There are no items in your cart
Add More
Add More
| Item Details | Price | ||
|---|---|---|---|

In today's AI-driven landscape, the ability to deploy, monitor, and maintain machine learning models at scale isn't just an advantage—it's a necessity. Apache Airflow has emerged as the backbone of production MLOps, orchestrating everything from data ingestion to model deployment with unprecedented reliability and scale.
Whether you're building your first ML pipeline or scaling to hundreds of models in production, Airflow provides the robust orchestration layer that modern ML teams depend on. It's not just about scheduling tasks—it's about creating resilient, observable, and maintainable ML workflows that can adapt to the complex demands of production environments.
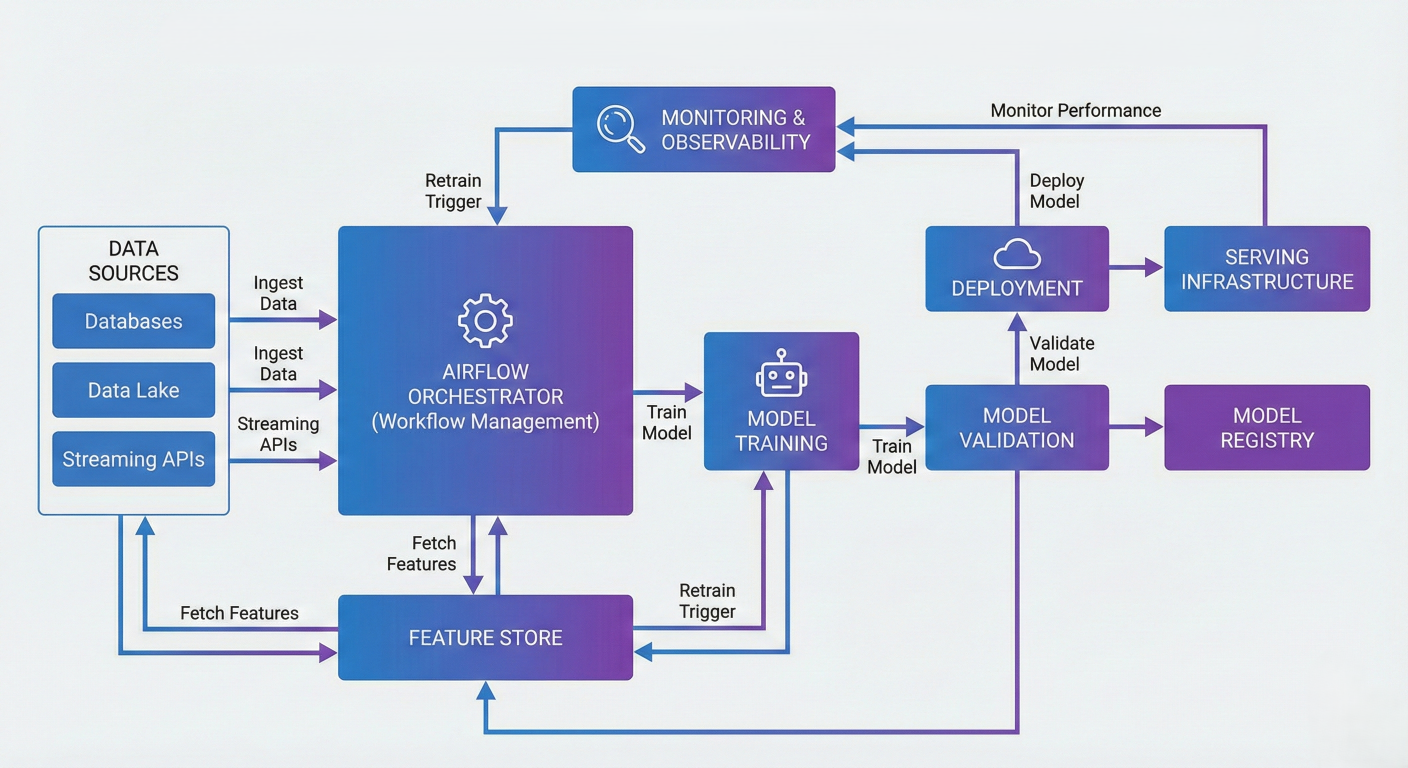
Detailed description about picture/Architecture/Diagram: High-level MLOps architecture showing Airflow as the central orchestrator connecting data sources, feature stores, model training, validation, deployment, and monitoring components. Include arrows showing data flow and dependencies between components.
Modern MLOps isn't just about training models—it's about creating sustainable, scalable systems that can adapt and evolve. Airflow sits at the heart of this ecosystem, orchestrating four critical MLOps components:
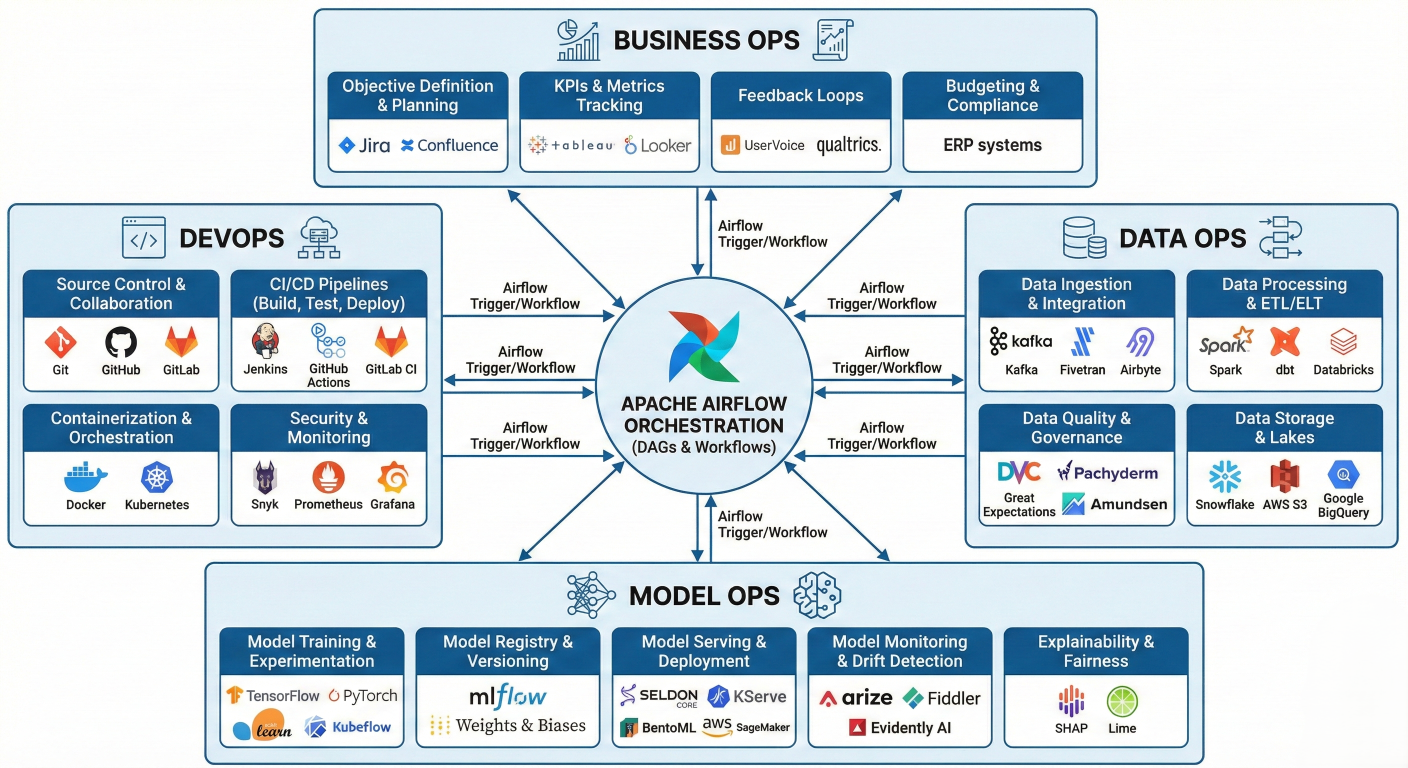
Detailed description about picture/Architecture/Diagram: Detailed MLOps components diagram showing the four pillars (BusinessOps, DevOps, DataOps, ModelOps) with Airflow orchestrating workflows across all components. Include specific tools and integrations for each pillar.
