There are no items in your cart
Add More
Add More
| Item Details | Price | ||
|---|---|---|---|

The proliferation of Large Language Models (LLMs) has fundamentally altered the technological landscape, presenting enterprises with unprecedented opportunities for automation and innovation. However, transitioning from isolated proof-of-concept (POC) models to full-fledged, production-grade generative AI applications has revealed significant bottlenecks. These challenges typically revolve around model sprawl (the difficulty of standardizing deployment across various models and teams), inconsistent security practices, inefficient management of costly GPU compute resources, and a general lack of a unified governance framework necessary for compliance and auditing.
Organizations frequently find themselves navigating a fragmented ecosystem. Different teams may utilize different foundation models (FMs)—some proprietary (like the GPT family), others open-source (like Mistral or Llama)—each requiring separate infrastructure, deployment standards, and access controls. This decentralized approach creates substantial overhead, complicates security enforcement, and makes it nearly impossible to ensure consistent governance and cost efficiency across the organization. The enterprise requires a standardized platform capable of supporting rapid innovation while imposing strict corporate controls.
Azure AI Foundry is Microsoft’s strategic solution to this enterprise complexity, established as a unified platform specifically engineered for developers to build, customize, evaluate, and manage generative AI applications and intelligent agents at scale. The platform simplifies otherwise complex workflows across model deployment, agent orchestration, and operational observability, empowering organizations to accelerate the journey from prototype to production with confidence.
The core technical definition of the Foundry is its role as a unified control plane. It delivers streamlined management capabilities through unified Role-based access control (RBAC), networking configurations, and organizational policies, all consolidated under one Azure resource provider namespace. This architectural decision ensures that whether a developer is exploring a new model, building a prototype, or deploying a high-volume service, the underlying infrastructure adheres consistently to enterprise-grade security and compliance standards.
Key functionality provided by the Foundry includes supporting the exploration, building, testing, and deployment of cutting-edge AI tools and models, intrinsically grounded in responsible AI practices. Crucially, it facilitates collaboration for the full application development lifecycle and provides a consistent API contract that works seamlessly across various model providers, eliminating integration hurdles typically associated with mixing proprietary and open-source models.
The strategic mission of Azure AI Foundry centers on two pillars: scaling and governance.
The unification of governance under a single Azure resource provider namespace is arguably the most significant strategic advantage for large organizations. By centralizing all foundational model access, compute allocation, networking configuration, and governance policies under a single resource ID (Microsoft.CognitiveServices/account), the Foundry drastically simplifies critical corporate functions. This singular management point facilitates automated cost allocation, streamlines compliance auditing against internal and external policies, and ensures that security patches and configurations are applied uniformly across all GenAI assets, shifting generative AI from a chaotic exploration environment to a budgeted, governed, and verifiable corporate asset.
The structured architecture of Azure AI Foundry is defined by a hierarchy of resources designed to balance centralized control with decentralized developer agility.
Within a project, agents share essential operational storage, including file storage, conversation history (thread storage), and search indexes. 1 Crucially, for organizations that require absolute control over their sensitive information, the structure allows developers to bring their own Azure resources into a project, ensuring strict compliance and control over data that must remain within the organizational network perimeter.
The robustness of Azure AI Foundry lies in its integrated architecture, which strategically combines several core Azure services to deliver a secure, scalable, and high-performance environment for GenAI.
The Foundry is a composite service that coordinates capabilities across a layered stack of three fundamental Azure resource providers:
The architecture successfully unifies these traditionally separate domains—model access, custom development, and data retrieval—under a singular management framework. This structured integration simplifies the entire LLMOps workflow, ensuring that the necessary components for customization (AML compute), grounding (Search indexes), and serving (Cognitive Services API endpoints) are all managed consistently. This tight coupling makes traceability straightforward and guarantees that security and policy configurations established at the Hub level are uniformly enforced down to the lowest compute and data layers, offering a verifiable compliance chain.
Azure AI Foundry applies a flexible compute architecture essential for supporting diverse model access and workload execution scenarios.
Security and data isolation are paramount for enterprise AI adoption. The Foundry incorporates advanced networking and storage features to meet stringent compliance demands.
