There are no items in your cart
Add More
Add More
| Item Details | Price | ||
|---|---|---|---|

The world has witnessed an explosive surge in the capabilities of Large Language Models (LLMs) like ChatGPT, Stable Diffusion, and a myriad of others. These generative AI models are not just incremental improvements; they are fundamentally shifting the paradigm of AI application development. They are transforming how businesses interact with data, create content, and automate complex tasks, moving from niche, predictive AI applications to broad, conversational, and highly creative tools that can understand and generate human-like text, images, and even code. This revolution promises unprecedented opportunities for innovation and efficiency across virtually every industry.
However, the journey from a captivating LLM demonstration to a robust, scalable, and secure production system is often fraught with unique challenges. While building a proof-of-concept might be exciting and relatively straightforward, ensuring consistent performance, managing escalating inference costs, mitigating critical risks like hallucination (generating factually incorrect information) and inherent biases, and adapting to the relentless pace of model evolution presents a formidable operational hurdle. This is precisely where Large Language Model Operations, or LLMOps, steps in.
LLMOps is the specialized discipline dedicated to managing the entire lifecycle of applications powered by Large Language Models. This comprehensive approach encompasses critical stages, from the initial management of data and prompts to the intricate processes of model fine-tuning, rigorous evaluation, robust deployment, continuous monitoring, and ongoing maintenance. The core purpose of LLMOps is to transform experimental LLMs into scalable, production-ready AI tools that not only function reliably but also deliver sustained business value and a significant return on investment.
For those already familiar with Machine Learning Operations (MLOps), LLMOps can be conceptualized as its highly specialized, turbocharged cousin, meticulously engineered for the unique demands of the generative AI era. It builds upon the foundational principles of MLOps but introduces new capabilities and considerations that are specific to the nature of LLMs. The widespread acknowledgement of LLMOps as "crucial", "essential", and a "linchpin for successful generative AI deployments" underscores a fundamental understanding: it is not merely an optimization but a strategic necessity. Organizations must embrace LLMOps principles to confidently scale their AI initiatives, overcome deployment barriers related to compliance, performance, robustness, and reputational risk, and ultimately derive lasting business value from their generative AI investments. Without a robust LLMOps framework, the transformative potential of LLMs risks remaining confined to the experimental phase, unable to withstand the rigors of real-world application.
In this comprehensive guide, we will embark on a journey to master LLMOps. We will delve into its foundational concepts, explore the practical techniques that drive its success, dissect essential architectural patterns, and illuminate best practices. By the end of this exploration, readers will possess a clear roadmap to confidently build and manage robust, production-ready LLM applications.
To truly grasp LLMOps, it is helpful to first understand its predecessor and foundational discipline: Machine Learning Operations (MLOps). MLOps represents the set of best practices for managing the end-to-end lifecycle of traditional machine learning systems. Its core principles, modeled on the existing discipline of DevOps, revolve around fostering collaboration, automating workflows, ensuring reproducibility, and enabling continuous integration/continuous delivery (CI/CD) and monitoring for ML models. MLOps effectively integrates data scientists and ML engineers into a cohesive team, streamlining the journey from model development to deployment and maintenance.
However, the advent of Large Language Models introduces a new layer of complexity, presenting unique challenges that extend significantly beyond the capabilities of traditional MLOps. This necessitates the specialized focus of LLMOps.
Here are the key distinctions that highlight the evolution from MLOps to LLMOps:
The evolution from MLOps to LLMOps fundamentally represents a shift from a "model-centric" to an "application-centric" approach to AI operations. Traditional MLOps largely focuses on the lifecycle of a single machine learning model and its performance in isolation. However, LLMOps descriptions frequently refer to "LLM-powered applications," "chains," and "agents". The emphasis on prompt management, RAG integration, and orchestrating multi-step logic indicates that the operational focus has broadened significantly. It is no longer just about deploying a model artifact, but about effectively integrating, orchestrating, and managing the entire AI
The evolution from MLOps to LLMOps fundamentally represents a shift from a "model-centric" to an "application-centric" approach to AI operations. Traditional MLOps largely focuses on the lifecycle of a single machine learning model and its performance in isolation. However, LLMOps descriptions frequently refer to "LLM-powered applications," "chains," and "agents". The emphasis on prompt management, RAG integration, and orchestrating multi-step logic indicates that the operational focus has broadened significantly. It is no longer just about deploying a model artifact, but about effectively integrating, orchestrating, and managing the entire AI
This specialized landscape within AI operations can be visualized as nested layers: MLOps forms the foundational, outermost layer, encompassing general machine learning operations. GenAIOps (Generative AI Operations) is an extension of MLOps specifically designed for generative AI solutions, distinguished by its primary interaction with a foundation model. LLMOps is then a specific type of GenAIOps, narrowly focused on solutions built upon Large Language Models. Further specialization leads to RAGOps, a subclass of LLMOps, which deals specifically with the delivery and operation of Retrieval Augmented Generation systems, considered a key reference architecture. This nested structure clarifies the increasing specialization within the AI operational landscape.
