There are no items in your cart
Add More
Add More
| Item Details | Price | ||
|---|---|---|---|

Building reliable LLM applications is one of the biggest challenges developers face today. You've probably experienced the frustration – your model works beautifully in development, but once it hits production, you're dealing with mysterious failures, unexpected outputs, and users complaining about quality issues. That's where LangSmith comes in as your complete observability, evaluation, and monitoring platform specifically designed for LLM applications.
If you've been struggling with debugging complex AI workflows, testing prompt variations, or monitoring your models in production, LangSmith is about to become your secret weapon. This comprehensive guide will take you through everything you need to know to master LangSmith and build bulletproof LLM applications.
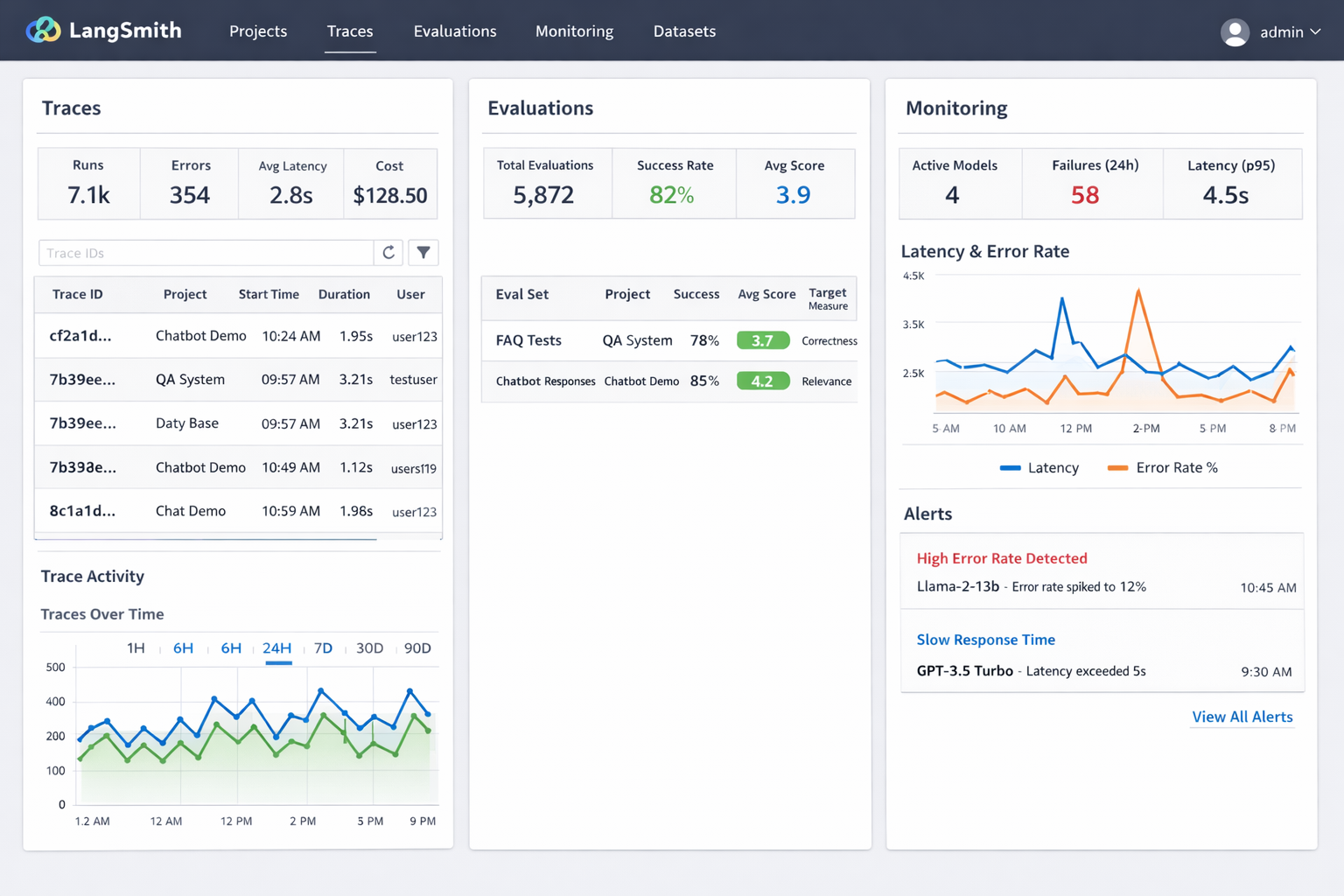
LangSmith dashboard overview showing traces, evaluations, and monitoring interface with real project data
LangSmith is a comprehensive platform for building production-grade LLM applications. Think of it as your mission control center for everything related to LLM observability, evaluation, and improvement. Whether you're using LangChain, LangGraph, or building completely custom AI applications, LangSmith gives you the tools to understand what's happening under the hood of your AI systems.
Here's what makes LangSmith fundamentally different from traditional monitoring tools: it's LLM-native. Traditional application monitoring tools weren't built for the unique challenges of language models – the non-deterministic nature, complex reasoning chains, multi-modal inputs and outputs, and the need to evaluate qualitative responses alongside quantitative metrics.
LangSmith covers six main areas that every production LLM application desperately needs:
The best part? LangSmith is framework-agnostic. You can use it with LangChain, LangGraph, raw OpenAI calls, Anthropic models, or any custom LLM application you've built. It doesn't lock you into any particular ecosystem.
Traditional application monitoring assumes deterministic behavior – if you send the same input, you get the same output. LLMs break this assumption completely. They're designed to be creative, contextual, and sometimes even contradictory. This creates unique challenges:
LangSmith was built from the ground up to handle these challenges
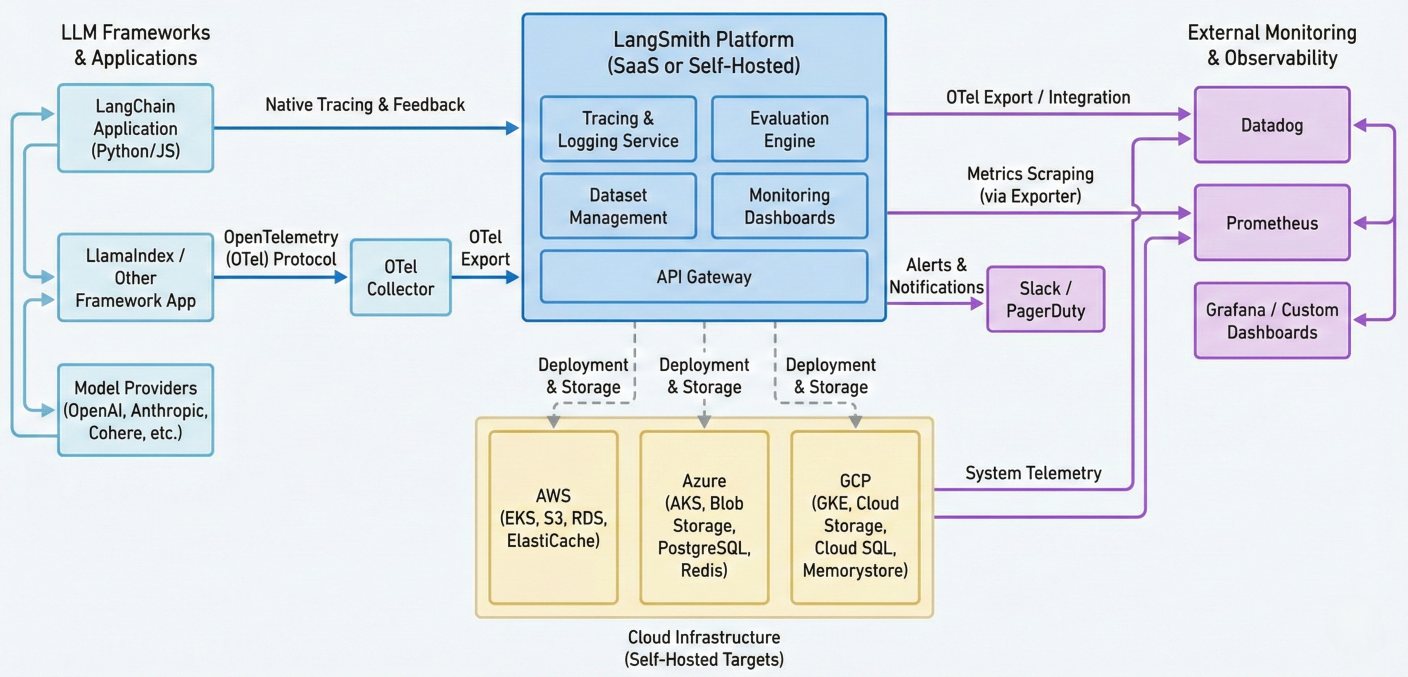
Architecture diagram showing LangSmith integration with different LLM frameworks, cloud providers, and monitoring systems
Let's get you up and running with LangSmith. The setup is straightforward, but there are several optimization strategies you'll want to implement from the start.
First, install the LangSmith SDK:
pip install -U langsmith
For JavaScript/TypeScript projects:
npm install langsmith
# or
yarn add langsmith
Next, you'll need to create an API key. Head to smith.langchain.com and navigate to your settings page. Create an API key – you'll see it only once, so store it securely in your password manager or secrets management system.
Now set up your environment variables:
export LANGSMITH_TRACING=true
export LANGSMITH_API_KEY="your-api-key-here"
export LANGSMITH_ENDPOINT="https://api.smith.langchain.com"
export LANGSMITH_PROJECT="your-project-name"
Pro tip: You can also configure these programmatically if environment variables aren't an option in your deployment environment:
from langsmith import Client, tracing_context
langsmith_client = Client(
api_key="YOUR_LANGSMITH_API_KEY",
api_url="https://api.smith.langchain.com"
)
# Use within a context manager for specific operations
with tracing_context(enabled=True):
# Your LLM calls here
response = llm.invoke("Hello, how are you?")
Let's start with something simple. If you're using LangChain, tracing happens automatically once you set the environment variables:
# LangChain OpenAI Example
import os
from langchain_openai import ChatOpenAI
# Environment variables already set
llm = ChatOpenAI(temperature=0.7, model="gpt-4")
response = llm.invoke("Hello, how are you?")
print(response.content)
That's it! Head to your LangSmith dashboard and you'll see the trace appear with complete details about the request and response.
For production deployments, you'll want to configure sampling and filtering:
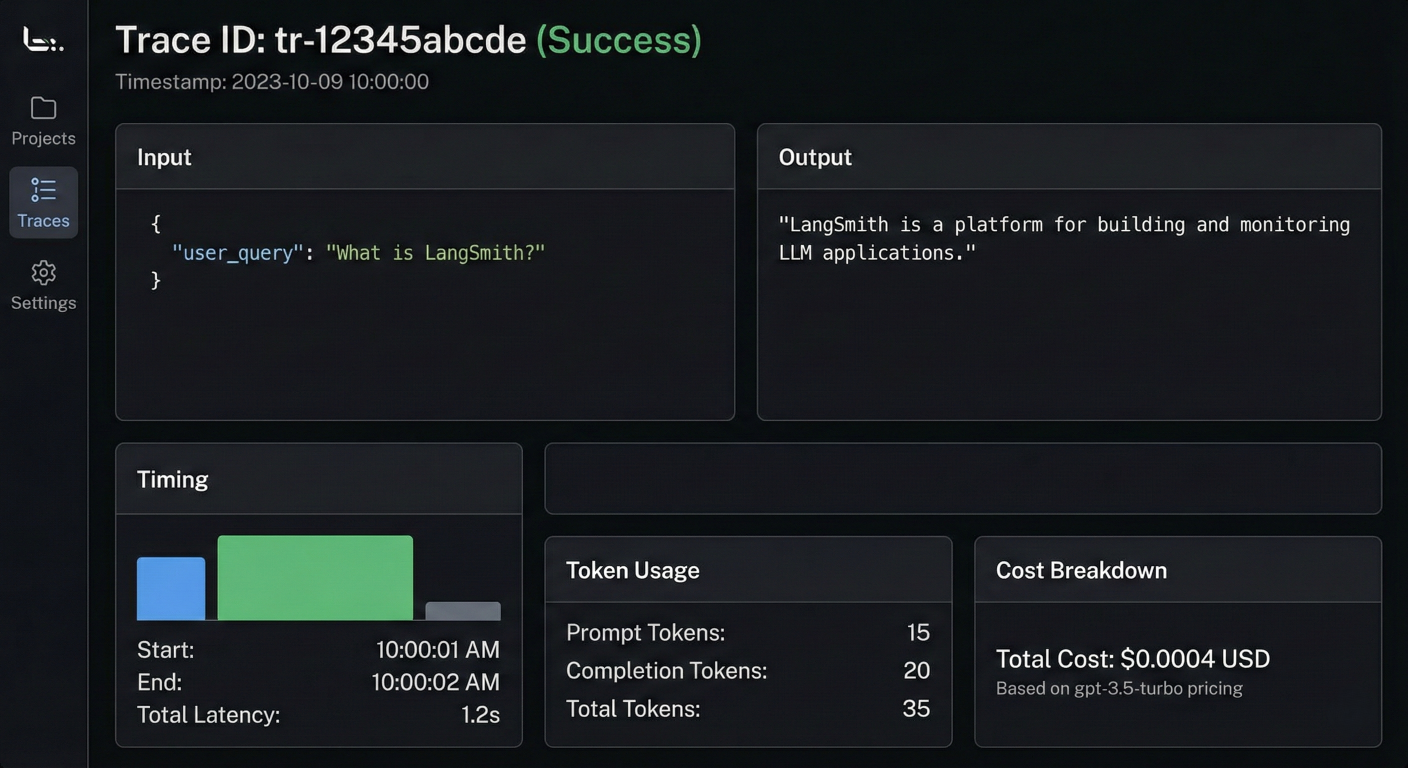
Screenshot of first LangSmith trace showing detailed input, output, timing, token usage, and cost breakdown
This is where LangSmith really shines compared to traditional debugging approaches. Trying to debug LLM applications with print statements or basic logging is like trying to perform surgery with a butter knife
Every interaction with your LLM application creates a trace – think of it as a complete execution record of what happened during a single user interaction. Within each trace, you have runs that represent individual steps like LLM calls, tool usage, retrieval operations, or chain execution.