Building production ML pipelines requires more than just connecting a few tasks together. Let's explore the essential components that make Airflow ML pipelines robust, scalable, and maintainable.
The foundation of any ML pipelines is reliable, high-quality data. Airflow excels at orchestrating complex data validation workflows that catch issues before they propagate downstream.
from airflow.decorators import task
from airflow.providers.postgres.operators.postgres import PostgresOperator
from great_expectations_provider.operators.great_expectations import GreatExpectationsOperator
@task
def validate_data_quality(dataset_path: str):
"""Comprehensive data quality validation"""
import pandas as pd
from datetime import datetime
df = pd.read_parquet(dataset_path)
# Statistical validation
validation_results = {
'record_count': len(df),
'null_percentage': (df.isnull().sum() / len(df) * 100).to_dict(),
'duplicate_percentage': df.duplicated().sum() / len(df) * 100,
'data_freshness': (datetime.now() - df['timestamp'].max()).seconds / 3600,
'schema_version': df.columns.tolist()
}
# Quality thresholds
if validation_results['null_percentage']['critical_field'] > 5:
raise ValueError("Critical field has too many null values")
if validation_results['data_freshness'] > 24:
raise ValueError("Data is more than 24 hours old")
return validation_results
Modern ML requires sophisticated feature engineering that can adapt to changing data patterns. Airflow's dynamic task mapping enables parallel feature computation and automatic feature selection.
@task
def engineer_temporal_features(raw_data: dict):
"""Create sophisticated temporal features"""
import pandas as pd
df = pd.DataFrame(raw_data)
df['timestamp'] = pd.to_datetime(df['timestamp'])
# Rolling window features
df['sales_7d_avg'] = df.groupby('product_id')['sales'].transform(
lambda x: x.rolling(window=7, min_periods=1).mean()
)
# Trend features
df['sales_trend_7d'] = df.groupby('product_id')['sales'].transform(
lambda x: x.rolling(window=7).apply(lambda y: np.polyfit(range(len(y)), y, 1) if len(y) > 1 else 0)
)
# Seasonal patterns
df['day_of_week'] = df['timestamp'].dt.dayofweek
df['month'] = df['timestamp'].dt.month
df['is_weekend'] = df['day_of_week'].isin([5, 6])
return df.to_dict('records')
@task.expand(feature_set=['basic', 'advanced', 'experimental'])
def parallel_feature_engineering(raw_data: dict, feature_set: str):
"""Parallel feature engineering with different strategies"""
# Dynamic feature engineering based on strategy
if feature_set == 'experimental':
# Test new feature engineering approaches
return engineer_experimental_features(raw_data)
return engineer_standard_features(raw_data, feature_set)
Airflow orchestrates sophisticated model training workflows that include hyperparameter optimization, cross-validation, and automated model selection.
@task
def train_model_with_hyperopt(processed_data: dict):
"""Advanced model training with hyperparameter optimization"""
from sklearn.model_selection import RandomizedSearchCV, TimeSeriesSplit
from sklearn.ensemble import RandomForestClassifier
import mlflow
df = pd.DataFrame(processed_data)
X = df[feature_columns]
y = df['target']
# Time-aware validation for temporal data
cv_strategy = TimeSeriesSplit(n_splits=5)
# Hyperparameter search space
param_distributions = {
'n_estimators': [100, 200, 500],
'max_depth': [10, 20, 50, None],
'min_samples_split': [2, 5, 10],
'min_samples_leaf': [1, 2, 4],
'max_features': ['auto', 'sqrt', 'log2']
}
# MLflow experiment tracking
with mlflow.start_run():
# Randomized search with cross-validation
search = RandomizedSearchCV(
RandomForestClassifier(random_state=42),
param_distributions,
cv=cv_strategy,
n_iter=50,
scoring='f1_weighted',
n_jobs=-1,
random_state=42
)
search.fit(X, y)
# Log best model and parameters
mlflow.log_params(search.best_params_)
mlflow.log_metric("best_cv_score", search.best_score_)
mlflow.sklearn.log_model(search.best_estimator_, "model")
return {
'model_uri': mlflow.get_artifact_uri("model"),
'best_params': search.best_params_,
'cv_score': search.best_score_,
'training_timestamp': datetime.now().isoformat()
}
Before any model reaches production, it must pass rigorous validation checks that go beyond simple accuracy metrics
Airflow orchestrates sophisticated deployment patterns that minimize risk while maximizing observability.