To further illustrate these distinctions, the following table provides a side-by-side comparison:
Table 1: LLMOps vs. MLOps: A Side-by-Side Comparison
| Feature / Aspect |
Traditional MLOps |
LLMOps |
| Primary Focus | Developing and deploying machine learning models (e.g., classification, regression, prediction). | Specifically focused on Large Language Models (LLMs) and generative AI applications, emphasizing content creation and complex reasoning. |
| Model Adaptation | Often involves training models from scratch or applying transfer learning and retraining on smaller, task-specific datasets. | Centers on fine-tuning pre-trained foundation models with efficient methods (e.g., PEFT), prompt engineering, and Retrieval-Augmented Generation (RAG). |
| Model Evaluation | Relies on well-defined, quantitative performance metrics (e.g., accuracy, precision, recall, F1-score) on hold-out validation sets. | More complex and often subjective; requires human feedback, specialized metrics (e.g., coherence, relevance, safety), and techniques like LLM-as-a-judge. |
| Model Management | Teams typically manage their own models, including versioning of model artifacts and metadata. | Models are frequently externally hosted and accessed via APIs; management extends to prompt versioning, agent/chain definitions, and external knowledge bases. |
| Deployment | Models deployed through structured pipelines, often leveraging feature stores and containerization. | Models are often components within complex chains and agents, supported by specialized tools like vector databases and orchestration layers. |
| Monitoring | Focuses on data drift, model degradation, and traditional performance metrics. | Expands to include prompt-response efficacy, context relevance, hallucination detection, security against prompt injection threats, and inference cost tracking. |
| Computational Cost | Primarily incurred during data collection and intensive model training. | Significant cost associated with inference, especially for large models and long, complex prompts. |
| Data Handling | Involves processing structured and unstructured data, with a strong focus on feature engineering. | More complex data preparation for vast amounts of unstructured text, often requiring vector databases for embeddings and RAG. |
| Governance & Ethics |
Important for fairness and transparency, but LLMs' generative nature introduces higher complexities. |
Enhanced focus on ethics, compliance, and responsible AI due to increased model autonomy, potential for bias, and generation of harmful outputs. |
The LLMOps lifecycle is a structured, iterative approach that guides the development, deployment, monitoring, and ongoing maintenance of Large Language Models. This comprehensive process is crucial for ensuring that LLMs operate efficiently, consistently align with evolving business objectives, and can adapt dynamically to changing data landscapes and user needs. At its heart, the LLMOps lifecycle is a continuous feedback loop, where insights gleaned from real-world production usage inform and drive further development, refinement, and improvement.
The illustration below provides a high-level overview of the circular nature of the LLMOps lifecycle, showing the key stages and their iterative flow.
A critical aspect woven throughout the LLMOps lifecycle is the intricate interplay between human expertise and automated processes. While automation is key for efficiency, various stages necessitate significant human involvement. For instance, distributed training and automated benchmarks accelerate development and evaluation.[9] However, human feedback is indispensable for Reinforcement Learning with Human Feedback (RLHF), human-in-the-loop (HITL) evaluation for subjective quality assessment, and the nuanced art of prompt optimization and ethical oversight. This indicates that LLMOps is not a fully automated "lights-out" operation; human judgment, intuition, and domain expertise remain vital, particularly for subjective tasks, ensuring quality, and addressing complex ethical considerations. Effective LLMOps therefore requires not just robust technical infrastructure and automated pipelines but also well-defined human workflows and seamless collaboration. This means fostering strong partnerships between data scientists, ML engineers, product managers, domain experts, and even legal and ethical teams. The tools and platforms supporting LLMOps must be designed to facilitate this human-machine collaboration, enabling efficient feedback, review, and decision-making processes that are essential for successful LLM applications.
The absolute foundation for successful LLM deployment rests upon high-quality, diverse, and domain-specific data. This initial stage of data preparation is incredibly time-intensive, often accounting for a significant portion of an AI project's overall development time. The quality and relevance of the input data directly dictate the quality, reliability, and ethical behavior of your LLM's outputs.
The key steps and inherent challenges in this foundational phase include:
The data preparation phase for LLMs represents a fundamental shift from traditional machine learning, moving from a focus on feature engineering to one of contextual data curation. In classical MLOps, data preparation often heavily involves feature engineering—the meticulous process of transforming raw data into explicit, numerical features that models can directly learn from. For LLMs, while some preprocessing (like cleaning and tokenization) is necessary, the emphasis fundamentally shifts. Large Language Models, especially powerful foundation models, inherently learn complex patterns and "features" directly from raw text. Therefore, the focus in LLMOps data preparation moves towards providing the LLM with the right context, domain-specific knowledge, and high-quality raw textual data. The quality, relevance, and semantic richness of the
unstructured textual data itself become paramount, rather than its transformation into engineered features. This means that data teams working with LLMs need to develop specialized expertise in large-scale text data collection, cleaning, semantic chunking, and managing unstructured data. This often involves new tooling and methodologies, such as the widespread adoption of vector databases for efficient storage and retrieval of text embeddings, which are central to providing contextual information to LLMs. This redefines the skillset required for data professionals in the LLM era.