Here's what you get with every trace:
If you're building sophisticated multi-agent systems, LangSmith's distributed tracing becomes invaluable:
from langsmith import traceable
import openai
client = openai.Client()
@traceable(name="Planning Agent", run_type="agent")
def planning_agent(task: str) -> dict:
"""Agent that creates execution plans"""
response = client.chat.completions.create(
model="gpt-4",
messages=[
{"role": "system", "content": "You are a planning agent. Create detailed exec"},
{"role": "user", "content": f"Create a plan for: {task}"}
]
)
plan = {"steps": response.choices.message.content.split("\n")}
return plan
@traceable(name="Research Agent", run_type="agent")
def research_agent(topic: str) -> str:
"""Agent that conducts research"""
# Simulate research operation
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a research agent. Provide detailed res"},
{"role": "user", "content": f"Research: {topic}"}
]
)
return response.choices.message.content
@traceable(name="Execution Agent", run_type="agent")
def execution_agent(plan: dict) -> list:
"""Agent that executes plans"""
results = []
for step in plan["steps"][:3]: # Execute first 3 steps
if "research" in step.lower():
result = research_agent(step)
else:
result = f"Executed: {step}"
results.append(result)
return results
@traceable(name="Multi-Agent Workflow", run_type="workflow")
def multi_agent_system(user_task: str) -> dict:
"""Orchestrator for multi-agent workflow"""
plan = planning_agent(user_task)
results = execution_agent(plan)
return {
"task": user_task,
"plan": plan,
"results": results,
"status": "completed"
}
# Execute the workflow
result = multi_agent_system("Create a comprehensive marketing strategy for a new AI product")
All agent interactions will be captured in a single hierarchical trace, making debugging and optimization much easier.
Not using LangChain? No problem. LangSmith works with any Python code using decorators and context managers:
import openai
from langsmith import traceable, Client
from langsmith.wrappers import wrap_openai
import json
# Wrap your OpenAI client for automatic tracing
client = wrap_openai(openai.Client())
langsmith_client = Client()
@traceable(run_type="retriever", name="Vector Search")
def retrieve_context(query: str, top_k: 5) -> list:
"""Simulate vector database retrieval"""
# Your vector search logic here
contexts = [
f"Context {i+1} for query: {query}"
for i in range(top_k)
]
return contexts
@traceable(run_type="tool", name="Web Search")
def web_search(query: str) -> dict:
"""Simulate web search tool"""
return {
"query": query,
"results": [
{"title": f"Result 1 for {query}", "url": "https://example.com/1"},
{"title": f"Result 2 for {query}", "url": "https://example.com/2"}
]
}
@traceable(name="RAG Response Generator", run_type="chain")
def generate_rag_response(query: str, use_web_search: bool = False) -> dict:
"""Generate response using RAG pattern"""
# Retrieve context
contexts = retrieve_context(query)
# Optional web search
web_data = None
if use_web_search:
web_data = web_search(query)
# Prepare system prompt
context_text = "\n".join(contexts)
system_prompt = f"""You are a helpful AI assistant. Use the following context to answ
Context:
{context_text}"""
if web_data:
system_prompt += f"\n\nWeb search results: {json.dumps(web_data)}"
# Generate response
response = client.chat.completions.create(
model="gpt-4",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": query}
],
temperature=0.7
)
return {
"query": query,
"context_count": len(contexts),
"used_web_search": use_web_search,
"response": response.choices.message.content,
"total_tokens": response.usage.total_tokens
}
# This will create a detailed nested trace
result = generate_rag_response(
"What are the best practices for LLM application monitoring?",
use_web_search=True
)
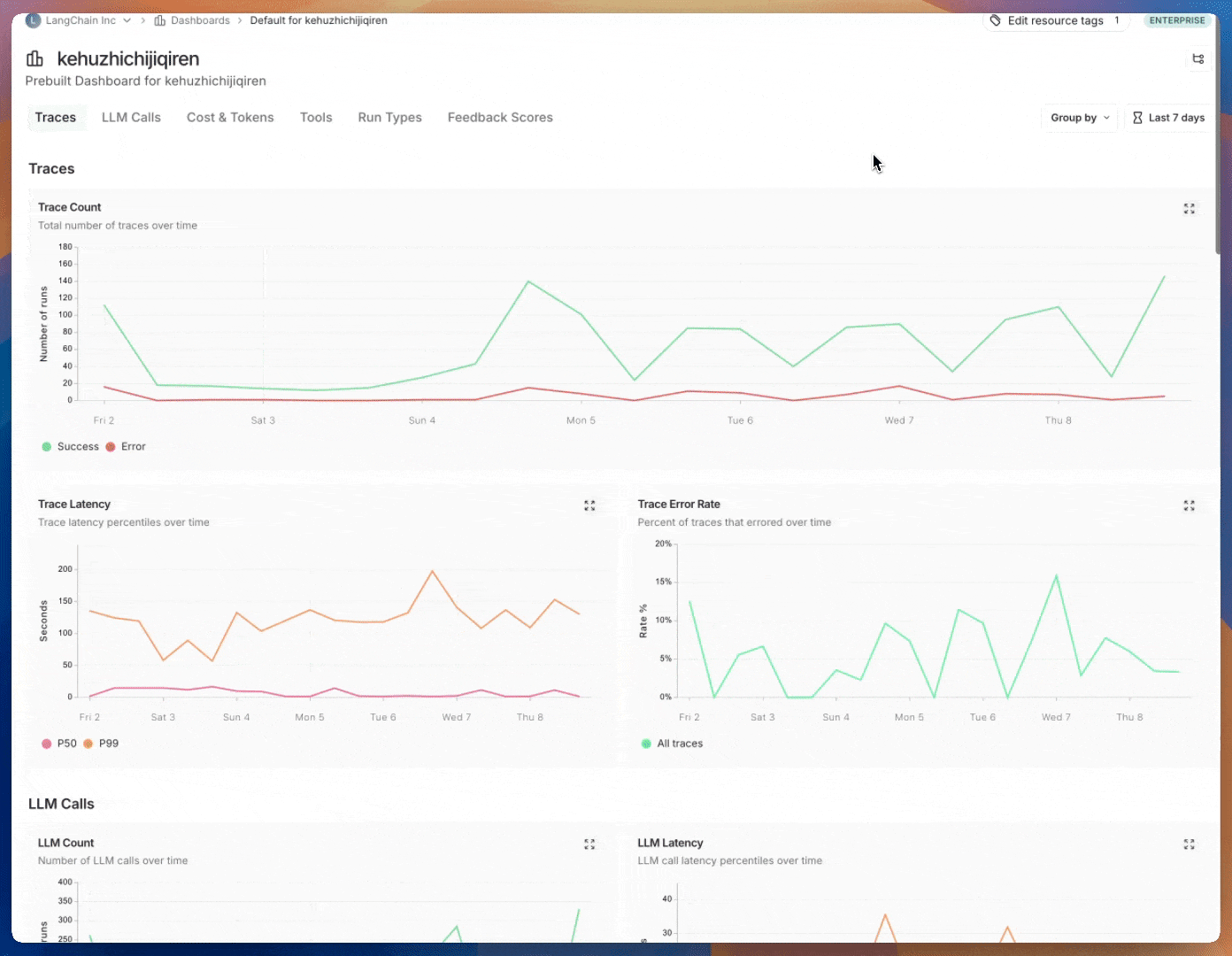
LangSmith automatically creates comprehensive dashboards for each project. You'll get insights into:
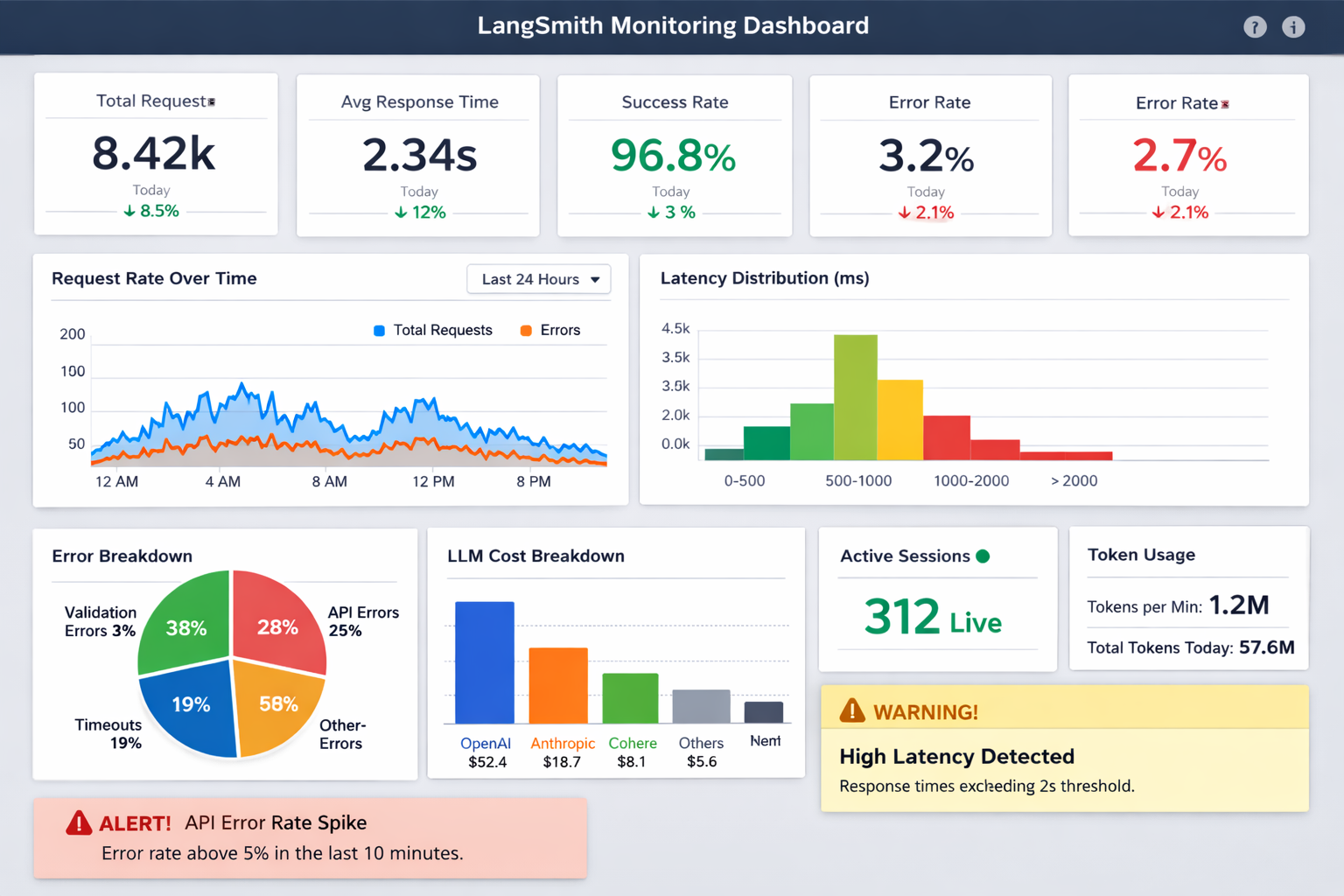
LangSmith monitoring dashboard showing comprehensive metrics, charts, and real-time performance indicators
You can also create custom dashboards to track metrics specific to your use case:
from langsmith import Client
client = Client()
# Query custom metrics programmatically
import pandas as pd
# Get cost breakdown by model
cost_data = client.list_runs(
project_name="your-project",
start_time="2024-01-01",
filter="and(eq(run_type, 'llm'), gte(start_time, '2024-01-01T00:00:00'))"
)
# Analyze patterns in your traces
df = pd.DataFrame([{
'model': run.extra.get('invocation_params', {}).get('model', 'unknown'),
'tokens': run.total_tokens,
'cost': run.total_cost,
'latency': (run.end_time - run.start_time).total_seconds() if run.end_time else None,
'error': run.error is not None
} for run in cost_data])
print(f"Total cost this month: ${df['cost'].sum():.2f}")
print(f"Average latency: {df['latency'].mean():.2f} seconds")
print(f"Error rate: {df['error'].mean():.2%}")
Traditional software testing doesn't work for LLM applications. You can't just assert that the output equals some expected string. LangSmith's evaluation framework addresses this with sophisticated approaches to testing AI applications.