The strategic structure described above illustrates how a singular control layer governs diverse underlying services, ensuring uniformity and security across the entire GenAI lifecycle
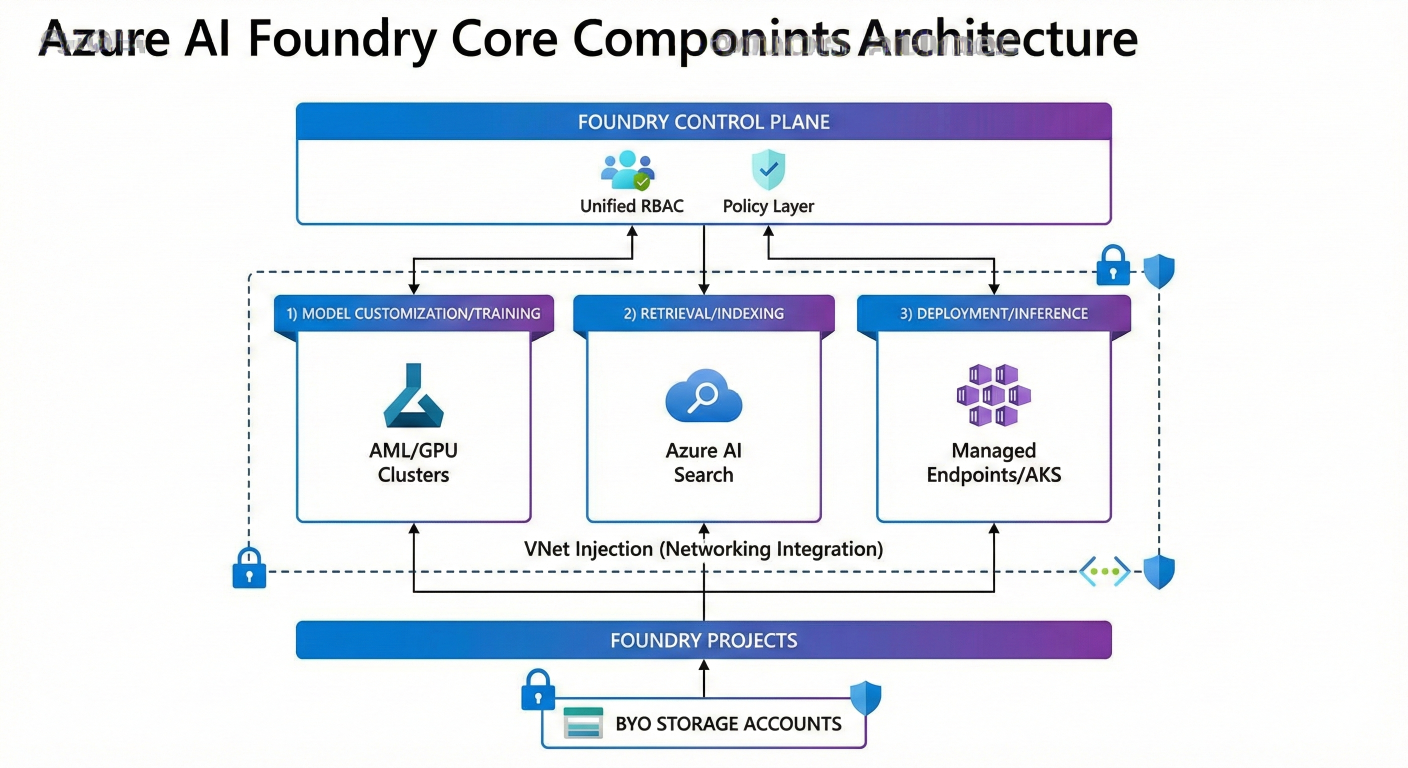
The diagram show the Foundry Control Plane (unified RBAC/Policy layer) at the top, integrating downward with three key service layers: 1) Model Customization/Training (AML/GPU Clusters), 2) Retrieval/Indexing (Azure AI Search), and 3) Deployment/Inference (Managed Endpoints/AKS). Show the secure boundary features: VNet Injection (Networking Integration) and BYO Storage accounts attached to the Foundry Projects
The following table summarizes the integrated architecture:
Table 1: Azure AI Foundry Core Components and Integrated Services
| Foundry Component (Layer) |
Underlying Azure Resource Type/Provider |
Primary Technical Function |
| Azure AI Foundry Resource (Hub) | Microsoft.CognitiveService s/account (Kind: AIServices) | Unified Policy, RBAC, Agent, and Model Management Plane. Access to Azure OpenAI, Speech, Vision, and Language services. |
| Project and Compute Execution | Managed Container Compute / Azure Machine Learning | Executes Agents, Evaluations, Batch Jobs, Fine-Tuning, and model inference workloads. Provides secure workload execution. |
| Model and Asset Management | Azure AI Hub / Azure Machine Learning Workspace | Model Catalog, Model Registry, Experiment Tracking (MLflow integration), and lifecycle management. 4 |
| Knowledge Retrieval | Microsoft.Search / Azure AI Search | Supports RAG implementation by providing vector indexing and data grounding capabilities. 4 |
| Data Storage |
Microsoft-Managed Storage or Bring Your Own Storage (BYOS) |
Securely manages model training data, outputs, and Agent state (file storage, conversation history). |
Enterprise adoption of generative AI necessitates a robust operational framework—LLMOps—that manages models and applications throughout their entire lifespan. Azure AI Foundry structures this process around an iterative four-loop framework, focusing on continuous improvement, security, and governance.
Retrieval-Augmented Generation (RAG) is the preferred and often most practical method for enabling an LLM to reason over proprietary, enterprise-specific data. RAG works by injecting relevant information retrieved from internal data sources (documents, structured databases) directly into the model’s prompt based on a user’s query.