Blue-green deployments: Zero-downtime model updates
Canary releases: Gradual rollout with automatic rollback
A/B testing: Compare model performance in production
Shadow deployments: Run new models alongside production without affecting users
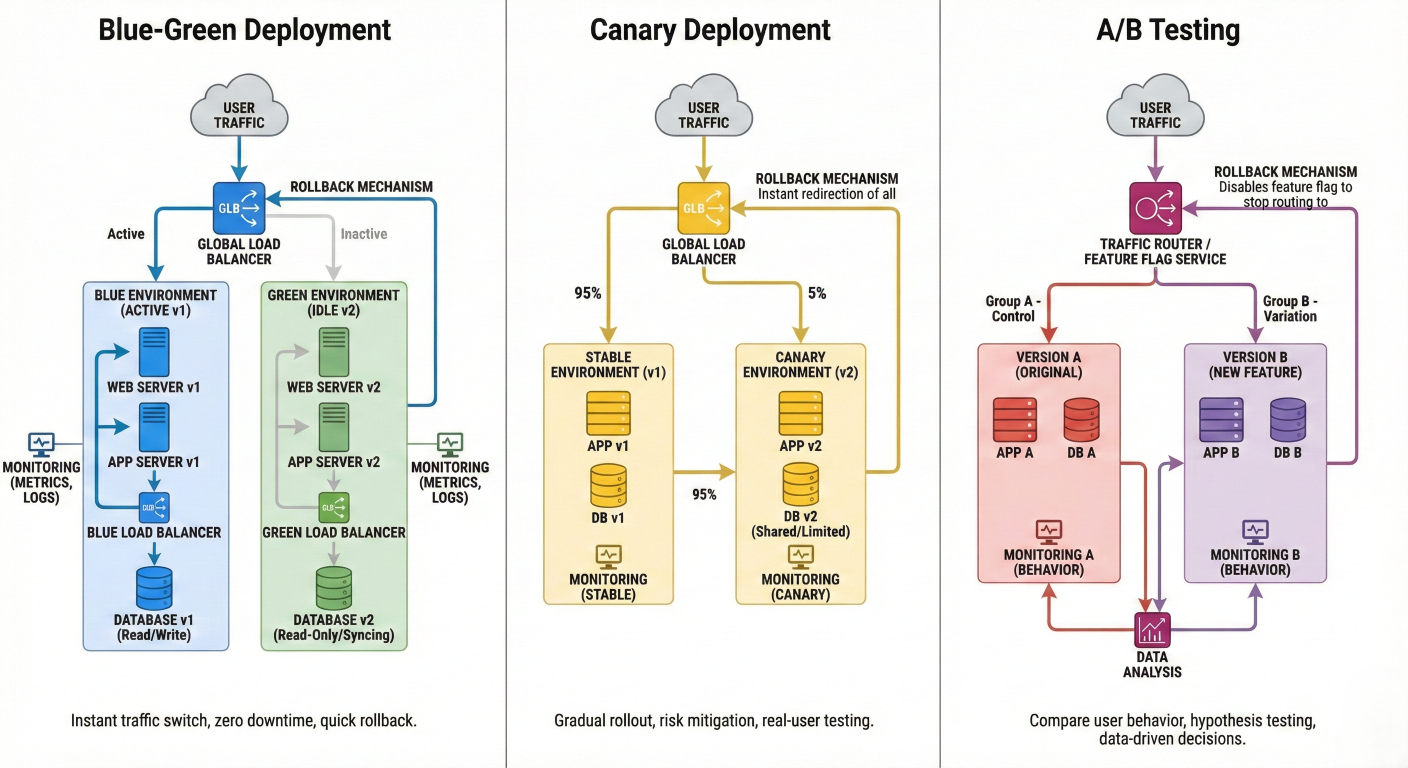
Detailed description about picture/Architecture/Diagram: Deployment strategies diagram showing blue-green, canary, and A/B testing patterns. Include traffic routing, monitoring points, and rollback mechanisms.
XComs (cross-communications) enable sophisticated data sharing patterns in ML pipelines, but they require careful consideration for production use.
from typing import Dict, Any
from airflow.models import BaseOperator
from airflow.decorators import task
@task
def train_multiple_models() -> Dict[str, Any]:
"""Train multiple models and return comparative metrics"""
models_results = {}
for model_type in ['random_forest', 'xgboost', 'neural_network']:
# Train each model (simplified)
model, metrics = train_model(model_type)
models_results[model_type] = {
'accuracy': metrics['accuracy'],
'precision': metrics['precision'],
'recall': metrics['recall'],
'model_size_mb': get_model_size(model),
'training_time_sec': metrics['training_time']
}
return models_results
@task
def select_best_model(model_results: Dict[str, Any]) -> str:
"""Intelligent model selection based on multiple criteria"""
# Multi-criteria decision making
scores = {}
for model_name, metrics in model_results.items():
# Weighted scoring function
score = (
0.4 * metrics['accuracy'] +
0.3 * metrics['precision'] +
0.2 * metrics['recall'] +
0.1 * (1 - min(metrics['model_size_mb'] / 100, 1)) # Prefer smaller models
)
scores[model_name] = score
best_model = max(scores.items(), key=lambda x: x[^2_4])
return {
'selected_model': best_model,
'selection_score': best_model[^2_4],
'all_scores': scores,
'selection_timestamp': datetime.now().isoformat()
}
# Task dependencies with XCom passing
model_results = train_multiple_models()
best_model = select_best_model(model_results)
Airflow's dynamic capabilities enable sophisticated ML workflows that adapt based on data, model performance, or business conditions.
from typing import Dict, Any
from airflow.models import BaseOperator
from airflow.decorators import task
@task
def train_multiple_models() -> Dict[str, Any]:
"""Train multiple models and return comparative metrics"""
models_results = {}
for model_type in ['random_forest', 'xgboost', 'neural_network']:
# Train each model (simplified)
model, metrics = train_model(model_type)
models_results[model_type] = {
'accuracy': metrics['accuracy'],
'precision': metrics['precision'],
'recall': metrics['recall'],
'model_size_mb': get_model_size(model),
'training_time_sec': metrics['training_time']
}
return models_results
from airflow.decorators import dag, task
from airflow.operators.python import get_current_context
@dag(schedule_interval='@daily')
def dynamic_mlops_pipeline():
@task
def check_model_performance():
"""Check if model retraining is needed"""
# Get current model performance from monitoring system
current_accuracy = get_production_model_accuracy()
baseline_accuracy = 0.85
performance_degradation = baseline_accuracy - current_accuracy
return {
'needs_retraining': performance_degradation > 0.05,
'performance_degradation': performance_degradation,
'trigger_reason': 'performance_drift' if performance_degradation > 0.05 else None
}
@task
def generate_training_tasks(performance_check: dict):
"""Generate dynamic training configurations"""
if performance_check['needs_retraining']:
# Intensive retraining with multiple strategies
return [
{'strategy': 'hyperopt', 'priority': 'high'},
{'strategy': 'ensemble', 'priority': 'medium'},
{'strategy': 'feature_selection', 'priority': 'low'}
]
else:
# Light validation training
return [{'strategy': 'validation', 'priority': 'low'}]
@task
def train_model_strategy(config: dict):
"""Train model with specific strategy"""
strategy = config['strategy']
if strategy == 'hyperopt':
return train_with_hyperparameter_optimization()
elif strategy == 'ensemble':
return train_ensemble_model()
elif strategy == 'feature_selection':
return train_with_feature_selection()
else:
return validate_current_model()
# Dynamic workflow generation
performance_check = check_model_performance()
training_configs = generate_training_tasks(performance_check)
# Dynamic task mapping
training_results = train_model_strategy.expand(config=training_configs)
return training_results
dynamic_pipeline = dynamic_mlops_pipeline()
Sensors enable reactive MLOps workflows that respond to data availability, external events, or system conditions.