LangSmith's evaluation system consists of three core components:
1. Datasets: Your test inputs and expected outputs with rich metadata
2. Target function: What you're evaluating (single LLM call, part of your app, or end-to-end system)
3. Evaluators: Functions that score your outputs using various criteria
Let's build a comprehensive evaluation setup:
from langsmith import Client
from langsmith.evaluation import evaluate
from openevals import Correctness, Helpfulness, Harmfulness
import openai
# Initialize clients
ls_client = Client()
openai_client = openai.Client()
def my_rag_application(inputs: dict) -> dict:
"""Your RAG application to evaluate"""
question = inputs["question"]
context = inputs.get("context", "")
response = openai_client.chat.completions.create(
model="gpt-4",
messages=[
{
"role": "system",
"content": f"Answer the question using the provided context. Context: {co"
},
{"role": "user", "content": question}
]
)
return {
"answer": response.choices.message.content,
"model": "gpt-4",
"context_used": bool(context)
}
# Run comprehensive evaluation
results = evaluate(
my_rag_application,
data="customer_support_dataset", # Your dataset name
evaluators=[
Correctness(), # Factual accuracy
Helpfulness(), # Response helpfulness
Harmfulness(), # Safety check
],
experiment_prefix="rag_v2_evaluation",
max_concurrency=5, # Parallel evaluation
metadata={
"model_version": "gpt-4",
"evaluation_date": "2024-08-21",
"evaluator": "production_team"
}
)
print(f"Evaluation completed: {results}")
While built-in evaluators are helpful, you'll often need custom evaluators for your specific domain:
# LangSmith custom evaluators example
from langsmith.schemas import Run, Example
import re
import json
def domain_expertise_evaluator(run: Run, example: Example) -> dict:
"""Custom evaluator that checks domain-specific expertise"""
prediction = run.outputs.get("answer", "")
question = example.inputs.get("question", "")
# Define domain-specific criteria
technical_terms = ["API", "authentication", "encryption", "database", "microservices"]
explanation_quality_markers = ["because", "therefore", "however", "for example"]
# Score technical accuracy
technical_score = sum(1 for term in technical_terms if term.lower() in prediction.lower())
technical_score = min(technical_score / 3, 1.0)
# Score explanation quality
explanation_score = sum(1 for marker in explanation_quality_markers if marker in prediction.lower())
explanation_score = min(explanation_score / 2, 1.0)
# Check response completeness
word_count = len(prediction.split())
completeness_score = min(word_count / 50, 1.0)
# Overall score
overall_score = (technical_score + explanation_score + completeness_score) / 3
return {
"key": "domain_expertise",
"score": overall_score,
"comment": f"Technical: {technical_score:.2f}, Explanation: {explanation_score:.2f}, Completeness: {completeness_score:.2f}",
"metadata": {
"word_count": word_count,
"technical_terms_found": technical_score * 3,
"explanation_markers_found": explanation_score * 2
}
}
def response_structure_evaluator(run: Run, example: Example) -> dict:
"""Evaluator that checks if responses follow expected structure"""
prediction = run.outputs.get("answer", "")
# Check for structured response elements
has_introduction = bool(re.search(r'^[A-Z].*[.!?]', prediction))
has_examples = "example" in prediction.lower() or "for instance" in prediction.lower()
has_conclusion = any(phrase in prediction.lower() for phrase in ["in conclusion", "to summarize"])
structure_score = sum([has_introduction, has_examples, has_conclusion]) / 3
return {
"key": "response_structure",
"score": structure_score,
"comment": f"Introduction: {has_introduction}, Examples: {has_examples}, Conclusion: {has_conclusion}"
}
# Use custom evaluators in evaluation
results = evaluate(
my_rag_application,
data="technical_qa_dataset",
evaluators=[
domain_expertise_evaluator,
response_structure_evaluator,
Correctness() # Mix custom and built-in evaluators
],
experiment_prefix="custom_evaluation_v1"
)
Sometimes you need an LLM to evaluate LLM outputs. Here's a sophisticated implementation:
# LLM Judge Evaluator Function
def llm_judge_evaluator(run: Run, example: Example) -> dict:
"""
Use GPT-4 as a judge to evaluate response quality
"""
prediction = run.outputs.get("answer", "")
question = example.inputs.get("question", "")
reference = example.outputs.get("reference_answer", "") if example.outputs else ""
evaluation_prompt = f"""
You are an expert evaluator of AI assistant responses. Please evaluate the following resp
1. Accuracy: Is the information factually correct?
2. Completeness: Does the response fully answer the question?
3. Clarity: Is the response clear and well-structured?
4. Relevance: Does the response stay focused on the question?
Question: {question}
Response to evaluate: {prediction}
Reference answer (if available): {reference}
Please provide your evaluation as a JSON object with the following structure:
{{
"accuracy": ,
"completeness": ,
"clarity": ,
"relevance": ,
"overall": ,
"reasoning": ""
}}
Only return the JSON, no additional text.
"""
try:
judge_response = openai_client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": evaluation_prompt}],
temperature=0.1
)
evaluation = json.loads(judge_response.choices.message.content)
overall_score = evaluation.get("overall", 0) / 10 # Normalize to 0-1
return {
"key": "llm_judge_evaluation",
"score": overall_score,
"comment": evaluation.get("reasoning", ""),
"metadata": evaluation
}
except Exception as e:
return {
"key": "llm_judge_evaluation",
"score": 0.0,
"comment": f"Evaluation failed: {str(e)}"
}
Sometimes you need human judgment to validate your AI systems. LangSmith makes collecting and incorporating human feedback straightforward.
Annotation queues provide a streamlined interface for human reviewers to evaluate AI outputs:
# Create an annotation queue programmatically
queue_config = {
"name": "Customer Support Quality Review",
"description": "Review customer support responses for quality and accuracy",
"default_dataset": "customer_support_responses",
"instructions": """
Please evaluate each response based on:
1. Accuracy of information provided
2. Helpfulness to the customer
3. Professional tone and clarity
4. Completeness of the answer
Rate each criterion on a scale of 1-5.
""",
"feedback_keys": [
{
"key": "accuracy",
"description": "Is the information factually correct?",
"type": "categorical",
"categories": ["1", "2", "3", "4", "5"]
},
{
"key": "helpfulness",
"description": "How helpful is this response to the customer?",
"type": "categorical",
"categories": ["1", "2", "3", "4", "5"]
},
{
"key": "overall_quality",
"description": "Overall response quality",
"type": "categorical",
"categories": ["Poor", "Fair", "Good", "Very Good", "Excellent"]
}
],
# Multiple reviewers for reliability
"num_reviewers_per_run": 2,
# Prevent conflicts
"enable_reservations": True
}
# Add feedback to specific runs
ls_client.create_feedback(
run_id="your-run-id",
key="user_satisfaction",
score=0.8, # 0-1 scale
comment="Response was accurate but could be more detailed",
metadata={
"reviewer_id": "reviewer_123",
"review_date": "2024-08-21",
"criteria": {
"accuracy": 5,
"helpfulness": 4,
"clarity": 4
}
}
)
# Query runs with specific feedback patterns
high_quality_runs = ls_client.list_runs(
project_name="customer_support",
filter='and(gte(feedback_avg_score, 0.8), has(feedback_key, "user_satisfaction"))'
)
# Use high-quality runs to create training datasets
for run in high_quality_runs:
# Add to dataset for few-shot examples
ls_client.create_example(
dataset_id="high_quality_examples",
inputs=run.inputs,
outputs=run.outputs,
metadata={
"source": "human_validated",
"quality_score": run.feedback_stats.get("user_satisfaction", {}).get("avg", 0)
}
)
LangSmith evaluation interface showing detailed test results, scores, and comparison between different prompt versions
High-quality datasets are the foundation of reliable LLM applications. LangSmith provides sophisticated tools for creating, managing, and evolving your evaluation datasets.
LangSmith supports flexible dataset schemas that ensure consistency while allowing for iterative development:
# Langsmith dataset creation example
from langsmith import Client
import json
client = Client()
# Define a schema for your dataset
schema_definition = {
"input_schema": {
"question": {"type": "string", "required": True},
"context": {"type": "string", "required": False},
"user_id": {"type": "string", "required": False},
"difficulty_level": {"type": "string", "enum": ["easy", "medium", "hard"]}
},
"output_schema": {
"reference_answer": {"type": "string", "required": True},
"expected_sources": {"type": "array", "items": {"type": "string"}},
"quality_score": {"type": "number", "minimum": 0, "maximum": 1}
}
}
# Create dataset with schema
dataset = client.create_dataset(
dataset_name="customer_qa_v2",
description="Customer Q&A with validation schema",
metadata={
"schema": schema_definition,
"version": "2.0",
"created_by": "data_team"
}
)
# Add examples that conform to schema
examples = [
{
"inputs": {
"question": "How do I reset my password?",
"difficulty_level": "easy",
"user_id": "user_123"
},
"outputs": {
"reference_answer": "To reset your password, go to the login page and click ...",
"expected_sources": ["help_documentation", "user_guide"],
"quality_score": 0.95
},
"metadata": {
"source": "customer_service_team",
"validated": True
}
}
]
# Batch create examples
for example_data in examples:
client.create_example(
dataset_id=dataset.id,
inputs=example_data["inputs"],
outputs=example_data["outputs"],
metadata=example_data["metadata"]
)
LangSmith can generate synthetic examples to enhance your datasets:
# Generate synthetic examples based on existing patterns
def generate_synthetic_examples(base_dataset: str, num_examples: 50):
"""Generate synthetic examples using LLM"""
# Get existing examples for pattern learning
existing_examples = list(client.list_examples(dataset_name=base_dataset, limit=10))
# Create generation prompt based on patterns
pattern_examples = "\n\n".join([
f"Question: {ex.inputs['question']}\nAnswer: {ex.outputs['reference_answer']}"
for ex in existing_examples[:5]
])
generation_prompt = f"""
Based on these example question-answer pairs, generate {num_examples} new similar example
{pattern_examples}
Generate new examples that follow the same pattern and domain. For each example, provide:
1. A unique question
2. A comprehensive answer
3. A difficulty level (easy/medium/hard)
Format as JSON array with objects containing 'question', 'answer', and 'difficulty_level'
"""
response = openai_client.chat.completions.create(
model="gpt-4",
messages=[{'role': 'user', 'content': generation_prompt}],
temperature=0.7
)
try:
synthetic_examples = json.loads(response.choices.message.content)
# Add synthetic examples to dataset
for example in synthetic_examples:
client.create_example(
dataset_id=dataset.id,
inputs={
'question': example['question'],
'difficulty_level': example['difficulty_level']
},
outputs={
'reference_answer': example['answer'],
'quality_score': 0.8 # Lower score for synthetic data
},
metadata={
'source': 'synthetic_generation',
'generated_at': '2024-08-21',
'needs_review': True
}
)
except json.JSONDecodeError:
print("Failed to parse synthetic examples")
# Generate synthetic data
generate_synthetic_examples("customer_qa_v2", num_examples=25)
# Create dataset versions for different stages of development
def create_dataset_version(base_dataset: str, version_name: str, filter_criteria: dict):
"""Create a new version of a dataset with specific criteria"""
# Query examples based on criteria
examples = list(client.list_examples(
dataset_name=base_dataset,
limit=1000 # Adjust based on your needs
))
# Filter examples based on criteria
filtered_examples = []
for example in examples:
if all(
example.metadata.get(key) == value
for key, value in filter_criteria.items()
):
filtered_examples.append(example)
# Create new dataset version
new_dataset = client.create_dataset(
dataset_name=f"{base_dataset}_{version_name}",
description=f"Version {version_name} of {base_dataset} dataset",
metadata={
"base_dataset": base_dataset,
"version": version_name,
"filter_criteria": filter_criteria,
"example_count": len(filtered_examples)
}
)
# Copy filtered examples to new dataset
for example in filtered_examples:
client.create_example(
dataset_id=new_dataset.id,
inputs=example.inputs,
outputs=example.outputs,
metadata={**example.metadata, "version": version_name}
)
return new_dataset
# Create different dataset versions
prod_dataset = create_dataset_version(
"customer_qa_v2",
"production",
{"validated": True, "quality_score": 0.9}
)
test_dataset = create_dataset_version(
"customer_qa_v2",
"regression_test",
{"source": "customer_service_team"}
)
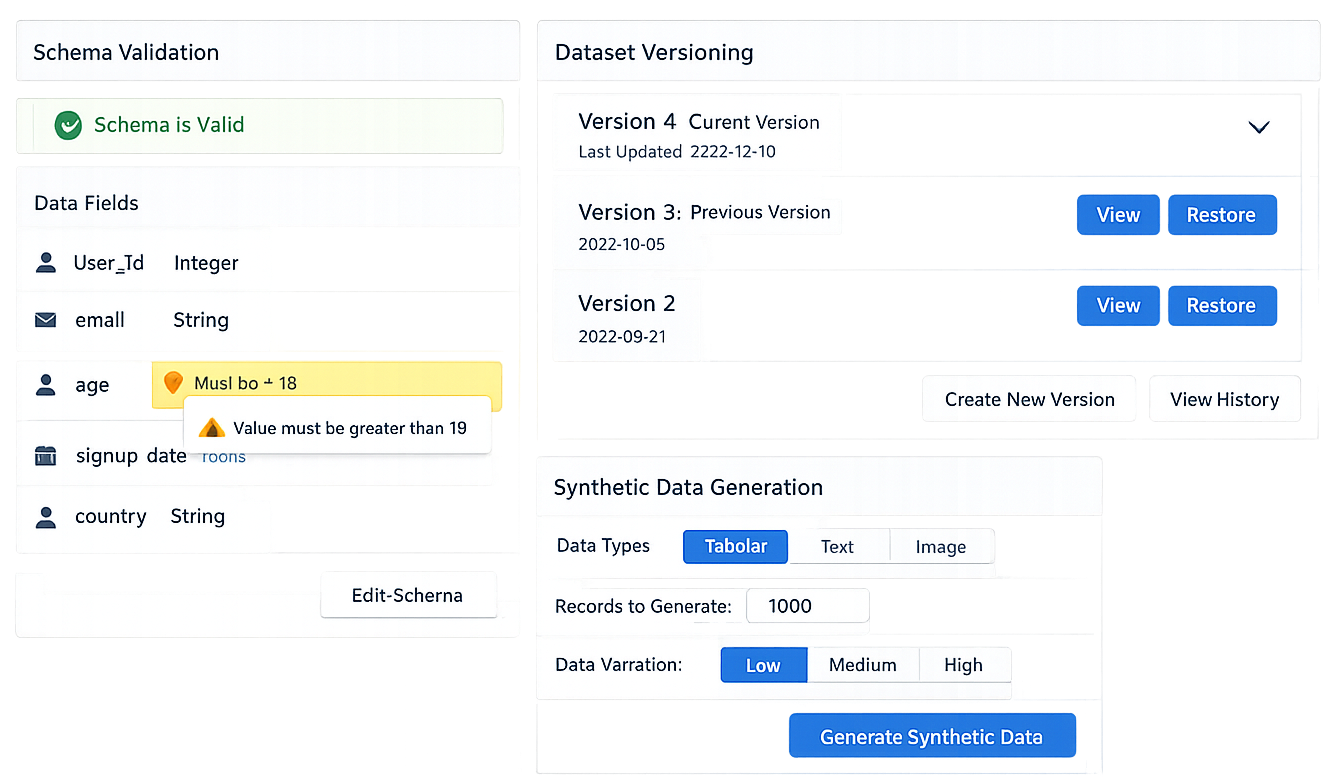
Dataset management interface showing schema validation, version control, and synthetic data generation features
Managing prompts across a team can quickly become chaotic without proper version control. LangSmith's prompt hub provides Git-like functionality specifically designed for prompt management.