This process allows the developer to "ground" their solution, providing the LLM with contextually accurate information. The advantages are compelling: RAG facilitates highly customized solutions, maintains factual relevance, and optimizes costs compared to constant retraining. Furthermore, RAG allows for continuous updates to the underlying knowledge base without the resource-intensive process of model fine-tuning. Azure AI Foundry’s tight integration with Azure AI Search provides the high-performance vector indexing and retrieval foundation necessary for robust RAG pipelines.
Azure AI Prompt Flow serves as the pivotal orchestration and experimentation tool within the Foundry, especially central to the "Building and Augmenting" loop. 5 It is designed to streamline the entire LLM application development process.
Prompt Flow offers systematic experimentation tools that enable developers to craft and compare the performance of multiple prompt variants against sample data. 5 It integrates seamlessly with popular frameworks like LangChain and Semantic Kernel and uses reusable Python tools for complex data processing. 5 The platform also supports the dynamic and conditional use of multiple LLMs within a single workflow, which can significantly optimize task execution and manage token usage costs.
Continuous evaluation is an essential element of the LLMOps loop, ensuring that the AI systems do not become outdated due to changing data or user behavior over time. 3 Unlike traditional machine learning where accuracy metrics suffice, LLMs require specialized quality assessments.
Azure AI Foundry provides robust, built-in monitoring tools that track safety and quality metrics in production. Developers can rapidly configure monitoring for key metrics such as groundedness (verifying that the LLM's output is supported by the injected source data), relevance, coherence, fluency, and similarity.
The results of this continuous evaluation phase serve as the critical feedback mechanism that dictates the next operational step. If evaluation shows low factual accuracy (poor groundedness), the engineer must adjust the RAG retrieval mechanism or the quality of the data source. If, however, evaluation reveals consistent issues with structure, style, or adherence to complex instructions (low coherence or specific format failures), this signals a need for deeper model modification, compelling the team to move towards fine-tuning. 5 The metrics provided by the Foundry are, therefore, actionable drivers for LLMOps, directly guiding the choice between prompt engineering, RAG refinement, or specialized fine-tuning techniques.
For enterprise applications that require highly specialized outputs, consistent tone, or domain-specific knowledge, basic prompt engineering and RAG alone may be insufficient. Azure AI Foundry provides the infrastructure to execute advanced model customization.