The journey to building an LLM application typically begins not with training a model from scratch, but with selecting and adapting an existing foundation model. Training a Large Language Model from the ground up is an extraordinarily resource-intensive endeavor, often costing millions of dollars and demanding immense computational power and time. Consequently, only a handful of well-resourced organizations possess the capabilities to undertake such a monumental task. This reality means that the vast majority of LLM applications leverage powerful pre-trained "foundation models" as their starting point. These models, pre-trained on vast datasets, serve as a robust base that can be customized for specific needs.
A critical strategic choice arises when selecting a foundation model: opting for a proprietary (closed-source) model or an open-source alternative. Each path presents distinct trade-offs:
Once a foundation model is selected, the next crucial decision in the LLMOps lifecycle is how to adapt it for your specific business use case. This typically involves either sophisticated prompt engineering, targeted fine-tuning, or, most commonly, a strategic combination of both approaches. This decision profoundly impacts development velocity, performance characteristics, and the overall cost profile of the LLM application.
The widespread availability and accessibility of powerful pre-trained foundation models, both through commercial APIs and open-source releases, fundamentally lower the barrier to entry for developing sophisticated AI applications. Historically, only well-funded research labs with immense computational resources could build such models. Now, teams no longer need to train massive models from scratch, allowing them to redirect their focus and resources towards application-specific adaptation. This phenomenon mirrors how cloud computing democratized infrastructure, making advanced capabilities accessible to a broader audience. This shift empowers a significantly broader range of developers, startups, and enterprises to build and deploy AI solutions, fostering unprecedented innovation. However, it also creates a new demand for specialized expertise: the ability to effectively
adapt these foundation models. This means deep proficiency in prompt engineering, efficient fine-tuning techniques, and integrating LLMs into complex systems becomes the new critical skill set, rather than core model architecture design. The competitive edge shifts from who can build the biggest model to who can most effectively adapt and operationalize existing models for specific value.
Prompt engineering is often described as both an art and a science: it is the meticulous process of carefully designing the input text, known as the "prompt," that you provide to a Large Language Model to elicit a specific, desired output. The quality, clarity, and structure of your prompt are paramount, as they directly and heavily influence the quality, relevance, and safety of the LLM's response. It is a critical skill for customizing LLMs to meet the precise requirements of a specific use case, acting as a direct interface to guide the model's behavior.
A well-crafted prompt can incorporate one or more of the following key elements to guide the LLM effectively:
As LLM applications grow in complexity and scale, managing prompts becomes a significant operational challenge. This necessitates robust prompt management practices, which involve systematically creating, storing, comparing, optimizing, and versioning prompts. It also includes analyzing inputs and outputs, and meticulously managing test cases throughout the prompt engineering process. Tools and frameworks like LangChain or HoneyHive are invaluable for managing and versioning prompt templates, ensuring reproducibility, facilitating collaboration among teams, and tracking changes over time.
The following code snippet demonstrates a basic LangChain Prompt Template, illustrating how prompts can be made dynamic and reusable. This is a fundamental concept in LLMOps for managing variations in prompts across different use cases or iterations, promoting consistency and efficiency. For intermediate learners, seeing a simple, runnable code example helps solidify the abstract concept of prompt engineering and prompt templates. LangChain is a widely adopted and powerful framework for building LLM applications, making this example highly practical and relevant. It visually demonstrates how to parameterize prompts, which is key for building flexible and scalable LLM applications that can handle varied inputs without rewriting the entire prompt each time.
# Placeholder for LangChain Prompt Template Code Snippet
# This snippet demonstrates creating a reusable prompt template
# for a simple restaurant name generator, taking cuisine and country as variables.
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain.prompts import PromptTemplate
import os
# --- Setup (Uncomment and replace with your actual API key to run) ---
# os.environ = "YOUR_GOOGLE_API_KEY"
# llm = ChatGoogleGenerativeAI(model="gemini-pro")
# --- End Setup ---
print("--- LangChain Prompt Template Example ---")
# Define the prompt template with placeholders for dynamic input
# The.from_template() method is a convenient way to create a template string.
prompt_template = PromptTemplate.from_template(
"Suggest one creative and unique name for a restaurant in {country} that serves {cuisine} food."