You can create and manage prompts directly in the LangSmith UI or programmatically:
# LangSmith advanced prompt and chat templates
from langsmith import Client
import json
client = Client()
# Create a sophisticated prompt template
advanced_prompt_template = """
You are an expert {role} with {experience_years} years of experience. Your task is to {ta
Context Information:
{context}
Specific Requirements:
{requirements}
Constraints:
- Keep response under {max_words} words
- Use {tone} tone
- Include {num_examples} specific examples
- Target audience: {audience_level}
Additional Instructions:
{additional_instructions}
Please provide your response following this structure:
1. Executive Summary
2. Detailed Analysis
3. Recommendations
4. Next Steps
Response:
"""
# Save advanced prompt to LangSmith
client.create_prompt(
prompt_name="expert_consultant_template",
object_type="prompt",
template=advanced_prompt_template,
metadata={
"category": "consulting",
"complexity": "advanced",
"variables": [
"role", "experience_years", "task_description",
"context", "requirements", "max_words", "tone",
"num_examples", "audience_level", "additional_instructions"
],
"use_cases": ["business_consulting", "technical_analysis", "strategic_planning"]
}
)
# Create chat-based prompt for conversational AI
chat_prompt_template = [
{
"role": "system",
"content": """You are a {personality_type} AI assistant specialized in {domain}.
Your communication style:
- {communication_style}
- Always acknowledge the user's context: {user_context}
- Adapt your expertise level to: {expertise_level}
Remember these key principles:
{key_principles}"""
},
{
"role": "user",
"content": "{user_input}"
}
]
client.create_prompt(
prompt_name="adaptive_chat_assistant",
object_type="chat",
template=chat_prompt_template,
metadata={
"type": "conversational",
"adaptivity": "high",
"domains": ["customer_support", "technical_help", "sales"]
}
)
Here's how to implement sophisticated prompt version control:
# LangChain prompt deployment example
from langchain import hub
import hashlib
import datetime
def deploy_prompt_version(prompt_name: str, environment: str, test_results: dict):
"""Deploy a prompt version after validation"""
# Pull latest version for testing
latest_prompt = hub.pull(f"your-org/{prompt_name}")
# Run validation tests
validation_passed = all(
score >= 0.8 for score in test_results.values()
)
if validation_passed:
# Tag the version for deployment
version_hash = hashlib.md5(str(latest_prompt).encode()).hexdigest()[:8]
# Create deployment tag
hub.push(
f"your-org/{prompt_name}",
latest_prompt,
commit_message=f"Deploy to {environment} - validation scores: {test_results}",
tags=[f"{environment}-v{version_hash}", f"deployed-{datetime.date.today()}"]
)
return version_hash
else:
raise ValueError(f"Validation failed: {test_results}")
# Example deployment workflow
test_results = {
"accuracy": 0.92,
"helpfulness": 0.87,
"safety": 0.95
}
try:
version = deploy_prompt_version("customer_support_agent", "production", test_results)
print(f"Successfully deployed version {version} to production")
except ValueError as e:
print(f"Deployment failed: {e}")
# Use specific version in production
production_prompt = hub.pull(f"your-org/customer_support_agent:production-v{version}")
Implement sophisticated A/B testing for prompt optimization:
import random
from langsmith import traceable
import hashlib
class PromptABTester:
def __init__(self, prompt_variants: dict, traffic_split: dict):
self.prompt_variants = prompt_variants
self.traffic_split = traffic_split
def get_prompt_version(self, user_id: str) -> tuple:
"""Deterministic assignment based on user_id"""
user_hash = int(hashlib.md5(user_id.encode()).hexdigest(), 16)
user_bucket = user_hash % 100
cumulative_split = 0
for version, percentage in self.traffic_split.items():
cumulative_split += percentage
if user_bucket < cumulative_split:
return version, self.prompt_variants[version]
# Default fallback
return "control", self.prompt_variants["control"]
# Define prompt variants
prompt_variants = {
"control": """Answer the user's question directly and concisely.\nQuestion: {question}\nAnswer:""",
"detailed": """Provide a comprehensive answer to the user's question. Include context\nQuestion: {question}\nAnswer:""",
"conversational": """You're a friendly expert. Answer the user's question in a conver\nQuestion: {question}\nAnswer:"""
}
# Set up A/B test
ab_tester = PromptABTester(
prompt_variants=prompt_variants,
traffic_split={ "control": 40, "detailed": 30, "conversational": 30 }
)
@traceable(name="AB Test Response Generator")
def ab_test_response(user_id: str, question: str) -> dict:
"""Generate response using A/B tested prompts"""
variant_name, prompt_template = ab_tester.get_prompt_version(user_id)
formatted_prompt = prompt_template.format(question=question)
response = openai_client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": formatted_prompt}],
temperature=0.7
)
# Tag the run with variant info for analysis
return {
"response": response.choices.message.content,
"variant": variant_name,
"user_id": user_id,
"question": question,
"prompt_used": formatted_prompt
}
# Test the A/B system
for i in range(10):
result = ab_test_response(f"user_{i}", "What is machine learning?")
print(f"User {i}: Variant {result['variant']}")
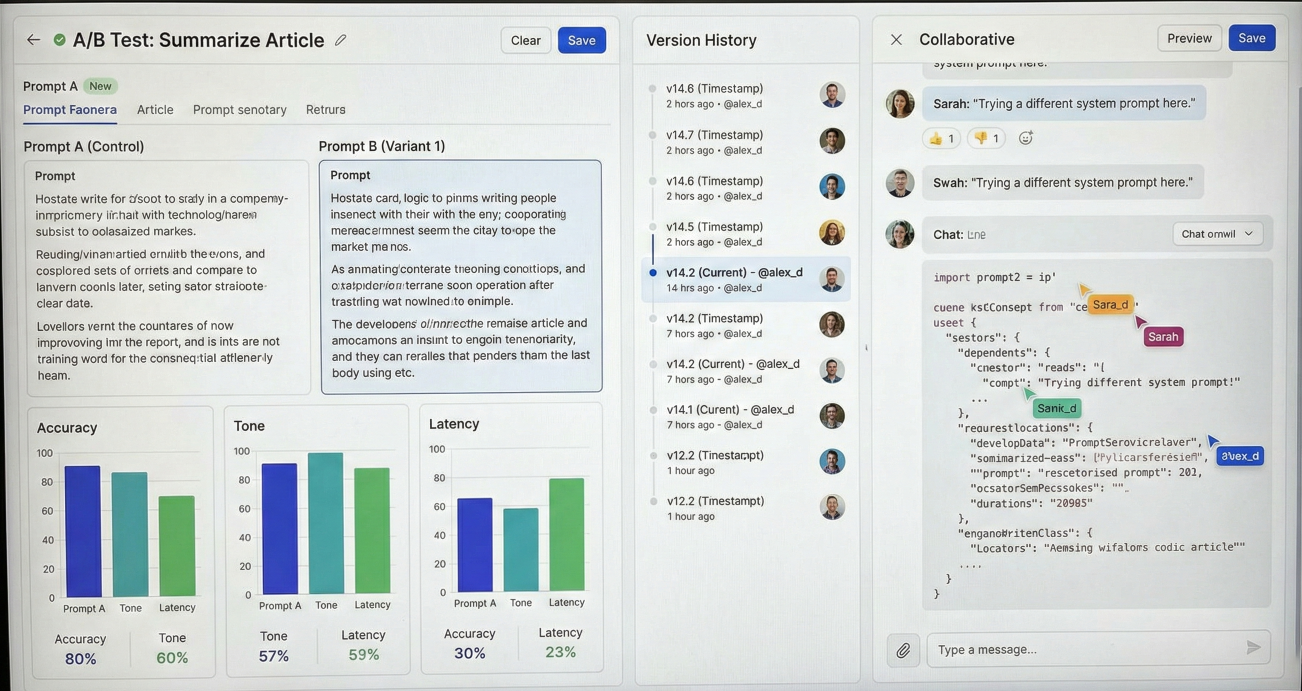
Prompt engineering interface showing A/B testing results, version history, and collaborative editing features
Once your LLM application is live, comprehensive monitoring becomes critical. LangSmith's alerting system helps you catch issues before your users do.
LangSmith supports alerts on a wide range of metrics:
# Configure comprehensive alert system
alert_configurations = [
{
"name": "High Error Rate Alert",
"metric": "error_rate",
"threshold": 0.05, # Alert if error rate exceeds 5%
"aggregation_window": "15_minutes",
"notification_channels": [
{
"type": "webhook",
"url": "https://hooks.slack.com/services/YOUR/SLACK/WEBHOOK",
"headers": {
"Content-Type": "application/json",
"Authorization": "Bearer your-token"
},
"body_template": {
"text": "🚨 LangSmith Alert: Error rate exceeded {threshold}% in project",
"channel": "#ai-alerts",
"username": "LangSmith Bot"
}
},
{
"type": "pagerduty",
"integration_key": "your-pagerduty-key",
"severity": "warning"
}
]
},
# Additional alerts follow similarly...
]
# Alerts Configuration JSON
{
"name": "Latency Spike Alert",
"metric": "p95_latency",
"threshold": 10.0, # Alert if P95 latency exceeds 10 seconds
"aggregation_window": "10_minutes",
"notification_channels": [
{
"type": "webhook",
"url": "https://your-monitoring-system.com/alerts",
"body_template": {
"alert_type": "latency_spike",
"threshold": "{threshold}",
"current_value": "{current_value}",
"project": "{project_name}",
"timestamp": "{timestamp}"
}
}
],
}
{
"name": "Cost Threshold Alert",
"metric": "total_cost",
"threshold": 100.0, # Alert if daily cost exceeds $100
"aggregation_window": "1_day",
"notification_channels": [
{
"type": "email",
"recipients": ["team@company.com", "finance@company.com"],
"subject": "LangSmith Daily Cost Alert - {project_name}",
"body": "Daily LLM costs have exceeded ${threshold} for project {project_}"
}
],
},
{
"name": "Feedback Score Drop",
"metric": "avg_feedback_score",
"threshold": 0.7, # Alert if average feedback drops below 70%
"comparison": "less_than",
"aggregation_window": "1_hour",
"notification_channels": [
{
"type": "webhook",
"url": "https://hooks.slack.com/services/YOUR/SLACK/WEBHOOK",
"body_template": {
"text": "📉 Quality Alert: User feedback scores dropped to {current_va}",
"channel": "#quality-alerts"
}
}
]
}
]
Create custom monitoring solutions for specific business metrics:
# LangSmith Monitoring System Example
from langsmith import Client
import pandas as pd
import json
from datetime import datetime, timedelta
class LangSmithMonitor:
def __init__(self, client: Client):
self.client = client
def get_business_metrics(self, project_name: str, days: 7) -> dict:
"""Get business-focused metrics"""
end_time = datetime.now()
start_time = end_time - timedelta(days=days)
# Get all runs in the time period
runs = list(self.client.list_runs(
project_name=project_name,
start_time=start_time.isoformat(),
end_time=end_time.isoformat(),
limit=10000
))
# Calculate business metrics
total_requests = len(runs)
successful_requests = len([r for r in runs if r.status == 'success'])
failed_requests = total_requests - successful_requests
# Cost analysis
total_cost = sum(r.total_cost or 0 for r in runs)
cost_by_model = {}
for run in runs:
model = run.extra.get('invocation_params', {}).get('model', 'unknown')
cost_by_model[model] = cost_by_model.get(model, 0) + (run.total_cost or 0)
# Performance analysis
latencies = [(r.end_time - r.start_time).total_seconds() for r in runs if r.end_time and r.start_time]
# User satisfaction analysis
feedback_scores = []
for run in runs:
if hasattr(run, 'feedback_stats') and run.feedback_stats:
for key, stats in run.feedback_stats.items():
if 'avg' in stats:
feedback_scores.append(stats['avg'])
return {
"period": f"{days} days",
"total_requests": total_requests,
"success_rate": successful_requests / total_requests if total_requests > 0 else 0,
"error_rate": failed_requests / total_requests if total_requests > 0 else 0,
"total_cost": total_cost,
"cost_per_request": total_cost / total_requests if total_requests > 0 else 0,
"cost_by_model": cost_by_model,
"avg_latency": sum(latencies) / len(latencies) if latencies else 0,
"p95_latency": pd.Series(latencies).quantile(0.95) if latencies else 0,
"avg_satisfaction": sum(feedback_scores) / len(feedback_scores) if feedback_scores else 0,
"satisfaction_responses": len(feedback_scores)
}
# LangSmith Daily Report Example
def generate_daily_report(self, project_name: str) -> str:
"""Generate a comprehensive daily report"""
metrics = self.get_business_metrics(project_name, days=1)
week_metrics = self.get_business_metrics(project_name, days=7)
report = f"""
# LangSmith Daily Report - {project_name}
Date: {datetime.now().strftime('%Y-%m-%d')}
## 📊 Performance Summary (Last 24 Hours)
- **Total Requests**: {metrics['total_requests']:,}
- **Success Rate**: {metrics['success_rate']:.2%}
- **Average Latency**: {metrics['avg_latency']:.2f} seconds
- **P95 Latency**: {metrics['p95_latency']:.2f} seconds
## 💰 Cost Analysis
- **Total Cost**: ${metrics['total_cost']:.2f}
- **Cost per Request**: ${metrics['cost_per_request']:.4f}
- **Top Models by Cost**:
"""
# Add top 3 models by cost
sorted_models = sorted(metrics['cost_by_model'].items(), key=lambda x: x[^1], rev)
for model, cost in sorted_models[:3]:
report += f" - {model}: ${cost:.2f}\n"
# Add satisfaction metrics if available
if metrics['avg_satisfaction'] is not None:
report += f"\n## 😊 User Satisfaction\n"
report += f"- **Average Score**: {metrics['avg_satisfaction']:.2f}/5.0\n"
report += f"- **Total Responses**: {metrics['satisfaction_responses']}\n"
# Weekly comparison
report += f"\n## 📈 Weekly Trends\n"
report += f"- **Request Volume**: {((metrics['total_requests'] * 7) / week_metrics)}\n"
report += f"- **Cost Trend**: {((metrics['total_cost'] * 7) / week_metrics)}\n"
return report
# Use the monitoring system
monitor = LangSmithMonitor(ls_client)
daily_report = monitor.generate_daily_report("your_production_project")
print(daily_report)
# Set up automated reporting (example with email)
def send_daily_report(project_name: str):
"""Send daily report via email or Slack"""
report = monitor.generate_daily_report(project_name)
# Example: Send to Slack
slack_webhook = "https://hooks.slack.com/services/YOUR/SLACK/WEBHOOK"
payload = {
"text": f"``````",
"channel": "#ai-reports",
"username": "LangSmith Reporter"
}
# In production, you'd actually send this request
print(f"Would send report to Slack: {len(report)} characters")
Production monitoring dashboard showing real-time alerts, cost tracking, performance metrics, and business KPIs
For large-scale deployments, LangSmith offers enterprise features including self-hosting, advanced security, and extensive integration capabilities.