A best practice dictates that users should begin their optimization efforts with prompt engineering and RAG augmentation due to their lower cost and faster iteration cycles. 5 Fine-tuning becomes necessary when a more fundamental shift in the model's behavior is required 5 :
1. Output Accuracy: When performance on a specific task consistently falls short of desired thresholds, despite optimal RAG setup.
2. System Nature Alteration: When the use case requires the model to consistently produce structured outputs (e.g., specific JSON formats, complex code generation, or adherence to a specialized conversation flow).
3. Domain Specialization: To adapt a model specifically for technical jargon, terminology, and knowledge associated with specialized fields like finance, medicine, or law.
Azure AI Foundry supports a sophisticated array of fine-tuning techniques beyond simple retraining, enabling granular control over model behavior.
Table 2: Comparison of Fine-Tuning Techniques in Azure AI Foundry
| Technique |
Goal/Objective |
Best Use Case Scenarios | Supported Models (Example) |
| Supervised Fine-Tuning (SFT) | Teaching specific input-output pairs. Broadest applicability. | Domain specialization, consistent structured output (JSON/code), instruction following, language adaptation. 6 | Llama 3.1, GPT-4o, Mistral Large. 6 |
| Direct Preference Optimization (DPO) | Aligning model output with human preferences/safety standards. | Refining tone and style, improving helpfulness/harmle ssness, optimizing subjective response qualities. | GPT-4o, GPT-4.1-mini. 6 |
| Reinforcement Fine-Tuning (RFT) |
Optimizing based on a quantifiable reward signal for complex tasks. |
Objective domains like mathematics, physics, or complex reasoning where answers are unambiguously correct. | Applicable to advanced proprietary models (e.g., specific GPT versions). 6 |
The primary hurdle in fine-tuning massive LLMs is the extreme demand on GPU memory. Fully fine-tuning a model like Llama 7B can require upwards of 112GB of VRAM, making it impractical and cost-prohibitive for most enterprises. 7 Parameter-Efficient Fine-Tuning (PEFT) techniques mitigate this challenge.
# Simplified Python SDK configuration for a QLoRA job in Azure AI
from azure.ai.ml import automl, command
from azure.ai.ml.entities import AmlCompute
# Define the compute cluster optimized for VRAM efficiency
compute_target = AmlCompute(name="gpu-cluster-qlara", size="Standard_NC4as_T4_v3")
# Define the custom fine-tuning job using QLoRA parameters
job = command(
inputs=dict(
base_model_name="Mistral-7B-v0.1",
training_data_path="azureml:my_fine_tune_data:1",
peft_method="QLoRA", # Key parameter enabling efficient training
quantization_bits=4, # QLoRA specific 4-bit setting
epochs=3
),
# Reference the specialized fine-tuning component/script provided by Azure AI
code="./src/llm_finetune_script",
compute=compute_target,
environment="azureml:pytorch-gpu-latest:1"
)
# ml_client.jobs.create_or_update(job)
When dealing with foundation models far larger than 7 billion parameters—models containing hundreds of billions of parameters—the challenge extends beyond memory efficiency to the fundamental limits of single-node computing. Training or fine-tuning these models necessitates distributed processing across multiple GPUs and compute nodes.
The primary barrier is the memory required not just for the model weights, but also for the gradients and, critically, the optimizer states (e.g., momentum and variance parameters), which can double or triple the memory requirements.
DeepSpeed is natively supported within the Azure Machine Learning infrastructure that powers the Foundry (e.g., through the DeepSpeedTorchDistributor), allowing MLOps engineers to efficiently fine-tune models like Llama 2 7B by defining a configuration file (ds_config_zero2.json) that dictates the partitioning strategy
The journey is complete only when the customized model is operationalized and serving user requests reliably, quickly, and affordably. Azure AI Foundry streamlines this transition through managed endpoints and advanced optimization techniques.
Once a base or fine-tuned model (whether optimized using QLoRA or a standard SFT) is finalized and validated, it is registered in the Azure AI Hub Model Catalog. From the registry, the model is deployed to a managed online endpoint for high-performance inference.
Even after efficient training, the model's size and computational demand remain significant during inference, impacting latency and operational cost. Inference optimization techniques are deployed to ensure minimal latency and cost per transaction.