)
# Example Usage 1: Indian restaurant in England
country1 = "England"
cuisine1 = "Indian"
prompt_for_indian_uk = prompt_template.format(country=country1, cuisine=cuisine1)
print(f"\nGenerated Prompt 1: {prompt_for_indian_uk}")
# if 'llm' in locals(): # Only invoke if LLM is initialized
# result1 = llm.invoke(prompt_for_indian_uk)
# print(f"LLM Response 1: {result1.content}")
# else:
# print("LLM not initialized. Please uncomment and set your API key to get a live response.")
print("Expected LLM Response 1 (example): 'The Spice Route' or 'Curry Corner'")
# Example Usage 2: Mexican restaurant in the USA
country2 = "USA"
cuisine2 = "Mexican"
prompt_for_mexican_usa = prompt_template.format(country=country2, cuisine=cuisine2)
print(f"\nGenerated Prompt 2: {prompt_for_mexican_usa}")
# if 'llm' in locals(): # Only invoke if LLM is initialized
# result2 = llm.invoke(prompt_for_mexican_usa)
# print(f"LLM Response 2: {result2.content}")
# else:
# print("LLM not initialized. Please uncomment and set your API key to get a live response.")
print("Expected LLM Response 2 (example): 'El Fuego Cantina' or 'Taco Time'")
# This demonstrates how the same template can be reused for different inputs,
# which is crucial for scalable LLM application development.
The process of prompt engineering is not a static, one-time activity; it is a continuous optimization loop and represents a new form of "code." The description of prompt engineering involving "creating, storing, comparing, optimizing, and versioning prompts" clearly indicates an iterative, experimental process. This is akin to A/B testing or hyperparameter tuning in traditional machine learning, where the goal is the continuous improvement of response quality, which directly impacts user experience and application effectiveness. Furthermore, the use of "prompt templates" and "version control" elevates prompts from mere text inputs to a form of "configuration as code" or even "logic as text." This means that LLMOps must provide robust tools and workflows for managing prompts throughout their lifecycle. This includes dedicated prompt experimentation platforms, version control systems specifically designed for prompts, and performance tracking mechanisms to compare different prompt versions, analyze their outputs, and quickly iterate based on feedback. Treating prompts as a critical asset, subject to rigorous engineering practices, is essential for maintaining and improving LLM application performance and reliability in production.
While prompt engineering offers a powerful and flexible way to guide Large Language Models, there are specific scenarios where fine-tuning a pre-trained LLM becomes not just beneficial, but necessary. Fine-tuning involves further training a foundation model on a smaller, task-specific dataset, allowing it to specialize and adapt its knowledge and behavior for particular use cases.Key reasons and scenarios for fine-tuning include:
Historically, fine-tuning involved "full fine-tuning," where the entire model is trained on new, task-specific data. While effective, this approach is computationally intensive, requires significant memory, and can be very expensive, especially for the massive parameters of modern LLMs. This led to the development of more efficient techniques:
Another critical aspect of the fine-tuning process, particularly for aligning AI responses with human preferences, business guidelines, and ethical standards, is Reinforcement Learning with Human Feedback (RLHF). This step helps imbue the model with desired behaviors and values, moving beyond purely statistical accuracy to incorporate human judgment on quality, helpfulness, and safety.
Key hyperparameters, such as learning rate (determining the step size towards optimal weights), batch size (the number of training samples processed in one pass), and the number of epochs (how many times the entire dataset passes through the model), are also critical for optimizing the fine-tuning process. Selecting the right values for these parameters is crucial for achieving optimal performance and efficiency.
The following code snippet provides a simplified illustration of the initial, fundamental steps involved in setting up an LLM fine-tuning process, specifically loading a dataset and tokenizer. These steps are common to nearly all fine-tuning workflows, offering a concrete starting point for intermediate learners. For intermediate learners, this snippet provides a tangible, runnable example that helps demystify the technical aspects of fine-tuning. It leverages the Hugging Face datasets and transformers libraries, which are industry standards for LLM development, making the example highly practical and relevant. It clearly demonstrates the critical role of data preparation (tokenization) in transforming raw text into a format consumable by the LLM for training. This hands-on exposure helps bridge theoretical understanding with practical implementation.
# Placeholder for Simplified LLM Fine-tuning Setup Code Snippet
# This snippet shows how to load a dataset and tokenizer using Hugging Face libraries,
# which are foundational steps for preparing data for fine-tuning.
from datasets import load_dataset
from transformers import AutoTokenizer, AutoModelForSequenceClassification # Using Auto classes for flexibility
import pandas as pd
print("--- Simplified LLM Fine-tuning Setup Example ---")
# Step 1: Choose a pre-trained model and a dataset
# For demonstration purposes, we'll use a common smaller model and a public dataset.
# In a real LLMOps scenario, you would select a specific LLM (e.g., Llama-2, GPT-2)
# and a high-quality, domain-specific dataset tailored for your fine-tuning task.
model_checkpoint = "distilbert-base-uncased" # A smaller, efficient model for illustration
dataset_to_load = "imdb" # A popular sentiment analysis dataset
# Step 2: Load the dataset
try:
# Load the full dataset
dataset = load_dataset(dataset_to_load)
print(f"Successfully loaded dataset: '{dataset_to_load}'.")
