimizations
optimization_results = troubleshooter.optimize_performance(project)
print("Diagnostic Results:", diagnostic_results)
print("Performance Optimizations:", optimization_results)
You've just explored the complete enterprise guide to MLRun – from basic concepts to advanced production deployment strategies. This comprehensive framework represents a fundamental shift in how organizations approach machine learning operations.
✅ Unified Integration: One platform handles the entire AI lifecycle without tool sprawl
✅ Enterprise Scalability: From prototype to petabyte-scale with automatic resource management
✅ Production Reliability: Battle-tested components with enterprise-grade monitoring and alerting
✅ Developer Experience: Write once, deploy anywhere with zero infrastructure complexity
✅ Compliance Ready: Built-in governance, audit trails, and regulatory compliance features
✅ Cost Optimization: Intelligent resource allocation and spot instance support
✅ Open Source Freedom: No vendor lock-in with community-driven development
The ML landscape continues evolving rapidly, but your MLOps foundation doesn't have to be in constant flux. With MLRun, you're building on a platform designed for both today's requirements and tomorrow's innovations.

{{AUTHOR}}
 Launch your Graphy
Launch your Graphy