LangSmith can be deployed in your own infrastructure for maximum security and control:
# docker-compose.yml for self-hosted LangSmith
version: '3.8'
services:
langsmith-frontend:
image: langchain/langsmith-frontend:latest
ports:
- "3000:3000"
environment:
- BACKEND_URL=http://langsmith-backend:8000
depends_on:
- langsmith-backend
langsmith-backend:
image: langchain/langsmith-backend:latest
ports:
- "8000:8000"
environment:
- DATABASE_URL=postgresql://user:password@postgres:5432/langsmith
- REDIS_URL=redis://redis:6379
- CLICKHOUSE_URL=http://clickhouse:8123
depends_on:
- postgres
- redis
- clickhouse
langsmith-platform-backend:
image: langchain/langsmith-platform-backend:latest
environment:
- DATABASE_URL=postgresql://user:password@postgres:5432/langsmith
langsmith-playground:
image: langchain/langsmith-playground:latest
environment:
- BACKEND_URL=http://langsmith-backend:8000
langsmith-queue:
image: langchain/langsmith-queue:latest
environment:
- REDIS_URL=redis://redis:6379
postgres:
image: postgres:13
environment:
- POSTGRES_DB=langsmith
- POSTGRES_USER=user
- POSTGRES_PASSWORD=password
volumes:
- postgres_data:/var/lib/postgresql/data
redis:
image: redis:6-alpine
volumes:
- redis_data:/data
clickhouse:
image: clickhouse/clickhouse-server:latest
environment:
- CLICKHOUSE_DB=langsmith
- CLICKHOUSE_USER=default
- CLICKHOUSE_PASSWORD=password
volumes:
- clickhouse_data:/var/lib/clickhouse
volumes:
postgres_data:
redis_data:
clickhouse_data:
For enterprises with strict security requirements:
# Secure LangSmith Client Example
from langsmith import Client
import hashlib
from cryptography.fernet import Fernet
class SecureLangSmithClient:
def __init__(self, api_key: str, encryption_key: bytes):
self.client = Client(api_key=api_key)
self.cipher = Fernet(encryption_key)
def create_secure_example(self, dataset_id: str, inputs: dict, outputs: dict, metadata: dict):
"""Create example with PII encryption"""
# Identify and encrypt PII fields
secure_inputs = self._encrypt_pii_fields(inputs)
secure_outputs = self._encrypt_pii_fields(outputs)
# Hash user identifiers
if 'user_id' in metadata:
metadata['user_id_hash'] = hashlib.sha256(
metadata['user_id'].encode()
).hexdigest()
del metadata['user_id']
return self.client.create_example(
dataset_id=dataset_id,
inputs=secure_inputs,
outputs=secure_outputs,
metadata=metadata
)
def _encrypt_pii_fields(self, data: dict) -> dict:
"""Encrypt potential PII fields"""
pii_fields = ['email', 'phone', 'ssn', 'credit_card', 'name']
secure_data = data.copy()
for field in pii_fields:
if field in secure_data and isinstance(secure_data[field], str):
secure_data[field] = self.cipher.encrypt(
secure_data[field].encode()
).decode()
return secure_data
def decrypt_pii_fields(self, data: dict) -> dict:
"""Decrypt PII fields for authorized access"""
# Implementation for decryption with proper authorization checks
pass
# Usage with enterprise security
encryption_key = Fernet.generate_key()
secure_client = SecureLangSmithClient("your-api-key", encryption_key)
Integrate LangSmith into your development pipeline:
# .github/workflows/langsmith-evaluation.yml
name: LangSmith Evaluation Pipeline
on:
pull_request:
branches: [main]
push:
branches: [main]
jobs:
evaluate-changes:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Set up Python
uses: actions/setup-python@v4
with:
python-version: '3.9'
- name: Install dependencies
run: |
pip install langsmith openevals openai
- name: Run LangSmith Evaluations
env:
LANGSMITH_API_KEY: ${{ secrets.LANGSMITH_API_KEY }}
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
LANGSMITH_PROJECT: "ci-cd-evaluation-${{ github.run_id }}"
run: |
python scripts/run_evaluations.py
- name: Post Results to PR
uses: actions/github-script@v6
with:
script: |
const fs = require('fs');
const results = JSON.parse(fs.readFileSync('evaluation_results.json'));
const comment = `## 🧪 LangSmith Evaluation Results
- **Accuracy**: ${results.accuracy.toFixed(2)}
- **Helpfulness**: ${results.helpfulness.toFixed(2)}
- **Safety**: ${results.safety.toFixed(2)}
${results.accuracy >= 0.8 ? '✅' : '❌'} **Quality Gate**: ${results.accuracy >= `;
github.rest.issues.createComment({
issue_number: context.issue.number,
owner: context.repo.owner,
repo: context.repo.repo,
body: comment
});
deploy-if-passed:
needs: evaluate-changes
runs-on: ubuntu-latest
if: github.ref == 'refs/heads/main'
steps:
- name: Deploy to Production
run: |
echo "Deploying to production..."
# Your deployment script here
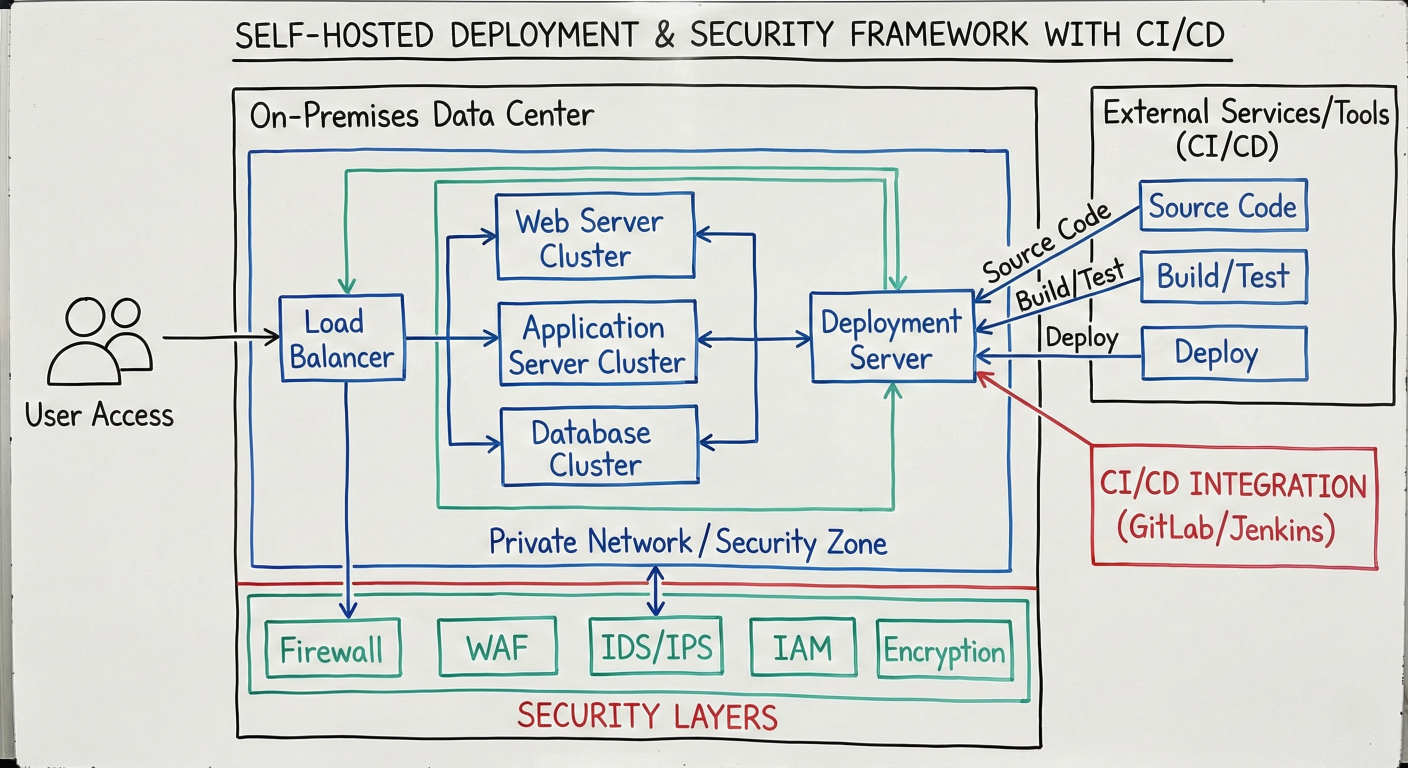
Enterprise architecture diagram showing self-hosted deployment, security layers, and CI/CD integration
Let's explore some sophisticated real-world applications of LangSmith for complex AI systems.
For applications handling text, images, and audio:
# Multi-modal AI analysis example
from langsmith import traceable
import openai
import base64
from PIL import Image
import io
@traceable(name="Multi-Modal Analysis", run_type="chain")
def analyze_customer_inquiry(text_input: str, image_data: bytes=None, audio_data: bytes=None) -> dict:
"""Analyze customer inquiry across multiple modalities"""
analysis_results = {}
# Process text input
if text_input:
text_analysis = analyze_text_sentiment(text_input)
analysis_results['text_analysis'] = text_analysis
# Process image if provided
if image_data:
image_analysis = analyze_product_image(image_data)
analysis_results['image_analysis'] = image_analysis
# Process audio if provided
if audio_data:
audio_analysis = transcribe_and_analyze_audio(audio_data)
analysis_results['audio_analysis'] = audio_analysis
# Generate comprehensive response
comprehensive_response = generate_multi_modal_response(analysis_results)
return {
"analysis_results": analysis_results,
"response": comprehensive_response,
"modalities_processed": len(analysis_results),
"confidence_scores": extract_confidence_scores(analysis_results)
}
# Text and Image Analysis with LLM and Vision API
@traceable(name="Text Sentiment Analysis", run_type="llm")
def analyze_text_sentiment(text: str) -> dict:
"""Analyze sentiment and extract key information from text"""
response = openai_client.chat.completions.create(
model="gpt-4",
messages=[
{"role": "system",
"content": "Analyze the sentiment and extract key issues from customer text."},
{"role": "user", "content": text}
]
)
return {
"sentiment": "positive", # Parse from response
"key_issues": ["billing", "service_quality"], # Extract from response
"urgency": "medium", # Determine urgency level
"confidence": 0.85
}
@traceable(name="Product Image Analysis", run_type="tool")
def analyze_product_image(image_data: bytes) -> dict:
"""Analyze product images for defects or issues"""
# Convert image data for vision API
base64_image = base64.b64encode(image_data).decode()
response = openai_client.chat.completions.create(
model="gpt-4-vision-preview",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Analyze this product image for any defects, damage, or q"},
{
"type": "image_url",
"image_url": {"url": f"}
}
]
}
]
)
return {
"defects_detected": False,
"quality_score": 0.92,
"identified_product": "smartphone_case",
"analysis_confidence": 0.88
}
# Evaluate multi-modal system
def evaluate_multi_modal_system():
"""Comprehensive evaluation for multi-modal AI system"""
test_cases = [
{
"text": "I'm having issues with my recent order",
"image_path": "sample_images/damaged_product.jpg",
"expected_urgency": "high",
"expected_sentiment": "negative"
},
{
"text": "Love the new features in your app!",
"expected_urgency": "low",
"expected_sentiment": "positive"
}
]
results = []
for case in test_cases:
image_data = None
if case.get("image_path"):
with open(case["image_path"], "rb") as f:
image_data = f.read()
result = analyze_customer_inquiry(
text_input=case["text"],
image_data=image_data
)
results.append({
"case": case,
"result": result,
"passed": validate_multi_modal_result(result, case)
})
return results
# Multi-modal specific evaluator
def multi_modal_evaluator(run: Run, example: Example) -> dict:
"""Custom evaluator for multi-modal AI systems"""
outputs = run.outputs
expected = example.outputs
modalities_score = 1.0 if outputs.get("modalities_processed", 0) >= expected.get("expected_modalities", 0) else 0.0
confidence_scores = outputs.get("confidence_scores", {})
avg_confidence = sum(confidence_scores.values()) / len(confidence_scores) if confidence_scores else 0
confidence_score = 1.0 if avg_confidence >= 0.8 else avg_confidence
overall_score = (modalities_score + confidence_score) / 2
return {
"key": "multi_modal_quality",
"score": overall_score,
"comment": f< span class="token-string">"Modalities: {modalities_score}, Confidence: {confidence_score:.2f}",
"metadata": {
"modalities_processed": outputs.get("modalities_processed", 0),
"avg_confidence": avg_confidence
}
}
For enterprise RAG systems serving thousands of users:
# Enterprise RAG System with LangSmith tracing
from langsmith import traceable, Client
import numpy as np
from typing import List, Dict
import asyncio
class EnterpriseRAGSystem:
def __init__(self, client: Client):
self.client = client
self.vector_store = None # Your vector store
self.reranker = None # Your reranking model
@traceable(name="Hierarchical Retrieval", run_type="retriever")
async def hierarchical_retrieve(self, query: str, user_context: dict) -> List[dict]:
"""Multi-stage retrieval with user context"""
semantic_results = await self.semantic_search(query, top_k=50)
filtered_results = self.filter_by_user_context(semantic_results, user_context)
reranked_results = await self.rerank_results(query, filtered_results, top_k=10)
return reranked_results
@traceable(name="Adaptive Response Generation", run_type="llm")
async def generate_adaptive_response(self, query: str, context: List[dict], user_profile: dict)->dict:
"""Generate response adapted to user profile and context"""
style_prompt = self.get_style_prompt(user_profile)
context_text = "\n".join([doc["content"] for doc in context])
system_prompt = f"""
{style_prompt}
Use the following context to answer the user's question:
{context_text}
Remember to:
- Cite specific sources when making claims
- Adapt your explanation level to the user's expertise: {user_profile.get('expertise_level', 'general')}
- Include relevant examples for their industry: {user_profile.get('industry', 'general')}
"""
response = await openai_client.achat.completions.create(
model="gpt-4",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": query}
],
temperature=0.7
)
return {
"response": response.choices.message.content,
"sources_used": [doc["source"] for doc in context],
"adaptation_applied": True,
"user_expertise_level": user_profile.get('expertise_level')
}
@traceable(name="Enterprise RAG Pipeline", run_type="chain")
async def process_query(self, query: str, user_id: str) -> dict:
"""Complete RAG pipeline with enterprise features"""
user_context = await self.get_user_context(user_id)
user_profile = await self.get_user_profile(user_id)
retrieved_docs = await self.hierarchical_retrieve(query, user_context)
response_data = await self.generate_adaptive_response(query, retrieved_docs, user_profile)
await self.log_user_interaction(user_id, query, response_data)
return {
**response_data,
"query": query,
"user_id": user_id,
"retrieval_count": len(retrieved_docs),
"personalized": True
}
# Enterprise RAG Pipeline & Evaluation
model="gpt-4",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": query}
],
temperature=0.7
)
return {
"response": response.choices.message.content,
"sources_used": [doc["source"] for doc in context],