# For practical fine-tuning, especially with LLMs, you often work with subsets.
# Let's create a small training subset for demonstration.
small_train_dataset = dataset["train"].shuffle(seed=42).select(range(1000))
print(f"Created a training subset with {len(small_train_dataset)} examples.")
print(f"Example data point from subset: {small_train_dataset}")
except Exception as e:
print(f"Error loading dataset '{dataset_to_load}': {e}")
print("Please ensure you have the 'datasets' library installed (`pip install datasets`).")
small_train_dataset = None # Set to None if loading fails to prevent further errors
# Step 3: Load the tokenizer and prepare the dataset for the model
if small_train_dataset:
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
# For GPT-2, you might need: tokenizer.pad_token = tokenizer.eos_token
# Define a tokenization function to apply to the dataset
def tokenize_function(examples):
# Ensure the key 'text' exists in your dataset examples for text content
return tokenizer(examples["text"], padding="max_length", truncation=True, max_length=128)
# Apply the tokenization function across the entire dataset using map
tokenized_datasets = small_train_dataset.map(tokenize_function, batched=True)
print(f"\nDataset tokenized successfully.")
print(f"Example tokenized input_ids (first 20 tokens): {tokenized_datasets['input_ids'][:20]}...")
print(f"Example tokenized attention_mask (first 20 tokens): {tokenized_datasets['attention_mask'][:20]}...")
# At this point, `tokenized_datasets` is ready for use with a Hugging Face Trainer
# or custom PyTorch/TensorFlow training loops.
# For actual training, you would then initialize your model and a Trainer object.
else:
print("\nSkipping tokenization as dataset loading failed.")
# Expected output structure (actual output may vary based on model/dataset):
# --- Simplified LLM Fine-tuning Setup Example ---
# Successfully loaded dataset: 'imdb'.
# Created a training subset with 1000 examples.
# Example data point from subset: {'text': 'This is a great movie!', 'label': 1}
# Dataset tokenized successfully.
# Example tokenized input_ids (first 20 tokens): ...
# Example tokenized attention_mask (first 20 tokens): ...
The emphasis on efficient fine-tuning techniques like PEFT (LoRA, QLoRA) highlights a crucial economic imperative within LLMOps. Fine-tuning LLMs, especially full fine-tuning, is explicitly stated as computationally expensive and time-consuming. However, the research highlights techniques like PEFT for their ability to "drastically reduce computational costs and memory requirements" and "reduce cost and computation during model updates". This directly addresses the "cost" consideration that differentiates LLMOps from traditional MLOps, where inference cost is a major concern. The focus on efficiency is not just a technical optimization but a fundamental financial strategy. For enterprises looking to deploy multiple specialized LLMs or iterate frequently on their models, adopting efficient fine-tuning techniques like PEFT is not merely a technical best practice but a critical financial optimization strategy. It enables sustainable scaling of LLM initiatives, significantly improving the return on investment (ROI) by making customization more accessible and affordable. This means LLMOps professionals must be well-versed in these techniques to make informed decisions that balance performance with cost-efficiency.
Evaluating Large Language Models presents a significantly more complex and nuanced challenge compared to assessing traditional machine learning models. This complexity stems from several inherent factors: the subjective nature of human language, the often non-deterministic outputs of generative models, and the inherent difficulty in defining a single, objective "correct" answer for creative, conversational, or open-ended tasks. Consequently, human feedback becomes an indispensable component for a comprehensive and reliable assessment.
LLMOps employs a hybrid approach, combining automated and human-in-the-loop (HITL) evaluation methods:
It is imperative to understand that evaluation is not a one-time step but an ongoing, continuous process within the LLMOps lifecycle. User interactions and real-world performance data must feed back into continuous improvement loops, allowing models to evolve and adapt over time.
The following table provides a structured overview of the diverse approaches and metrics used to evaluate LLMs, helping intermediate learners understand the nuances beyond traditional ML metrics. This table highlights the specific challenges of LLM evaluation and the tailored solutions. Traditional ML metrics (accuracy, precision, recall) are often insufficient for LLMs. This table introduces metrics and methods that address the unique aspects of generative models, such as semantic similarity, hallucination, and contextual relevance. It also distinguishes between reference-based (where a ground truth exists) and reference-free methods (for subjective quality), providing a comprehensive toolkit for evaluation.