from airflow.sensors.base import BaseSensorOperator
from airflow.sensors.sql import SqlSensor
class ModelPerformanceSensor(BaseSensorOperator):
"""Custom sensor for monitoring model performance"""
def __init__(self, model_id: str, performance_threshold: float = 0.8, **kwargs):
super().__init__(**kwargs)
self.model_id = model_id
self.performance_threshold = performance_threshold
# Sensors for Data-Driven MLOps
# Data freshness sensors: Wait for new data before triggering training
# Model performance sensors: Monitor production metrics and trigger actions
# External system sensors: React to changes in feature stores, data warehouses
# Custom validation sensors: Complex business logic for pipeline triggers
def poke(self, context):
"""Check if model performance is below threshold"""
# Connect to monitoring system
current_performance = get_model_performance(self.model_id)
self.log.info(f"Current performance: {current_performance}")
if current_performance < self.performance_threshold:
self.log.warning(f"Performance degradation detected: {current_performance}")
return True
return False
class FeatureStoreFreshnessSensor(SqlSensor):
"""Monitor feature store for fresh data"""
def __init__(self, feature_table: str, max_age_hours: int = 24, **kwargs):
sql = f"""
SELECT CASE
WHEN MAX(updated_at) > NOW() - INTERVAL '{max_age_hours} HOURS'
THEN 1 ELSE 0
END as fresh_data_available
FROM {feature_table}
"""
super().__init__(sql=sql, **kwargs)
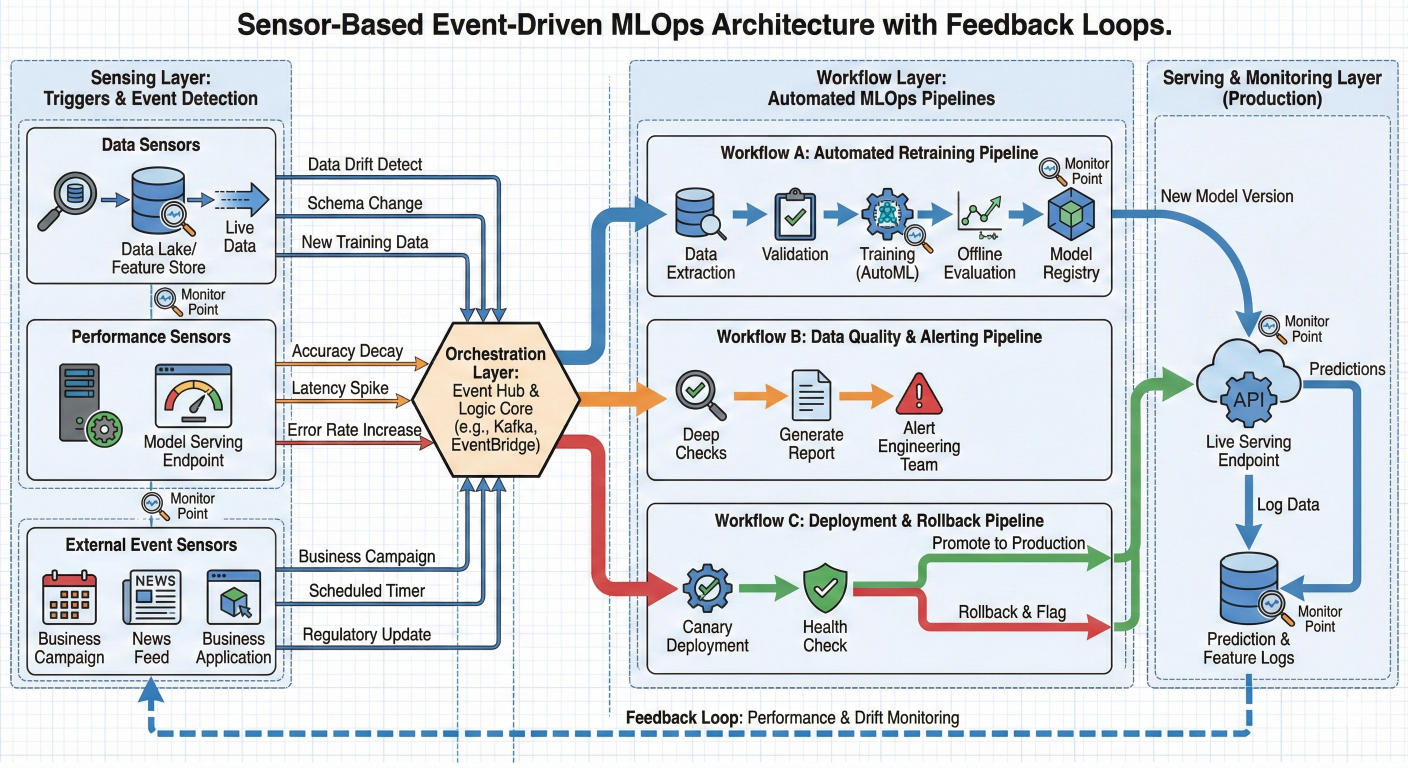
Detailed description about picture/Architecture/Diagram: Sensor-based architecture showing various triggers: data sensors, performance sensors, and external event sensors feeding into different MLOps workflows. Include feedback loops and monitoring points.
Model drift is one of the most critical challenges in production ML. Airflow orchestrates sophisticated drift detection and response workflows
@task
def detect_model_drift(production_data: dict, training_data: dict):
"""Comprehensive drift detection using multiple methods"""
import numpy as np
from scipy import stats
# Production MLOps: Advanced Monitoring and Alerting
# Model Drift Detection and Automated Response
# [22] [30] [21]
# Statistical drift detection: PSI, KL divergence
# Performance-based drift: Continuous validation
# Feature drift monitoring: Track feature distributions
# Concept drift detection: Monitor target relationships
prod_features = pd.DataFrame(production_data)
train_features = pd.DataFrame(training_data)
drift_results = {}
for feature in prod_features.columns:
if feature in train_features.columns:
# Statistical drift detection
ks_statistic, ks_p_value = stats.ks_2samp(
train_features[feature],
prod_features[feature]
)
# Population Stability Index
psi_score = calculate_psi(
train_features[feature],
prod_features[feature]
)
drift_results[feature] = {
'ks_statistic': ks_statistic,
'ks_p_value': ks_p_value,
'psi_score': psi_score,
'drift_detected': ks_p_value < 0.05 or psi_score > 0.2
}
# Overall drift assessment
overall_drift = sum(r['drift_detected'] for r in drift_results.values()) > len(drift_)
return {
'feature_drift': drift_results,
'overall_drift_detected': overall_drift,
'drift_timestamp': datetime.now().isoformat()
}
def calculate_psi(expected, actual, buckets=10):
"""Calculate Population Stability Index"""
# Implementation of PSI calculation
pass
@task
def handle_drift_detection(drift_results: dict):
"""Automated response to drift detection"""
if drift_results['overall_drift_detected']:
# Trigger retraining pipeline
trigger_dag_run(
dag_id='model_retraining_pipeline',
conf={'trigger_reason': 'drift_detected', 'drift_results': drift_results}
)
# Send alerts
send_slack_alert(
channel='#ml-alerts',
message=f"🚨 Model drift detected! Retraining triggered. Details: {drift_results}"
)
return drift_results
Modern MLOps relies heavily on feature stores for consistent, reliable feature serving. Airflow orchestrates complex feature engineering pipelines that populate and maintain feature stores.