The combination of highly technical, complex optimization techniques (DeepSpeed for training, QLoRA for fine-tuning memory, and inference-time quantization) is deliberately abstracted behind a simplified developer interface: the Azure AI Foundry portal/SDK and the consistent serverless API endpoint.
This strategic abstraction is paramount for the MLOps engineer. It allows the enterprise to leverage state-of-the-art performance engineering—achieving high throughput and low latency—without the administrative burden of managing low-level GPU communication protocols or complex Kubernetes configurations. This dramatically accelerates the organization's time-to-production for specialized LLM applications.
Visualizing the LLMOps Pipeline
The flow from data ingestion to deployment and governance illustrates the cohesive nature of the Foundry platform
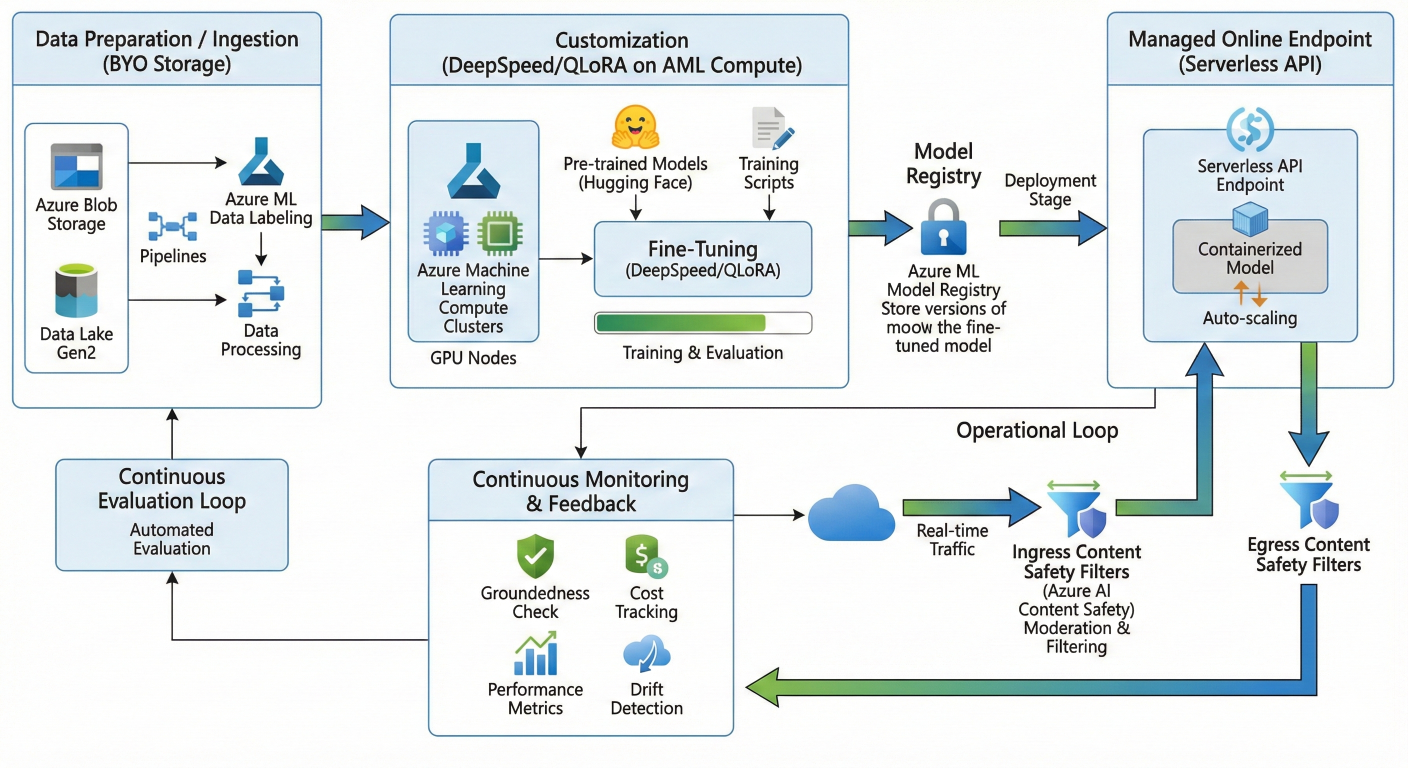
Start with Data Preparation/Ingestion (BYO Storage). Follow the path through Customization (DeepSpeed/QLoRA on AML Compute) to Model Registry. Show the Deployment stage to a Managed Online Endpoint (Serverless API). Conclude with the Operational Loop: Real-time traffic flowing through Content Safety Filters (Ingress/Egress) and continuous monitoring components (Groundedness/Cost Tracking) feeding back into the Evaluation loop
For generative AI to be sustainable and trusted within the enterprise, robust governance and security must be non-negotiable foundations, not optional add-ons. Azure AI Foundry incorporates security and Responsible AI principles throughout the application lifecycle.