Table 2: Essential LLM Evaluation Metrics & Methods
| Category |
Method/Metric | Description | Example Use Case |
| Reference-Based | Exact Match/Fuzzy Match | Compares LLM output to a known ground truth answer for precise or near-precise matches. | Fact-checking, code generation on(unit test pass rate), structured data extraction (JASON match). |
| Word/Item Overlap (BLEU, ROUGE) | Measures the overlap of words or n-grams between generated text and reference text. | Summarization, machine translation, text generation where a reference exists. | |
| Semantic Similarity (BERTScore, COMET, Cosine Similarity) | Compares token-level or sentence-level embeddings to assess semantic closeness to reference. | Assessing paraphrase quality, response relevance where exact wording varies. | |
| Reference-Free | LLM-as-a-Judge | Uses another LLM to evaluate the output based on natural language rubrics and criteria. | Subjective quality assessment (coherence, fluency, helpfulness), complex task completion. |
| Text Statistics | Measures characteristics like word count, readability scores (Flesch-Kincaid), non-letter character count. | Ensuring output meets length requirements, assessing text complexity. | |
| Programmatic Validation | Uses code (e.g., regex, schema validation) to check output format or content. | Validating JSON/SQL output syntax, ensuring required fields are present, testing code execution. | |
| Task-Specific | Answer Relevancy | Assesses if the LLM output directly addresses the input in a concise, informative manner, often considering retrieval context | RAG applications, chatbots. |
| Contextual Precision/Recall | For RAG, measures the relevancy of retrieved context and how much of the expected output is attributable to it. | Optimizing RAG retriever performance. | |
| Task Completion | Determines if an LLM agent successfully completes a multi-step task. | Agentic AI systems, complex workflow automation. | |
| Hallucination Detection | Identifies instances where the LLM generates factually incorrect or unsupported information. | Critical for factual applications (e.g., legal, medical, financial). | |
| Perplexity | Measures how well an LLM predicts a sample of text; lower is better. | General language model quality, though less direct for application-specific evaluation. |
The evolving definition of "success" for LLMs is a critical aspect of LLMOps. Unlike traditional machine learning where success is often tied to clear, quantifiable metrics (e.g., 95% accuracy on a classification task), LLM success is multifaceted. It involves not just factual correctness but also subjective qualities like coherence, fluency, helpfulness, and safety. This necessitates a blend of automated and human evaluation, indicating that the "ground truth" for LLMs is often more nuanced and human-defined. Consequently, LLMOps teams must move beyond simple quantitative metrics and embrace qualitative assessment, A/B testing, and continuous human feedback loops. This also means setting clear, multi-dimensional success criteria that align with both business objectives and ethical goals, acknowledging the complex nature of language generation.
Once an LLM has been prepared, adapted, and rigorously evaluated, the next crucial phase in the LLMOps lifecycle is its deployment into a production environment and subsequent continuous monitoring. This ensures that the LLM application remains healthy, performs as expected, and delivers consistent value to end-users.
The criticality of real-time observability for non-deterministic systems is a defining characteristic of LLMOps. LLM outputs can "change drastically between releases" and are inherently non-deterministic, meaning the same input might yield slightly different outputs. This makes continuous, real-time monitoring of prompt-response efficacy, hallucination, and security threats far more critical than for traditional, more predictable ML models. Issues like prompt injection (malicious prompts designed to bypass safety features) or unexpected, undesirable outputs need immediate detection and mitigation to prevent reputational damage or security breaches. Consequently, LLMOps requires advanced monitoring solutions that go beyond traditional metrics, focusing intently on the quality and safety of generated text in real-time. This necessitates specialized tools and the ability to quickly debug and roll back problematic deployments, ensuring the application remains stable and trustworthy.