from airflow.providers.postgres.operators.postgres import PostgresOperator
@task
def compute_batch_features(raw_data: dict):
"""Compute features for feature store"""
df = pd.DataFrame(raw_data)
# User behavior features
user_features = df.groupby('user_id').agg({
'purchase_amount': ['sum', 'mean', 'count'],
'session_duration': ['mean', 'max'],
'page_views': 'sum',
'last_activity': 'max'
}).round(4)
# Product popularity features
product_features = df.groupby('product_id').agg({
'purchase_amount': 'sum',
'user_id': 'nunique',
'rating': 'mean'
}).round(4)
# Flatten column names
user_features.columns = ['_'.join(col).strip() for col in user_features.columns.value]
product_features.columns = ['_'.join(col).strip() for col in product_features.columns]
return {
'user_features': user_features.reset_index().to_dict('records'),
'product_features': product_features.reset_index().to_dict('records'),
'computation_timestamp': datetime.now().isoformat()
}
@task
def validate_feature_quality(features: dict):
"""Validate feature quality before storing"""
# Feature Store Integration and Management
# Batch feature computation: Scheduled feature engineering
# Real-time feature streaming: Low-latency feature updates
# Feature validation: Ensure feature quality and consistency
# Feature versioning: Track feature evolution over time
# Cross-team feature sharing: Enable feature reuse
validation_results = {}
for feature_type, feature_data in features.items():
if feature_type.endswith('_timestamp'):
continue
df = pd.DataFrame(feature_data)
validation_results[feature_type] = {
'record_count': len(df),
'null_percentage': (df.isnull().sum() / len(df) * 100).to_dict(),
'duplicate_count': df.duplicated().sum(),
'data_quality_score': calculate_data_quality_score(df)
}
# Quality thresholds
if validation_results[feature_type]['data_quality_score'] < 0.8:
raise ValueError(f"Feature quality too low for {feature_type}")
return validation_results
@task
def update_feature_store(features: dict, validation_results: dict):
"""Update feature store with validated features"""
from hopsworks import project
# Connect to feature store (example with Hopsworks)
project_connection = project.connect()
fs = project_connection.get_feature_store()
for feature_type, feature_data in features.items():
if feature_type.endswith('_timestamp'):
continue
feature_group = fs.get_or_create_feature_group(
name=f"{feature_type}_features",
version=1,
primary_key=['user_id'] if 'user' in feature_type else ['product_id'],
event_time='computation_timestamp'
)
feature_group.insert(pd.DataFrame(feature_data))
return {
'feature_store_update_timestamp': datetime.now().isoformat(),
'updated_feature_groups': list(features.keys())
}
# Feature pipeline orchestration
raw_data = extract_raw_data()
computed_features = compute_batch_features(raw_data)
validation_results = validate_feature_quality(computed_features)
feature_store_update = update_feature_store(computed_features, validation_results)
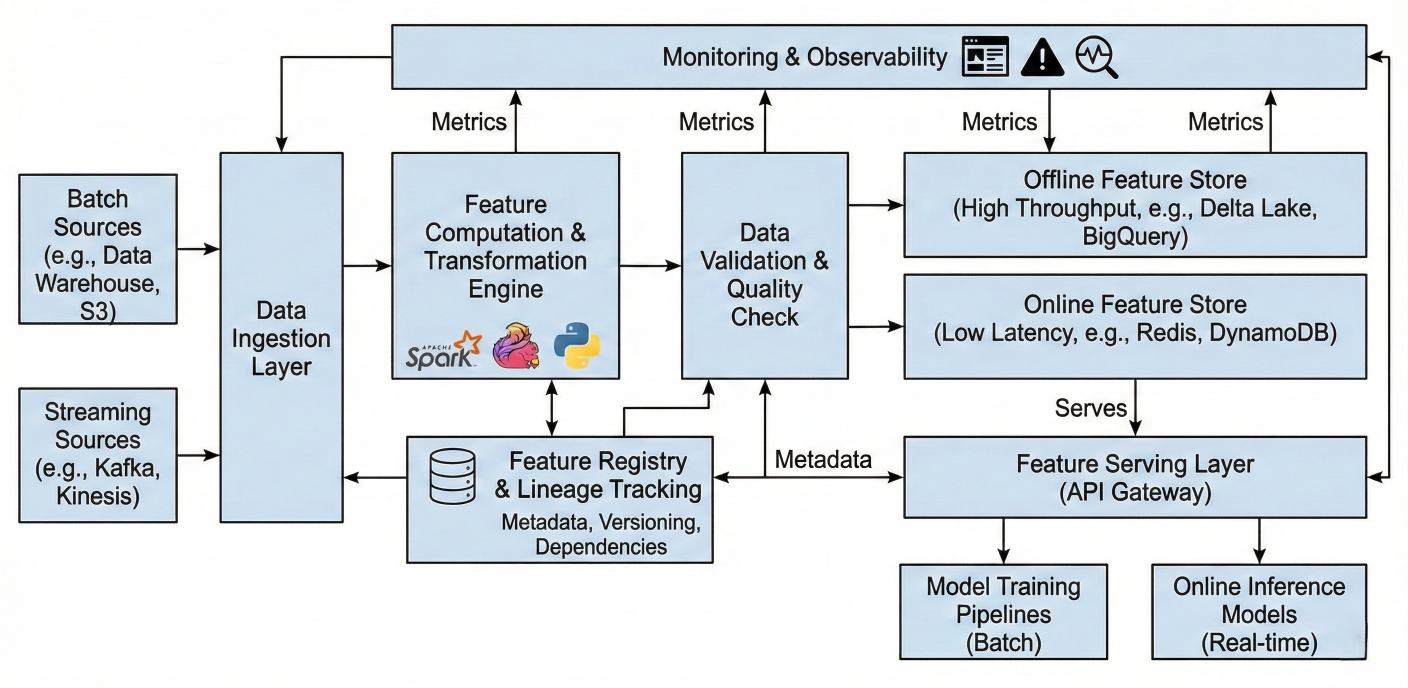
Detailed description about picture/Architecture/Diagram: Feature store architecture showing data ingestion, feature computation, validation, storage (online/offline), and serving layers. Include feature lineage tracking and monitoring components.
Modern MLOps requires treating ML code with the same rigor as application code. Airflow integrates seamlessly with CI/CD systems for automated testing, validation, and deployment.
# .github/workflows/mlops-cicd.yml
name: MLOps CI/CD Pipeline
on:
push:
branches: [main, develop]
pull_request:
branches: [main]
jobs:
test-dags:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Set up Python
uses: actions/setup-python@v4
with:
python-version: '3.9'
- name: Install dependencies
run: |
pip install apache-airflow pytest
pip install -r requirements.txt
- name: Test DAG integrity
run: |
python -m pytest tests/test_dag_integrity.py
- name: Validate DAG syntax
run: |
python -c "from airflow.models import DagBag; dag_bag = DagBag(); print(f'DAGs)"
# CI/CD Integration for MLOps Automation
# Git-based MLOps Workflows
# Automated DAG testing: Validate DAG syntax, dependencies, and logic
# Model validation pipelines: Automated model performance validation
# Infrastructure as Code: Automated environment provisioning
# Progressive deployment: Automated staging-to-production promotion
deploy-staging:
needs: test-dags
if: github.ref == 'refs/heads/develop'
runs-on: ubuntu-latest
steps:
- name: Deploy to Staging
run: |
# Deploy DAGs to staging Airflow environment
astro deploy staging
deploy-production:
needs: test-dags
if: github.ref == 'refs/heads/main'
runs-on: ubuntu-latest
steps:
- name: Deploy to Production
run: |
astro deploy production
Testing ML pipelines requires specialized strategies that go beyond traditional software testing.