"adaptation_applied": True,
"user_expertise_level": user_profile.get('expertise_level')
}
@traceable(name="Enterprise RAG Pipeline", run_type="chain")
async def process_query(self, query: str, user_id: str) -> dict:
"""Complete RAG pipeline with enterprise features"""
user_context = await self.get_user_context(user_id)
user_profile = await self.get_user_profile(user_id)
retrieved_docs = await self.hierarchical_retrieve(query, user_context)
response_data = await self.generate_adaptive_response(query, retrieved_docs, user_profile)
await self.log_user_interaction(user_id, query, response_data)
return {
**response_data,
"query": query,
"user_id": user_id,
"retrieval_count": len(retrieved_docs),
"personalized": True
}
retrieved_docs = await self.rag_system.hierarchical_retrieve(
query,
user_context=example.inputs.get("user_context", {})
)
retrieved_sources = [doc["source"] for doc in retrieved_docs]
precision = self.calculate_precision(retrieved_sources, expected_sources)
recall = self.calculate_recall(retrieved_sources, expected_sources)
f1_score = 2 * (precision * recall) / (precision + recall) if (precision + re
results.append({
"query": query,
"precision": precision,
"recall": recall,
"f1_score": f1_score,
"retrieved_count": len(retrieved_docs)
})
avg_precision = sum(r["precision"] for r in results) / len(results)
avg_recall = sum(r["recall"] for r in results) / len(results)
avg_f1 = sum(r["f1_score"] for r in results) / len(results)
return {
"avg_precision": avg_precision,
"avg_recall": avg_recall,
"avg_f1_score": avg_f1,
"total_queries": len(results),
"detailed_results": results
}
def calculate_precision(self, retrieved: List[str], expected: List[str]) -> float:
"""Calculate precision@k"""
if not retrieved:
return 0.0
relevant_retrieved = set(retrieved) & set(expected)
return len(relevant_retrieved) / len(retrieved)
def calculate_recall(self, retrieved: List[str], expected: List[str]) -> float:
"""Calculate recall@k"""
if not expected:
return 1.0
relevant_retrieved = set(retrieved) & set(expected)
return len(relevant_retrieved) / len(expected)
# Comprehensive RAG evaluation
async def run_comprehensive_rag_evaluation():
"""Run complete evaluation of RAG system"""
rag_system = EnterpriseRAGSystem(ls_client)
evaluator = RAGEvaluationFramework(rag_system)
# Evaluate different aspects
retrieval_results = await evaluator.evaluate_retrieval_quality("rag_test_dataset")
# End-to-end evaluation with LangSmith
end_to_end_results = evaluate(
rag_system.process_query,
data="rag_test_dataset",
evaluators=[
Correctness(),
Helpfulness(),
custom_rag_evaluator
],
experiment_prefix="rag_comprehensive_eval"
)
return {
"retrieval_metrics": retrieval_results,
"end_to_end_metrics": end_to_end_results
}
def custom_rag_evaluator(run: Run, example: Example) -> dict:
"""Custom evaluator for RAG-specific metrics"""
outputs = run.outputs
response = outputs.get("response", "")
sources_used = outputs.get("sources_used", [])
# Check citation quality
citation_score = 1.0 if len(sources_used) >= 2 else 0.5
# Check response completeness
word_count = len(response.split())
completeness_score = min(word_count / 100, 1.0)
# Check personalization effectiveness
personalization_score = 1.0 if outputs.get("personalized", False) else 0.0
overall_score = (citation_score + completeness_score + personalization_score) / 3
return {
"key": "rag_quality",
"score": overall_score,
"comment": f"Citations: {citation_score}, Completeness: {completeness_score}' Personalization: {personalization_score}",
"metadata": {
"sources_count": len(sources_used),
"word_count": word_count,
"personalized": outputs.get("personalized", False)
}
}
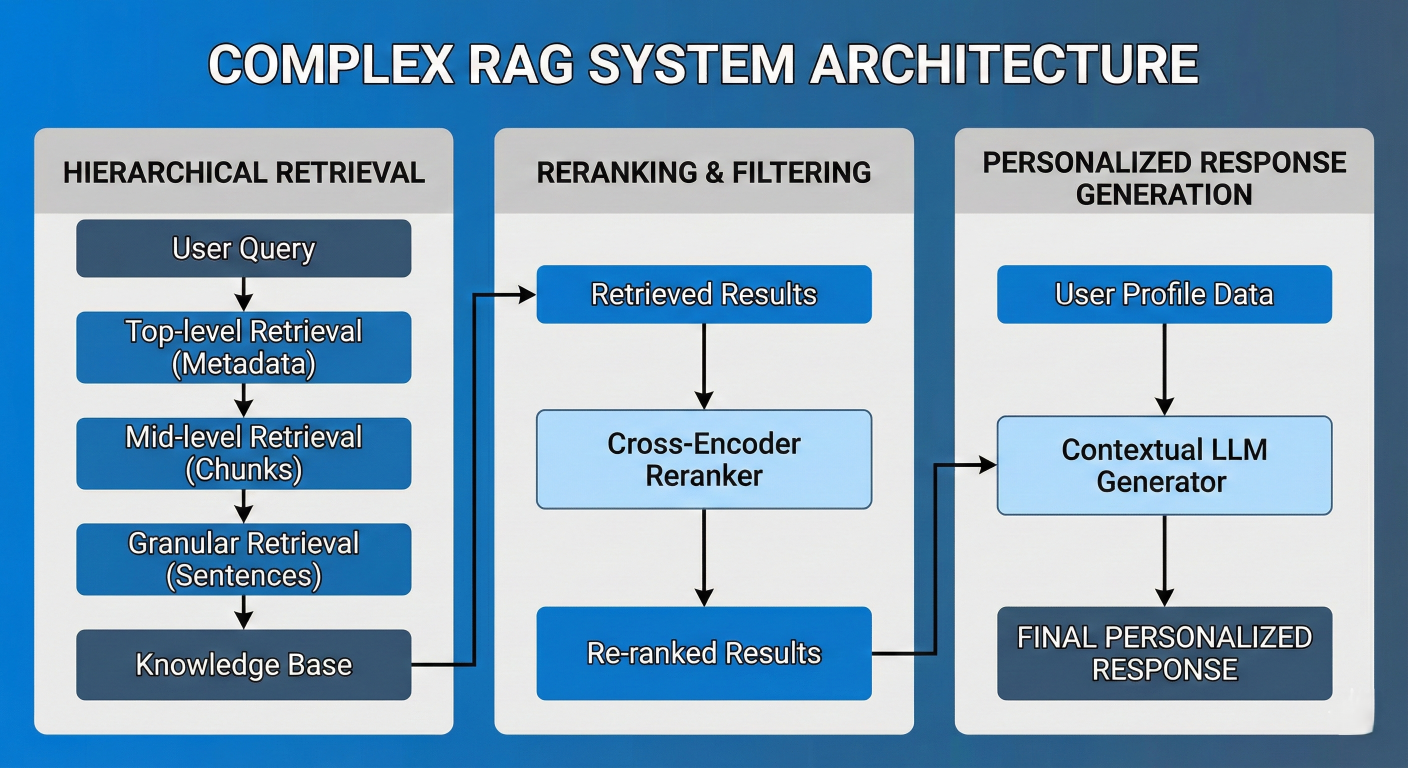
Complex RAG system architecture showing hierarchical retrieval, reranking, and personalized response generation
LLM applications can become expensive quickly. LangSmith provides detailed cost tracking and optimization tools:
from langsmith import Client
import pandas as pd
from datetime import datetime, timedelta
class CostOptimizationAnalyzer:
def __init__(self, client: Client):
self.client = client
def analyze_cost_patterns(self, project_name: 'str', days: int = 30) -> dict:
"""Comprehensive cost analysis and optimization recommendations"""
end_time = datetime.now()
start_time = end_time - timedelta(days=days)
# Get all runs with cost data
runs = list(self.client.list_runs(
project_name=project_name,
start_time=start_time.isoformat(),
end_time=end_time.isoformat(),
limit=50000
))
# Analyze cost by different dimensions
cost_analysis = self._analyze_cost_dimensions(runs)
# Generate optimization recommendations
recommendations = self._generate_cost_recommendations(cost_analysis)
return {
"analysis_period": f"{days} days",
"total_cost": cost_analysis["total_cost"],
"cost_breakdown": cost_analysis,
"optimization_recommendations": recommendations,
"potential_savings": self._calculate_potential_savings(cost_analysis)
}
def _analyze_cost_dimensions(self, runs: list) -> dict:
"""Analyze costs across multiple dimensions"""
df = pd.DataFrame([{
'run_id': run.id,
'model': run.extra.get('invocation_params', {}).get('model', 'unknown'),
'total_tokens': run.total_tokens or 0,
'prompt_tokens': getattr(run, 'prompt_tokens', 0),
'completion_tokens': getattr(run, 'completion_tokens', 0),
'total_cost': run.total_cost or 0,
'latency': (run.end_time - run.start_time).total_seconds() if run.end_time and run.start_time else None,
'run_type': run.run_type,
'status': run.status,
'timestamp': run.start_time,
'user_id': run.inputs.get('user_id') if run.inputs else None,
'session_id': run.inputs.get('session_id') if run.inputs else None
} for run in runs])
analysis = {
"total_cost": df['total_cost'].sum(),
"total_requests": len(df),
"avg_cost_per_request": df['total_cost'].mean(),
"cost_by_model": df.groupby('model')['total_cost'].agg(['sum', 'count', 'mean']).to_dict(),
"cost_by_run_type": df.groupby('run_type')['total_cost'].agg(['sum', 'count', 'mean']).to_dict(),
"daily_costs": df.groupby(df['timestamp'].dt.date)['total_cost'].sum().to_dict(),
"high_cost_requests": df[df['total_cost'] > df['total_cost'].quantile(0.95)].to_dict('records'),
"token_efficiency": {
"avg_tokens_per_request": df['total_tokens'].mean(),
"cost_per_token": df['total_cost'].sum() / df['total_tokens'].sum() if df['total_tokens'].sum() > 0 else 0,
"prompt_to_completion_ratio": df['prompt_tokens'].sum() / df['completion_tokens'].sum() if df['completion_tokens'].sum() > 0 else 0
}
}
return analysis
def _generate_cost_recommendations(self, analysis: dict) -> list:
"""Generate specific cost optimization recommendations"""
recommendations = []
# Model optimization recommendations
model_costs = analysis["cost_by_model"]["sum"]
most_expensive_model = max(model_costs, key=model_costs.get)
if "gpt-4" in most_expensive_model and model_costs[most_expensive_model] > analysis["total_cost"] * 0.6:
recommendations.append({
"type": "model_optimization",
"priority": "high",
"description": f"Consider using GPT-3.5-turbo for simpler tasks. {most_expensive_model} accounts for {model_costs[most_expensive_model]/analysis['total_cost']:.1%} of total costs.",
"potential_savings": model_costs[most_expensive_model] * 0.7,
"implementation": "Route simple queries to cheaper models using a classifier"
})
# Token efficiency recommendations
token_stats = analysis["token_efficiency"]
if token_stats["prompt_to_completion_ratio"] > 5:
recommendations.append({
"type": "prompt_optimization",
"priority": "medium",
"description": f"High prompt-to-completion ratio ({token_stats['prompt_to_completion_ratio']:.1f}:1) suggests prompts may be too long",
"potential_savings": analysis["total_cost"] * 0.2,
"implementation": "Optimize prompts to reduce length while maintaining quality"
})
# Request pattern optimization
if analysis["avg_cost_per_request"] > 0.10:
recommendations.append({
"type": "request_optimization",
"priority": "medium",
"description": f"High average cost per request (${analysis['avg_cost_per_request']:.3f})",
"potential_savings": analysis["total_cost"] * 0.15,
"implementation": "Implement caching for common queries and batch similar requests"
})
return recommendations
def implement_model_routing(self, query_complexity_threshold: float = 0.7) -> callable:
"""Implement intelligent model routing to optimize costs"""
@traceable(name="Cost-Optimized Model Router", run_type="chain")
def route_to_optimal_model(query: str, user_context: dict = None) -> dict:
"""Route queries to the most cost-effective model"""
complexity_score = self.assess_query_complexity(query)
if complexity_score < query_complexity_threshold:
model = "gpt-3.5-turbo"
max_tokens = 500
elif complexity_score < 0.9:
model = "gpt-4"
max_tokens = 1000
else:
model = "gpt-4-32k"
max_tokens = 2000
response = openai_client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": query}],
max_tokens=max_tokens,
temperature=0.7
)
return {
"response": response.choices[^0].message.content,
"model_used": model,
"complexity_score": complexity_score,
"estimated_cost": self.estimate_cost(response.usage, model),
"routing_decision": f"Routed to {model} based on complexity {complexity_score:.2f}"
}
return route_to_optimal_model
def assess_query_complexity(self, query: str) -> float:
"""Assess query complexity to determine optimal model"""
complexity_indicators = {
"length": len(query.split()) / 100,
"question_words": len([w for w in query.lower().split() if w in ["what", "how", "why", "when", "where", "which"]]) / 10,
"technical_terms": len([w for w in query.lower().split() if w in ["algorithm", "implementation", "architecture", "optimization"]]) / 5,
"reasoning_required": 1.0 if any(phrase in query.lower() for phrase in ["compare", "analyze", "explain", "evaluate"]) else 0.3
}
weights = {"length": 0.2, "question_words": 0.3, "technical_terms": 0.3, "reasoning_required": 0.4}
complexity = sum(min(score, 1.0) * weights[factor] for factor, score in complexity_indicators.items())
return min(complexity, 1.0)
def setup_cost_alerts(self, project_name: str, daily_budget: float = 100.0):
"""Set up intelligent cost alerts"""
alert_config = {
"name": f"Smart Cost Alert - {project_name}",
"conditions": [
{"metric": "daily_cost", "threshold": daily_budget * 0.8, "type": "warning"},
{"metric": "daily_cost", "threshold": daily_budget, "type": "critical"},
{"metric": "cost_per_request", "threshold": 0.15, "type": "optimization_opportunity"}
],
"actions": [
{"type": "webhook",
"url": "https://your-cost-management-system.com/alert",
"body": {
"project": project_name,
"alert_type": "{alert_type}",
"current_cost": "{current_value}",
"threshold": "{threshold}",
"recommendations": "{optimization_recommendations}"
}}
]
}
return alert_config
# Usage example
cost_analyzer = CostOptimizationAnalyzer(ls_client)
# Analyze costs and get recommendations
cost_report = cost_analyzer.analyze_cost_patterns("production_app", days=30)
print(f"Total 30-day cost: ${cost_report['total_cost']:.2f}")
print(f"Potential monthly savings: ${cost_report['potential_savings']:.2f}")
# Implement cost-optimized routing
optimized_router = cost_analyzer.implement_model_routing(complexity_threshold=0.6)
# Test the router
test_queries = [
"What is the weather today?", # Simple - should use GPT-3.5
"Explain the differences between REST and GraphQL APIs", # Medium - GPT-4
"Design a complete microservices architecture for an e-commerce platform" # Complex - GPT-4
]
for query in test_queries:
result = optimized_router(query)
print(f"Query: {query[:50]}...")