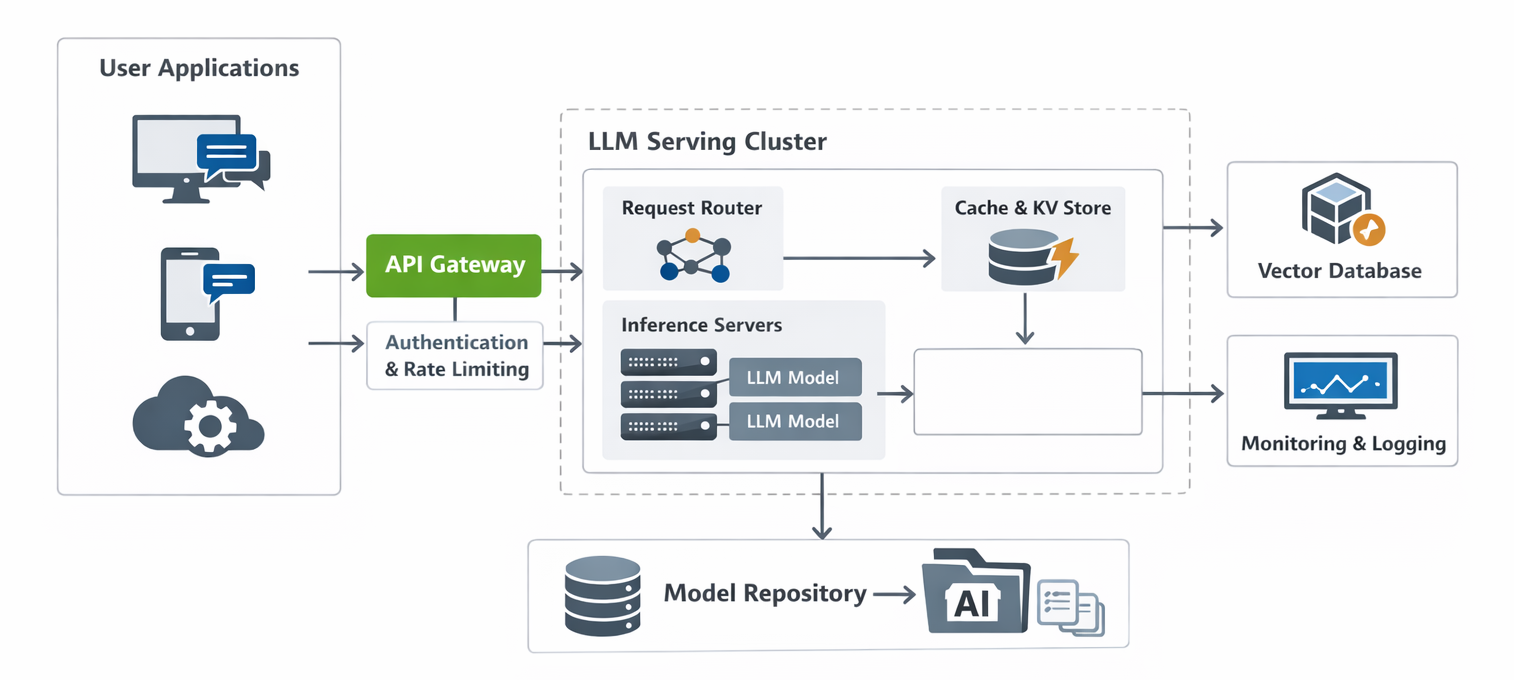
The following diagram illustrates a high-level LLM deployment architecture
A robust LLMOps architecture is not a one-size-fits-all solution; it is a meticulously designed system that ties together several core layers, each serving a critical function. These architectural patterns help organizations balance performance, cost, governance, and development velocity, enabling them to operationalize LLMs effectively.
Retrieval Augmented Generation (RAG) has emerged as a pivotal architectural pattern in LLMOps, serving as a powerful "grounding" solution for Large Language Models. Its primary purpose is to enhance general-purpose LLMs by incorporating relevant information from proprietary, domain-specific, or up-to-date external datasets during query time. This approach helps LLMs overcome a significant limitation: their reliance solely on static, pre-trained data. By injecting real-time, external knowledge, RAG effectively prevents hallucinations (the generation of factually incorrect information) and ensures that responses are factually correct, highly relevant, and context-specific.
The RAG process typically consists of two main conceptual steps, which are orchestrated through a sophisticated pipeline:
The following diagram illustrates a clear RAG pipeline architecture:
RAG serves as a vital bridge between general intelligence and domain specificity. Foundation models are "general-purpose" and pre-trained on vast public data, giving them broad knowledge. However, enterprises typically need models grounded in their specific, often proprietary, and constantly evolving internal data. RAG elegantly solves this by providing "grounding data" at inference time, without requiring expensive and time-consuming retraining of the entire LLM. This makes LLMs immediately useful and factually accurate for enterprise-specific applications, as they can pull the most current and relevant information. This means RAG is not just an architectural pattern; it is a strategic enabler for enterprise AI, allowing companies to leverage powerful public LLMs while maintaining data privacy, factual accuracy, and domain relevance. It significantly reduces the need for extensive fine-tuning solely for knowledge integration, offering a more agile and cost-effective path to specialized LLM applications.
As Large Language Models gain increased autonomy and are deployed in real-world scenarios, the imperative of responsible AI becomes paramount. Due to their generative nature and potential for producing harmful, biased, or factually incorrect outputs, enhanced governance, ethical considerations, and stringent compliance measures are non-negotiable. LLMOps acts as a "linchpin" for delivering these crucial governance mechanisms throughout the entire LLM lifecycle.
"Guardrails" are a critical component in this responsible AI framework, designed to ensure the safety, accuracy, and ethical alignment of LLM applications. Their functions include:
The emphasis on "risk mitigation", "security and compliance", "ethical oversight", and protecting against "reputational risk" highlights that LLMOps is fundamentally a comprehensive risk management framework. Given the potential for LLMs to generate misinformation, biased content, or respond to adversarial prompts, robust operational practices are essential to protect the organization, its users, and its brand reputation. Investing in LLMOps is not just about technical efficiency but about building trust, ensuring regulatory adherence, and safeguarding brand reputation. This necessitates close collaboration between technical teams, legal departments, and compliance officers, integrating ethical and legal considerations into every stage of the LLM lifecycle.
Beyond individual prompts, LLMOps extends to managing complex, multi-step LLM applications, often referred to as "agents" or "chains." This requires sophisticated prompt and agent management capabilities.