# tests/test_mlops_pipeline.py
import pytest
from airflow.models import DagBag
from datetime import datetime, timedelta
class TestMLOpsPipeline:
def setup_method(self):
self.dag_bag = DagBag()
self.dag = self.dag_bag.get_dag('advanced_mlops_pipeline')
def test_dag_loaded(self):
"""Test that DAG is properly loaded"""
assert self.dag is not None
assert len(self.dag.tasks) > 0
def test_dag_structure(self):
"""Test DAG structure and dependencies"""
expected_tasks = [
'validate_data_availability',
'extract_and_validate_data',
# Automated Testing Strategies for ML Pipelines
# Data validation tests: Ensure data quality and consistency
# Model performance tests: Validate model behavior and accuracy
# Integration tests: Test end-to-end pipeline functionality
# Regression tests: Ensure changes don't break existing functionality
'feature_engineering_and_selection',
'train_and_validate_model',
'deploy_to_production'
]
actual_tasks = [task.task_id for task in self.dag.tasks]
for expected_task in expected_tasks:
assert expected_task in actual_tasks
def test_no_import_errors(self):
"""Test that there are no import errors in DAG"""
assert len(self.dag_bag.import_errors) == 0
@pytest.mark.parametrize("task_id", [
'validate_data_availability',
'extract_and_validate_data'
])
def test_task_configuration(self, task_id):
"""Test individual task configuration"""
task = self.dag.get_task(task_id)
assert task.retries >= 1
assert task.retry_delay is not None
# Data validation tests
def test_data_quality_validation():
"""Test data quality validation function"""
from dags.mlops_pipeline import validate_data_quality
# Test data
test_data = {
'feature_1': [1, 2, 3, None],
'feature_2': [4, 5, 6, 7],
'target': [0, 1, 0, 1]
}
with pytest.raises(ValueError): # Should fail due to null values
validate_data_quality(test_data)
# Model testing
def test_model_validation_thresholds():
"""Test model validation with different performance levels"""
from dags.mlops_pipeline import validate_model_performance
# Test with good performance
good_metrics = {'accuracy': 0.85, 'precision': 0.80, 'recall': 0.82}
assert validate_model_performance(good_metrics) == True
# Test with poor performance
poor_metrics = {'accuracy': 0.60, 'precision': 0.58, 'recall': 0.55}
assert validate_model_performance(poor_metrics) == False
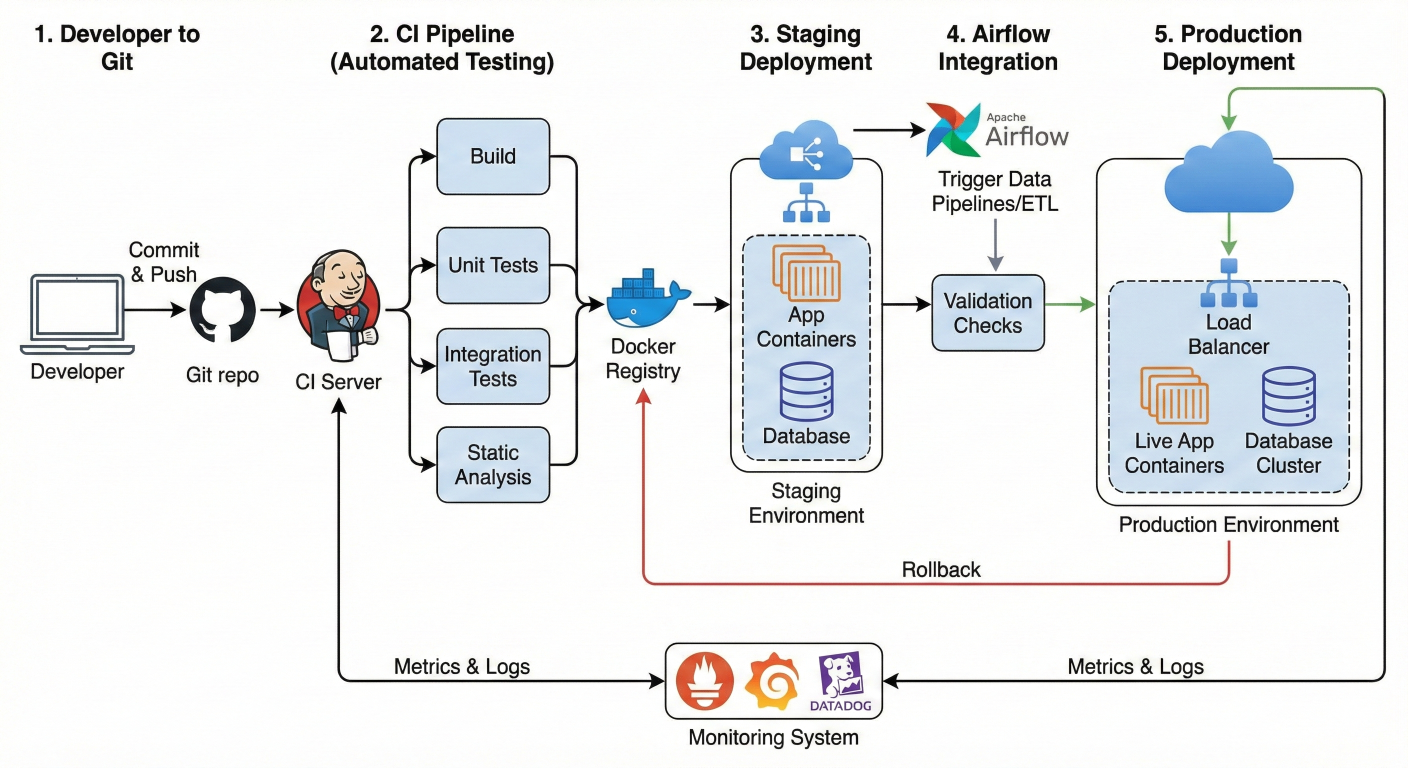
Detailed description about picture/Architecture/Diagram: CI/CD pipeline diagram showing Git workflow, automated testing stages, staging deployment, validation checks, and production deployment with rollback capabilities. Include integration points with Airflow and monitoring systems.