Azure AI fundamentally integrates years of Microsoft's AI policy, research, and engineering expertise to help teams build solutions that are safe, secure, and reliable from the outset. Responsible AI is managed via the "Managing Loop" of the LLMOps lifecycle, establishing a structured framework for ongoing governance and security. AI governance provides clear guidelines, standards, and processes, significantly accelerating the secure adoption of AI within the organization
The generative nature of LLMs, especially those integrated into end-user-facing chatbots or complex agentic frameworks, inherently amplifies risk (e.g., generating harmful content or responding to malicious prompts).
Azure AI addresses this through powerful content safety systems, such as Azure AI Content Safety. These systems are designed to detect and mitigate misuse and the generation of unwanted content, actively filtering inputs (ingress) and outputs (egress) of the application. 5 Furthermore, models within the Azure OpenAI Service deployment are equipped with their own built-in content safety filters.
Continuous model monitoring is a critical pillar of LLMOps, essential for preventing AI systems from degrading or suffering performance drops due to shifting data distributions (model drift) or changes in user behavior.
The Azure Machine Learning model data collector automatically gathers production data. 5 Monitoring capabilities within Azure AI track and optimize various operational and quality metrics, providing granular understanding of:
For organizations in regulated industries, providing a clear audit trail and establishing data lineage is a critical compliance requirement. Administrators within Azure AI Foundry can enforce specific security configurations, such as utilizing private endpoints to restrict network access.
Crucially, the platform enables integration of Azure Machine Learning workspaces (which house Foundry assets) with Microsoft Purview. This integration automatically publishes metadata about the AI assets to the Purview Data Map. This capability ensures that the entire lifecycle of the LLM—from the initial training data used to the specifics of the fine-tuning configuration and where the final model is deployed—is documented and traceable.
Integrating the LLM lifecycle into the central corporate data map transforms the LLM from a potential compliance risk into an auditable, governed resource. This ensures that risk and compliance professionals can easily understand what data was consumed, how the model was extended (e.g., via QLoRA), and where it is currently being used, providing necessary evidence for regulatory compliance and supporting comprehensive Responsible AI initiatives.
The utility of the Foundry extends beyond general-purpose chat agents. For instance, it supports specialized tasks like Content Understanding, which is used to automatically extract structured information from complex enterprise files, including documents, images, audio, or video.
The workflow for this task involves defining a single-file task, specifying a field schema that dictates the information to be extracted or generated, and then building an analyzer. This analyzer is immediately exposed as a dedicated API endpoint that can be integrated into broader enterprise workflows, demonstrating the platform’s capacity for building specialized, operational AI services.
Azure AI Foundry represents a significant architectural evolution, moving generative AI capabilities out of siloed research environments and into the core of enterprise operations. Its value proposition is built upon unifying control, enabling advanced customization, and institutionalizing governance.
The platform’s strategic advantage stems from its ability to:
For organizations navigating the transition to production-grade generative AI, the choice of platform determines the speed of innovation and the viability of long-term compliance. Azure AI Foundry is designed to be the definitive launchpad for building sophisticated, intelligent agents and applications.
To begin capitalizing on these enterprise-grade capabilities, developers and architects are encouraged to start their journey today:

{{AUTHOR}}
 Launch your Graphy
Launch your Graphy