The concept of "agent/chain management" and "multi-agent coordination" signifies the emergence of "AI Agents" as a new paradigm in LLM applications. This goes beyond simple prompt-response interactions, describing LLMs acting as intelligent agents that can perform multi-step tasks, interact with external tools and APIs, and maintain state over time. This represents a significant move towards more autonomous and complex AI systems that can reason, plan, and execute. Consequently, LLMOps will increasingly need to manage the entire lifecycle of these complex agentic systems, including their planning, execution, and interaction with the real world. This adds new layers of complexity to monitoring, evaluation, and security, as the system's behavior becomes more dynamic and less predictable.
The sheer scale and computational demands of Large Language Models make robust infrastructure and meticulous resource management an absolutely critical component of LLMOps.
The explicit mention of "FinOps" and the consistent focus on "cost" as a key differentiator from traditional MLOps highlight that LLMOps is not purely a technical concern. It underscores the intertwined nature of technical operations and financial strategy. The high inference costs associated with LLMs, especially for long prompts or large models, directly impact an organization's bottom line. This necessitates a close integration of technical operational decisions with financial planning and ROI analysis. Consequently, LLMOps professionals need to be not just technically proficient but also commercially aware, making decisions that balance performance with cost-efficiency. This includes strategic choices about model size, whether to opt for prompt engineering versus fine-tuning, and how to provision and manage infrastructure optimally.
Implementing a robust LLMOps strategy is not merely a technical exercise; it is a strategic investment that unlocks significant business advantages, transforming the potential of generative AI into tangible, sustainable value. The collective benefits of a well-executed LLMOps framework position it as more than just good practice; it is a strategic differentiator. In a rapidly evolving AI landscape, organizations that can quickly and safely deploy, iterate, and scale LLM applications will gain a significant competitive edge.
Here are the key benefits of adopting a comprehensive LLMOps strategy:
These collective advantages demonstrate that LLMOps is more than just a set of technical practices; it is a strategic enabler of competitive advantage. In a rapidly evolving AI landscape, organizations that can quickly and safely deploy, iterate, and scale LLM applications will gain a significant competitive edge. Businesses should therefore view LLMOps as a critical investment in their long-term AI strategy, rather than just a cost center. It is about building the organizational muscle to continuously leverage cutting-edge AI, ensuring that generative models translate into lasting business value.
The field of LLMOps is still in its nascent stages, a rapidly evolving landscape where new developments, tooling, and best practices are constantly emerging. This dynamic environment means that what is considered standard practice today may be superseded by more efficient or robust methods tomorrow. The very question of whether the term "LLMOps" will endure or merge back into a broader "MLOps" umbrella underscores this fluidity.
Several key trends are anticipated to shape the future of LLMOps:
The dynamic nature of the "Ops" discipline, particularly in the context of LLMs, means that the field is not static; best practices and tools will continue to change at a rapid pace. This fluidity underscores the need for continuous learning and adaptability among practitioners. Staying informed about the latest research, emerging tools, and community developments will be crucial for success in this fast-moving domain. The future of LLMOps promises to be as exciting and transformative as the LLMs themselves.
Large Language Models are undeniably reshaping the technological landscape, offering unprecedented capabilities for innovation and efficiency. However, the true potential of these groundbreaking models can only be fully realized when they are effectively operationalized. This is where LLMOps emerges as an indispensable discipline, serving as the critical bridge that transforms the promise of generative AI into tangible, reliable, and production-ready solutions. It is the framework that allows organizations to confidently scale their AI initiatives, ensuring that groundbreaking research translates into real-world business value.
Throughout this guide, we have explored the multifaceted world of LLMOps, delving into its unique challenges and the specialized solutions it offers. We have seen how LLMOps extends and differentiates itself from traditional MLOps, addressing the complexities of model adaptation, nuanced evaluation, and advanced monitoring specific to generative AI. Key takeaways for any intermediate learner embarking on this journey include:
The investment in a robust LLMOps strategy yields significant benefits, including faster time-to-market, enhanced innovation, comprehensive risk mitigation, streamlined collaboration, and sustainable scaling. These advantages collectively position LLMOps as a strategic enabler of competitive advantage in the rapidly evolving AI landscape.
Your journey to LLM mastery begins now. Ready to build your first production-ready LLM application? Consider exploring popular LLMOps frameworks like LangChain, which provides powerful tools for prompt management and agent orchestration. Experiment with cloud platforms such as Amazon SageMaker, which offers services for scalable LLM evaluation and deployment. Dive deeper into specific areas that resonate with your projects, whether it's mastering prompt engineering best practices or optimizing RAG pipeline performance. Most importantly, engage with the vibrant LLMOps community to share insights, learn from the experiences of others, and stay abreast of the latest advancements. For those seeking comprehensive solutions to streamline their LLM development and deployment, exploring enterprise-grade platforms designed for LLMOps can provide the integrated tools and support needed to accelerate your success. The future of AI is operational, and mastering LLMOps is your key to unlocking its full potential.

{{AUTHOR}}
 Launch your Graphy
Launch your Graphy