Production MLOps requires sophisticated deployment patterns that enable safe, reliable model updates without service disruption
@task
def deploy_with_canary_strategy(model_metadata: dict):
"""Deploy model using canary deployment pattern"""
deployment_config = {
'model_version': model_metadata['model_version'],
'deployment_strategy': 'canary',
'traffic_allocation': {
'stable': 95, # Current production model
'canary': 5 # New model version
},
'success_criteria': {
'min_success_rate': 0.99,
'max_latency_p95': 100, # milliseconds
'min_prediction_accuracy': 0.85
},
'rollback_triggers': {
'error_rate_threshold': 0.01,
'latency_threshold': 200,
'accuracy_threshold': 0.80
},
'monitoring_duration': 3600 # 1 hour
}
# Deploy to canary environment
canary_endpoint = deploy_to_canary(model_metadata, deployment_config)
# Start traffic splitting
configure_traffic_split(deployment_config['traffic_allocation'])
return {
'canary_endpoint': canary_endpoint,
'deployment_config': deployment_config,
'deployment_start_time': datetime.now().isoformat()
}
# Advanced Production Deployment Patterns
# Multi-Environment MLOps Architecture
# [15] [13]
# Environment isolation: Separate development, staging, and production environments
# Infrastructure as Code: Consistent environment provisioning with Terraform/CDK
# Service mesh integration: Advanced traffic management and observability
# Multi-region deployment: Global model serving with regional failover
@task
def monitor_canary_deployment(deployment_info: dict):
"""Monitor canary deployment and make promotion decision"""
import time
config = deployment_info['deployment_config']
monitoring_start = datetime.fromisoformat(deployment_info['deployment_start_time'])
# Monitor for specified duration
while (datetime.now() - monitoring_start).seconds < config['monitoring_duration']:
metrics = get_canary_metrics(deployment_info['canary_endpoint'])
# Check rollback conditions
if should_rollback(metrics, config['rollback_triggers']):
rollback_deployment(deployment_info['canary_endpoint'])
raise AirflowFailException("Canary deployment failed - rolled back")
time.sleep(60) # Check every minute
# Check success criteria
final_metrics = get_canary_metrics(deployment_info['canary_endpoint'])
if meets_success_criteria(final_metrics, config['success_criteria']):
# Promote to production
promote_to_production(deployment_info['canary_endpoint'])
return {'status': 'promoted', 'final_metrics': final_metrics}
else:
# Rollback
rollback_deployment(deployment_info['canary_endpoint'])
raise AirflowFailException("Canary deployment did not meet success criteria")
def should_rollback(metrics: dict, triggers: dict) -> bool:
"""Determine if deployment should be rolled back"""
return (
metrics['error_rate'] > triggers['error_rate_threshold'] or
metrics['latency_p95'] > triggers['latency_threshold'] or
metrics['accuracy'] < triggers['accuracy_threshold']
)
Production MLOps requires sophisticated model management that tracks model lineage, performance, and deployment history.
@task
def register_model_version(model_metadata: dict, validation_results: dict):
"""Register model with comprehensive metadata"""
import mlflow
from mlflow.tracking import MlflowClient
client = MlflowClient()
# Create model registry entry
# Model Registry Integration and Versioning
model_version = client.create_model_version(
name="production_model",
source=model_metadata['model_uri'],
description=f"Model trained on {model_metadata['training_timestamp']}",
tags={
'accuracy': str(model_metadata['metrics']['test_accuracy']),
'training_data_version': model_metadata.get('data_version', 'unknown'),
'feature_set_version': model_metadata.get('feature_version', 'unknown'),
'validation_passed': str(validation_results['overall_validation']),
'deployment_ready': 'true'
}
)
# Add model signature and requirements
model_signature = infer_signature(
model_metadata['sample_input'],
model_metadata['sample_output']
)
mlflow.models.log_model(
model_metadata['model'],
"model",
signature=model_signature,
requirements="requirements.txt"
)
return {
'model_version': model_version.version,
'model_name': model_version.name,
'registry_uri': model_version.source,
'registration_timestamp': datetime.now().isoformat()
}
Production ML systems require deep observability that goes beyond traditional application monitoring
@task def setup_comprehensive_monitoring(model_deployment: dict): """Set up multi-layer monitoring for deployed model""" monitoring_config = { 'model_version': model_deployment['model_version'], 'monitoring_layers': { 'infrastructure': { 'metrics': ['cpu_usage', 'memory_usage', 'disk_io', 'network_io'], 'alerting_thresholds': { 'cpu_usage': 80, 'memory_usage': 85, 'response_time_p95': 100 } }, 'model_performance': { 'metrics': ['prediction_accuracy', 'prediction_latency', 'throughput'], 'drift_detection': ['feature_drift', 'concept_drift'], 'alerting_thresholds': { 'accuracy_drop': 0.05, 'latency_increase': 50, 'drift_score': 0.3 } }, 'business_metrics': { 'metrics': ['conversion_rate', 'revenue_impact', 'user_satisfaction'], 'reporting_frequency': 'hourly' } }, 'alerting_channels': ['slack', 'email', 'pagerduty'], 'dashboard_urls': { 'technical': f"https://grafana.company.com/model/{model_deployment['model_version']}", 'business': f"https://dashboard.company.com/ml-impact/{model_deployment['model_version']}" } } # Configure monitoring stack setup_prometheus_metrics(monitoring_config) setup_grafana_dashboards(monitoring_config) configure_alerting_rules(monitoring_config) return monitoring_config @task def automated_health_check(deployment_info: dict): """Automated health check with intelligent alerting""" health_status = { 'timestamp': datetime.now().isoformat(), 'model_version': deployment_info['model_version'], 'checks': {} } # Infrastructure health infra_metrics = get_infrastructure_metrics(deployment_info['endpoint']) health_status['checks']['infrastructure'] = { 'status': 'healthy' if all( metric < threshold for metric, threshold in deployment_info['alerting_thresholds'].items() ) else 'degraded', 'metrics': infra_metrics } # Model performance health model_metrics = get_model_performance_metrics(deployment_info['endpoint']) health_status['checks']['model_performance'] = { 'status': 'healthy' if model_metrics['accuracy'] > 0.80 else 'degraded', 'metrics': model_metrics } # Business impact health business_metrics = get_business_impact_metrics(deployment_info['model_version']) health_status['checks']['business_impact'] = { 'status': 'healthy' if business_metrics['positive_impact'] else 'attention_needed', 'metrics': business_metrics } # Overall health assessment health_status['overall_status'] = determine_overall_health(health_status['checks']) # Trigger alerts if needed if health_status['overall_status'] in ['degraded', 'unhealthy']: send_intelligent_alert(health_status) return health_status