print(f"Model: {result['model_used']}, Complexity: {result['complexity_score']:.2f}")
print(f"Estimated cost: ${result['estimated_cost']:.4f}\n")
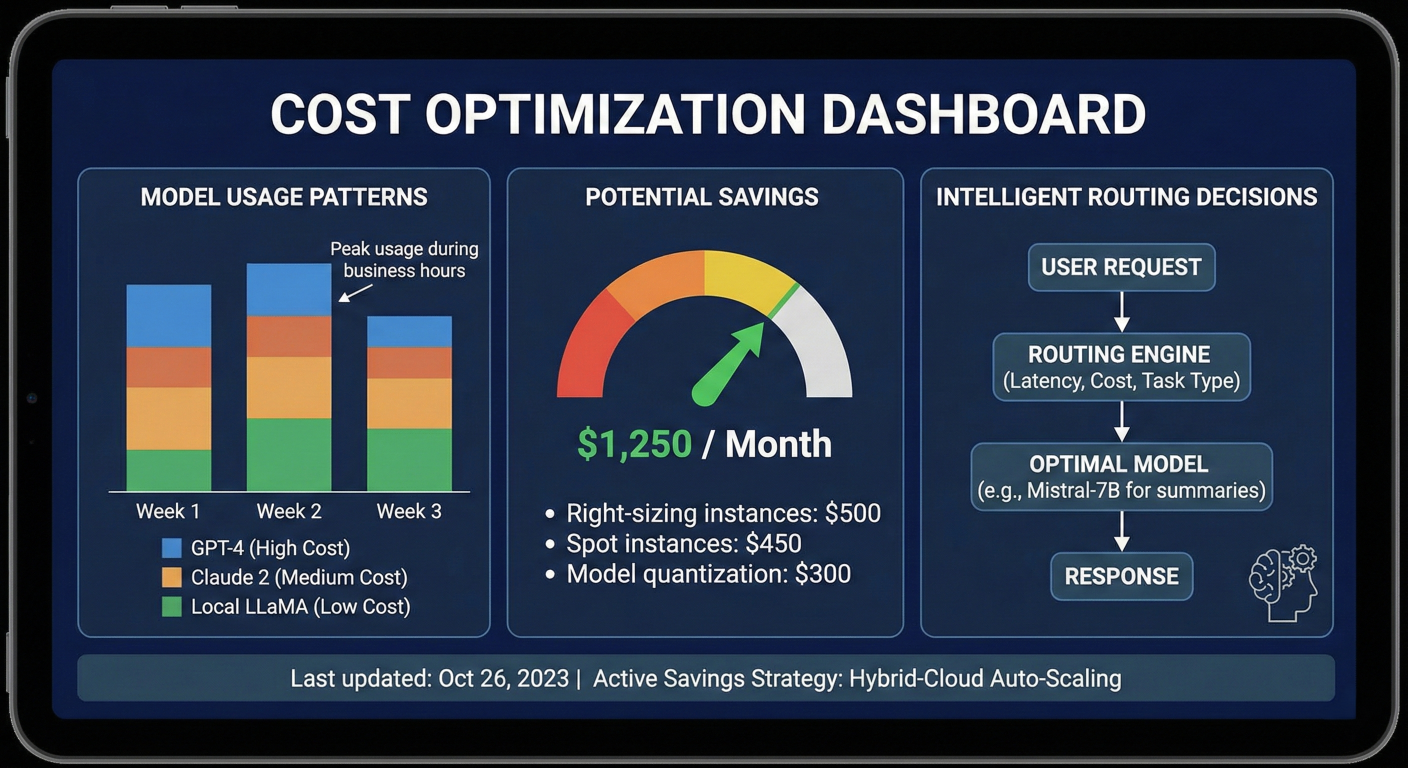
Cost optimization dashboard showing model usage patterns, potential savings, and intelligent routing decisions
As the AI landscape evolves rapidly, LangSmith helps you build adaptable and maintainable LLM applications.
# Framework for evaluation-driven development of LLM applications
class EvaluationDrivenWorkflow:
"""Framework for evaluation-driven development of LLM applications"""
def __init__(self, client: Client, base_project: str):
self.client = client
self.base_project = base_project
self.evaluation_history = []
def create_feature_branch_evaluation(self, feature_name: str, changes_description: str):
"""Create evaluation framework for new feature development"""
project_name = f"{'{'}self.base_project{'}'}_feature_{'{'}feature_name{'}'}"
# Define evaluation criteria specific to the feature
feature_evaluators = self.get_feature_evaluators(feature_name)
# Create baseline measurement
baseline_results = self.run_baseline_evaluation(project_name, feature_evaluators)
return {
"project_name": project_name,
"feature_name": feature_name,
"baseline_results": baseline_results,
"evaluators": feature_evaluators,
"changes_description": changes_description
}
def continuous_evaluation_loop(self, project_name: str, evaluation_interval: int = 3600):
"""Run continuous evaluation loop for production monitoring"""
import time
import threading
def evaluation_worker():
while True:
try:
# Run evaluation on recent data
results = self.run_production_evaluation(project_name)
# Check for regressions
regressions = self.detect_regressions(results)
if regressions:
self.trigger_regression_alert(project_name, regressions)
# Store results for trending
self.store_evaluation_results(project_name, results)
except Exception as e:
print(f"Evaluation loop error: {e}")
time.sleep(evaluation_interval)
# Start evaluation worker thread
worker_thread = threading.Thread(target=evaluation_worker, daemon=True)
worker_thread.start()
return worker_thread
def automated_regression_testing(self, old_version: str, new_version: str) -> dict:
"""Automated regression testing between versions"""
# Run parallel evaluations
old_results = evaluate(
target=self.get_model_version(old_version),
data="regression_test_dataset",
evaluators=[Correctness(), Helpfulness(), Safety()],
experiment_prefix=f"regression_test_{'{'}old_version{'}'}"
)
new_results = evaluate(
target=self.get_model_version(new_version),
data="regression_test_dataset",
evaluators=[Correctness(), Helpfulness(), Safety()],
experiment_prefix=f"regression_test_{'{'}new_version{'}'}"
)
# Compare results
comparison = self.compare_evaluation_results(old_results, new_results)
return {
"old_version": old_version,
"new_version": new_version,
"comparison": comparison,
"regression_detected": comparison["overall_change"] < -0.05,
"recommendation": self.get_deployment_recommendation(comparison)
}
# Advanced monitoring and alerting system
class IntelligentMonitoring:
"""Intelligent monitoring system that learns from patterns"""
def __init__(self, client: Client):
self.client = client
self.anomaly_detector = self.setup_anomaly_detection()
def setup_anomaly_detection(self):
"""Set up ML-based anomaly detection for LLM metrics"""
from sklearn.ensemble import IsolationForest
import numpy as np
# This would be trained on historical data
detector = IsolationForest(contamination=0.1, random_state=42)
return detector
def detect_production_anomalies(self, project_name: str) -> dict:
"""Detect anomalies in production LLM behavior"""
# Get recent production data
recent_runs = list(self.client.list_runs(
project_name=project_name,
start_time=(datetime.now() - timedelta(hours=24)).isoformat(),
limit=1000
))
if len(recent_runs) < 50:
return {"status": "insufficient_data", "message": "Need more data for anomaly detection"}
# Extract features for anomaly detection
features = self.extract_anomaly_features(recent_runs)
# Detect anomalies
anomaly_scores = self.anomaly_detector.decision_function(features)
anomalies = np.where(anomaly_scores < -0.1)[0]
if len(anomalies) > 0:
anomalous_runs = [recent_runs[i] for i in anomalies]
return {
"status": "anomalies_detected",
"anomaly_count": len(anomalies),
"total_runs": len(recent_runs),
"anomaly_percentage": len(anomalies) / len(recent_runs),
"anomalous_runs": [run.id for run in anomalous_runs],
"patterns": self.analyze_anomaly_patterns(anomalous_runs)
}
return {"status": "normal", "message": "No anomalies detected"}
def extract_anomaly_features(self, runs: list) -> np.ndarray:
"""Extract features for anomaly detection"""
features = []
for run in runs:
feature_vector = [
run.total_tokens or 0,
run.total_cost or 0,
(run.end_time - run.start_time).total_seconds() if run.end_time and run.start_time else 0,
len(run.inputs.get("messages", [])) if run.inputs else 0,
len(str(run.outputs)) if run.outputs else 0,
1 if run.error else 0,
len(run.events or [])
]
features.append(feature_vector)
return np.array(features)
def analyze_anomaly_patterns(self, anomalous_runs: list) -> dict:
"""Analyze patterns in anomalous runs"""
patterns = {
"high_cost_runs": len([r for r in anomalous_runs if (r.total_cost or 0) > 1.0]),
"high_latency_runs": len([r for r in anomalous_runs if r.end_time and r.start_time and (r.end_time - r.start_time).total_seconds() > 30]),
"error_runs": len([r for r in anomalous_runs if r.error]),
"common_inputs": self.find_common_input_patterns(anomalous_runs),
"time_patterns": self.analyze_temporal_patterns(anomalous_runs)
}
return patterns
# Integration with external systems
class ExternalIntegrations:
"""Integrate LangSmith with external systems and tools"""
def __init__(self, client: Client):
self.client = client
def setup_datadog_integration(self, datadog_api_key: 'str', datadog_app_key: 'str'):
"""Send LangSmith metrics to Datadog"""
from datadog import initialize, api
initialize(api_key=datadog_api_key, app_key=datadog_app_key)
def send_metrics_to_datadog(project_name: 'str'):
metrics = self.get_project_metrics(project_name)
# Send custom metrics
api.Metric.send([
{
'metric': 'langsmith.requests.total',
'points': [(time.time(), metrics['total_requests'])],
'tags': [f'project:{project_name}']
},
{
'metric': 'langsmith.cost.total',
'points': [(time.time(), metrics['total_cost'])],
'tags': [f'project:{project_name}']
},
{
'metric': 'langsmith.latency.p95',
'points': [(time.time(), metrics['p95_latency'])],
'tags': [f'project:{project_name}']
}
])
return send_metrics_to_datadog
def setup_slack_notifications(self, webhook_url: 'str'):
"""Enhanced Slack notifications with rich formatting"""
import requests
def send_evaluation_report(results: dict, project_name: 'str'):
"""Send formatted evaluation report to Slack"""
color = "good" if results.get("overall_score", 0) > 0.8 else "warning" if results.get("overall_score", 0) > 0.6 else "danger"
payload = {
"attachments": [
{
"color": color,
"title": f"📊 LangSmith Evaluation Report - {project_name}",
"fields": [
{
"title": "Overall Score",
"value": f"{results.get('overall_score', 0):.2%}",
"short": True
},
{
"title": "Tests Run",
"value": str(results.get('total_tests', 0)),
"short": True
},
{
"title": "Accuracy",
"value": f"{results.get('accuracy', 0):.2%}",
"short": True
},
{
"title": "Helpfulness",
"value": f"{results.get('helpfulness', 0):.2%}",
"short": True
}
],
"footer": "LangSmith Evaluation System",
"ts": int(time.time())
}
]
}
response = requests.post(webhook_url, json=payload)
return response.status_code == 200
return send_evaluation_report
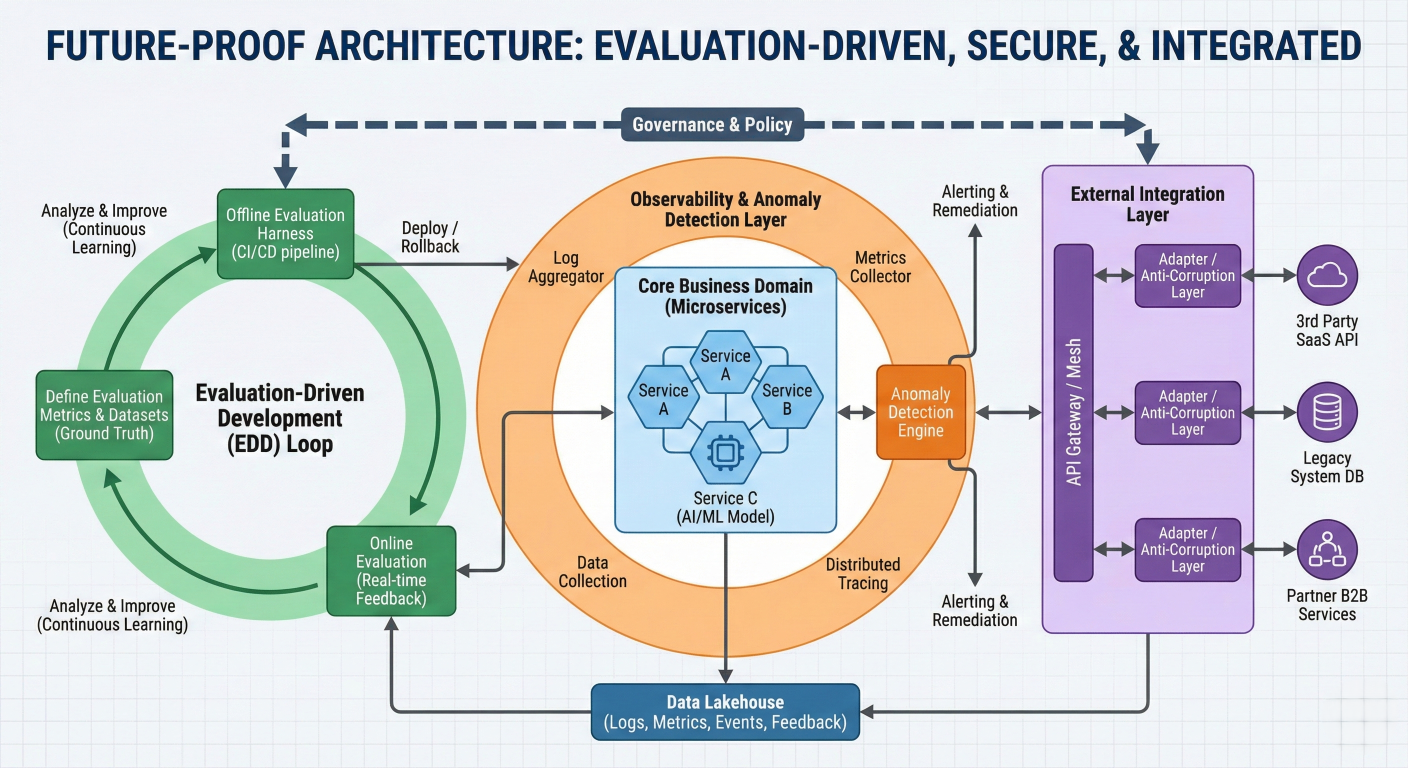
Future-proofing architecture showing evaluation-driven development, anomaly detection, and external integrations
Based on real-world deployments and user experiences, here are the most important practices for LangSmith success.
# Performance optimization strategies
class LangSmithOptimizer:
def __init__(self, client: Client):
self.client = client
def optimize_tracing_overhead(self):
"""Minimize tracing overhead in high-volume applications"""
# Strategy 1: Intelligent sampling
import os
import random
def should_trace_request(user_id: str, request_type: str) -> bool:
"""Intelligent sampling based on user and request characteristics"""
# Always trace for specific users (VIP customers, internal testing)
vip_users = os.environ.get("VIP_USERS", "").split(",")
if user_id in vip_users:
return True
# Higher sampling rate for errors and edge cases
if request_type in ["error_recovery", "complex_query"]:
return random.random() < 0.5 # 50% sampling
# Lower sampling for routine operations
base_sampling_rate = float(os.environ.get("LANGSMITH_SAMPLING_RATE", "0.1"))
return random.random() < base_sampling_rate
return should_trace_request
def optimize_data_retention(self, project_name: str):
"""Optimize data retention and storage costs"""
retention_policy = {
"production_traces": {
"high_value": 365, # Keep high-value traces for 1 year
"standard": 90, # Keep standard traces for 3 months
"low_value": 30 # Keep low-value traces for 1 month
},
"evaluation_results": 365, # Keep evaluation results for 1 year
"feedback_data": 730 # Keep feedback data for 2 years
}
# Implement retention policy
cutoff_date = datetime.now() - timedelta(days=retention_policy["production_traces"]["low_value"])
# Archive or delete old low-value traces
old_runs = list(self.client.list_runs(
project_name=project_name,
end_time=cutoff_date.isoformat(),
limit=10000
))
low_value_runs = [
run for run in old_runs
if self.classify_trace_value(run) == "low_value"
]
return {
"total_old_runs": len(old_runs),
"low_value_runs": len(low_value_runs),
"retention_policy": retention_policy,
"action": f"Archive {len(low_value_runs)} low-value traces"
}
def classify_trace_value(self, run) -> str:
"""Classify trace value for retention decisions"""
# High value: traces with errors, high costs, or user feedback
if run.error or (run.total_cost and run.total_cost > 0.5):
return "high_value"
if hasattr(run, 'feedback_stats') and run.feedback_stats:
return "high_value"
# Standard value: regular successful traces
if run.status == "success":
return "standard"
# Low value: simple, successful traces with no special characteristics
return "low_value"
### **Security and Privacy Best Practices**
def implement_data_privacy_controls():
"""Implement comprehensive data privacy and security controls"""
from cryptography.fernet import Fernet
import hashlib
import re
class PrivacyAwareLangSmith:
def __init__(self, client: Client, encryption_key: bytes):
self.client = client
self.cipher = Fernet(encryption_key)
self.pii_patterns = {
'email': r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b',
'phone': r'\b\d{3}-\d{3}-\d{4}\b',
'ssn': r'\b\d{3}-\d{2}-\d{4}\b',
'credit_card': r'\b\d{4}[\s-]?\d{4}[\s-]?\d{4}[\s-]?\d{4}\b'
}
def sanitize_data(self, data: dict, context: "trace" = "trace") -> dict:
"""Sanitize sensitive data before sending to LangSmith"""
sanitized = {}
for key, value in data.items():
if isinstance(value, str):
sanitized[key] = self.redact_pii(value)
elif isinstance(value, dict):
sanitized[key] = self.sanitize_data(value, context)
else:
sanitized[key] = value
return sanitized
def redact_pii(self, text: str) -> str:
"""Redact PII from text while preserving utility"""
redacted_text = text
for pii_type, pattern in self.pii_patterns.items():
redacted_text = re.sub(pattern, f"[REDACTED_{'{'}pii_type.upper(){'}'}]", redacted_text)
return redacted_text
def secure_trace_creation(self, inputs: dict, outputs: dict, metadata: dict):
"""Create traces with privacy controls"""
safe_inputs = self.sanitize_data(inputs, "input")
safe_outputs = self.sanitize_data(outputs, "output")
privacy_metadata = {
**metadata,
"privacy_applied": True,
"sanitization_timestamp": datetime.now().isoformat(),
"data_classification": self.classify_data_sensitivity(inputs)
}
return {
"inputs": safe_inputs,
"outputs": safe_outputs,
"metadata": privacy_metadata
}
def classify_data_sensitivity(self, data: dict) -> str:
"""Classify data sensitivity level"""
data_str = str(data).lower()
if any(pattern.search(data_str) for pattern in self.pii_patterns.values()):
return "high_sensitivity"
elif any(word in data_str for word in ["confidential", "private", "internal"]):
return "medium_sensitivity"
else:
return "low_sensitivity"
def audit_data_access(self, user_id: str, action: str, resource_id: str):
"""Audit data access for compliance"""
audit_entry = {
"timestamp": datetime.now().isoformat(),
"user_id": hashlib.sha256(user_id.encode()).hexdigest(), # Hash user ID
"action": action,
"resource_id": resource_id,
"ip_address": "[REDACTED]", # Don't log IP addresses
"user_agent": "[REDACTED]" # Don't log user agents
}
# Log to secure audit system
# self.log_to_audit_system(audit_entry)
return audit_entry
return PrivacyAwareLangSmith
### **Team Collaboration and Workflow Optimization**
def setup_team_workflows():
"""Set up optimized team workflows for LangSmith"""
class TeamWorkflowManager:
def __init__(self, client: Client):
self.client = client
def setup_role_based_access(self):
"""Define role-based access patterns"""
roles = {
"data_scientist": {
"permissions": ["read_traces", "create_datasets", "run_evaluations"],
"projects": ["research_*", "experiments_*"],
"restrictions": ["no_production_access"]
},
"ml_engineer": {
"permissions": ["read_traces", "create_prompts", "run_evaluations", "deploy_models"],
"projects": ["staging_*", "development_*"],
"restrictions": ["limited_production_access"]
},
"product_manager": {
"permissions": ["read_traces", "view_dashboards", "create_annotation_queues"],
"projects": ["*"],
"restrictions": ["no_code_access"]
},
"admin": {
"permissions": ["all"],
"projects": ["*"],
"restrictions": []
}
}
return roles
def create_review_workflow(self, project_name: str):
"""Create a code review workflow for LLM changes"""
workflow = {
"stages": [
{
"name": "development",
"requirements": ["unit_tests_pass", "basic_evaluation_pass"],
"reviewers": ["ml_engineer"],
"auto_promotion": False
},
...
],
"evaluation_gates": {
"development": {"accuracy": 0.7, "safety": 0.9},
...
}
}
return workflow
def automated_quality_gates(self, project_name: str, target_stage: str):
"""Implement automated quality gates"""
def quality_gate_check(evaluation_results: dict, stage: str) -> dict:
"""Check if evaluation results meet quality gate requirements"""
stage_requirements = {
"staging": {...},
"production": {...}
}
requirements = stage_requirements.get(stage, {})
passed_checks = []
failed_checks = []
for metric, threshold in requirements.items():
actual_value = evaluation_results.get(metric, 0)
if actual_value >= threshold:
passed_checks.append({...})
else:
failed_checks.append({...})
return {
"stage": stage,
"overall_status": "passed" if not failed_checks else "failed",
"passed_checks": passed_checks,
"failed_checks": failed_checks,
"pass_rate": len(passed_checks) / (len(passed_checks) + len(failed_checks)) if (passed_checks or failed_checks) else 0
}
return quality_gate_check
return TeamWorkflowManager
# Common pitfalls and how to avoid them
def avoid_common_pitfalls():
"""Guide for avoiding common LangSmith pitfalls"""
pitfalls_and_solutions = {
"evaluation_dataset_quality": {
"problem": "Low-quality evaluation datasets lead to misleading results",
"solution": "Implement dataset review processes, use schema validation, and regularly audit dataset quality",
"code_example": """
# Good: Comprehensive dataset validation
def validate_dataset_quality(dataset_name: str) -> dict:
examples = list(client.list_examples(dataset_name=dataset_name))
quality_checks = {
"sufficient_size": len(examples) >= 50,
"input_diversity": len(set(str(ex.inputs) for ex in examples)) / len(examples) > 0.8,
"output_quality": all(len(str(ex.outputs)) > 10 for ex in examples),
"balanced_difficulty": check_difficulty_distribution(examples)
}
return quality_checks
"""
},
"over_reliance_on_automated_evaluation": {
"problem": "Relying only on automated evaluators without human validation",
"solution": "Combine automated evaluators with human feedback and regular spot checks",
"code_example": """
# Good: Hybrid evaluation approach
def comprehensive_evaluation(app_function, dataset_name):
# Automated evaluation
auto_results = evaluate(
app_function,
data=dataset_name,
evaluators=[Correctness(), Helpfulness()]
)
# Human evaluation on sample
sample_for_human_review = create_annotation_queue(
dataset_name,
sample_size=20,
criteria=["accuracy", "tone", "completeness"]
)
return {"automated": auto_results, "human_review_queue": sample_for_human_review}
"""
},
"insufficient_error_handling": {
"problem": "Not properly handling LangSmith API errors and failures",
"solution": "Implement robust error handling and fallback mechanisms",
"code_example": """
# Good: Robust error handling
@traceable(name="Resilient LLM Call")
def resilient_llm_call(prompt: str, max_retries: int = 3):
for attempt in range(max_retries):
try:
response = llm.invoke(prompt)
return {"response": response, "attempt": attempt + 1}
except Exception as e:
if attempt == max_retries - 1:
return {"error": str(e), "attempts": max_retries}
time.sleep(2 ** attempt) # Exponential backoff
"""
}
}
return pitfalls_and_solutions
Team collaboration interface showing role-based access, review workflows, and quality gates
LangSmith represents a paradigm shift in how we build, test, and maintain LLM applications. By providing comprehensive observability, sophisticated evaluation frameworks, and productionready monitoring capabilities, it transforms the chaotic process of LLM development into a systematic, data-driven discipline.
Observability is Non-Negotiable: In the world of non-deterministic AI systems, you need complete visibility into what your models are doing. LangSmith's tracing capabilities provide the deep insights necessary to debug, optimize, and maintain complex LLM applications.
Evaluation-Driven Development: Traditional testing approaches don't work for LLM applications. LangSmith's evaluation framework, combining automated assessments with human feedback, enables you to build reliable AI systems that improve over time.
Production Monitoring Saves Businesses: The difference between a successful LLM application and a failed one often comes down to production monitoring. LangSmith's alerting and dashboard capabilities help you catch issues before they impact users.
Cost Control is Critical: LLM applications can become expensive quickly. LangSmith's cost tracking and optimization features help you build sustainable, profitable AI applications.
Team Collaboration Accelerates Innovation: LangSmith's collaboration features, from prompt versioning to annotation queues, enable teams to work together effectively on AI projects.
Future-Proofing Through Standards: By building on LangSmith's framework-agnostic platform, you're investing in tools and practices that will adapt as the AI landscape evolves.
Ready to transform your LLM development process? Here's your action plan:
The future of AI applications belongs to those who can build reliable, observable, and maintainable systems. LangSmith provides the foundation for that future.
Ready to build production-ready LLM applications? Start with LangSmith's free tier today and experience the difference that proper observability and evaluation make. Your users – and your development team – will thank you for taking the time to build AI applications the right way
Don't let your LLM applications remain black boxes. Make them observable, testable, and reliable with LangSmith.
Take action today: Transform your LLM development workflow with LangSmith. Start building applications that are not just impressive demos, but production-ready systems that deliver real value to your users and business.

{{AUTHOR}}
 Launch your Graphy
Launch your Graphy