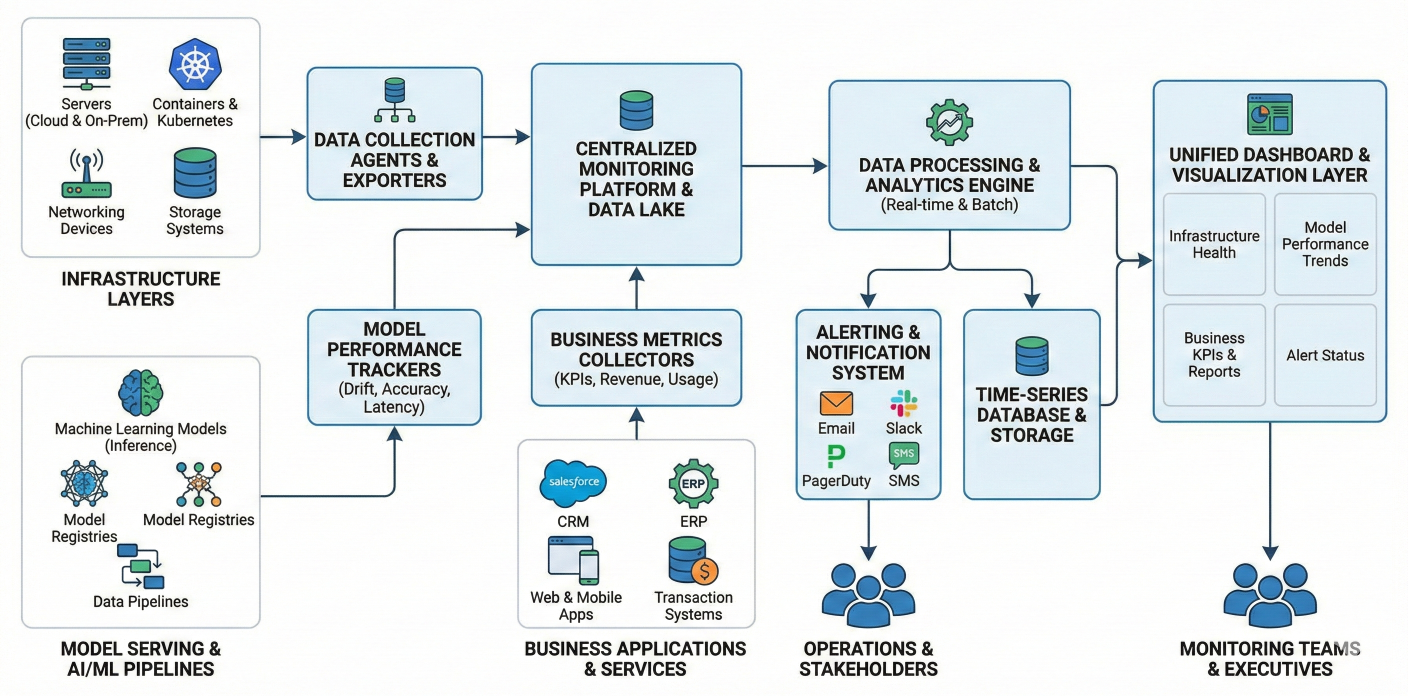
Detailed description about picture/Architecture/Diagram: Comprehensive monitoring architecture showing infrastructure monitoring, model performance tracking, business metrics monitoring, alerting systems, and dashboard integration. Include data flow between monitoring components.
Let's put it all together with a comprehensive, production-ready MLOps pipeline that demonstrates all the concepts we've covered:
from datetime import datetime, timedelta
from airflow.decorators import dag, task
from airflow.operators.python import PythonOperator
from airflow.providers.postgres.operators.postgres import PostgresOperator
from airflow.sensors.sql_sensor import SqlSensor
from airflow.models import Variable
from airflow.exceptions import AirflowFailException
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split, RandomizedSearchCV
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
import mlflow
import json
import logging
from typing import Dict, List, Any
# Production-grade default arguments
default_args = {
'owner': 'mlops-platform-team',
'depends_on_past': False,
'start_date': datetime(2024, 1, 1),
'email': ['mlops-alerts@company.com'],
'email_on_failure': True,
'email_on_retry': False,
'retries': 3,
'retry_delay': timedelta(minutes=10),
'execution_timeout': timedelta(hours=4),
'sla': timedelta(hours=6),
'on_failure_callback': notify_failure,
'on_success_callback': notify_success
}
@dag(
dag_id='production_mlops_pipeline_v2',
default_args=default_args,
description='Enterprise-grade MLOps pipeline with comprehensive validation, monitorin'
schedule_interval='@daily',
catchup=False,
tags=['mlops', 'production', 'enterprise'],
max_active_runs=1,
max_active_tasks=15,
doc_md=__doc__
)
def production_mlops_workflow():
"""
## Production MLOps Pipeline v2.0
This DAG implements a comprehensive MLOps workflow including:
- Data source validation and quality checks
- Advanced feature engineering with automated selection
- Multi-model training with hyperparameter optimization
- Comprehensive model validation and testing
- Automated drift detection and monitoring
- Progressive deployment with canary releases
- Real-time monitoring and alerting
- Automated rollback and recovery
### Pipeline Stages:
1. **Data Validation**: Multi-source data availability and quality checks
2. **Feature Engineering**: Advanced temporal and categorical feature creation
3. **Model Training**: Distributed training with automated hyperparameter tuning
4. **Model Validation**: Performance, bias, and robustness testing
5. **Drift Detection**: Statistical and performance-based drift monitoring
6. **Deployment**: Progressive rollout with comprehensive monitoring
7. **Monitoring**: Real-time performance and business impact tracking
### Key Features:
- Automatic rollback on performance degradation
- Multi-environment deployment (staging → production)
- Integration with feature stores and model registries
- Comprehensive alerting and notification system
- Built-in A/B testing and canary deployments
"""
# Data availability and validation sensor
wait_for_data = SqlSensor(
task_id='wait_for_fresh_data',
conn_id='feature_store_db',
sql="""
SELECT COUNT(*)
FROM feature_table
WHERE updated_at > NOW() - INTERVAL '2 HOURS'
""",
poke_interval=300, # Check every 5 minutes
timeout=3600, # Timeout after 1 hour
mode='reschedule'
)
@task
def validate_data_sources(**context):
"""Comprehensive data source validation"""
data_sources = {
'user_events': check_data_source('user_events_table'),
'product_catalog': check_data_source('product_catalog'),
'transaction_data': check_data_source('transactions'),
'feature_store': check_feature_store_health(),
'external_data': check_external_api_health()
}
# Validate data freshness and quality
validation_results = {}
for source, status in data_sources.items():
validation_results[source] = {
'available': status['available'],
'freshness_hours': status['data_age_hours'],
'quality_score': status['quality_score'],
'record_count': status['record_count']
}
# Check if any critical data sources are unavailable
critical_sources = ['user_events', 'transaction_data', 'feature_store']
unavailable_critical = [
source for source in critical_sources
if not validation_results[source]['available']
]
if unavailable_critical:
raise AirflowFailException(f"Critical data sources unavailable: {unavailable_")
# Check data freshness
stale_data = [
source for source, results in validation_results.items()
if results['freshness_hours'] > 24
]
if stale_data:
logging.warning(f"Stale data detected in sources: {stale_data}")
return validation_results
@task
def extract_and_validate_training_data(data_sources: Dict[str, Any]):
"""Extract and validate training dataset"""
# Extract data from multiple sources
datasets = {}
# User behavioral data
datasets['user_events'] = extract_user_events(
start_date=context['ds'],
lookback_days=30
)
# Transaction history
datasets['transactions'] = extract_transaction_data(
start_date=context['ds'],
lookback_days=90
)
# Product information
datasets['products'] = extract_product_data()
# Feature store features
datasets['features'] = extract_feature_store_data(
feature_groups=['user_profiles', 'product_features', 'interaction_features']
)
# Comprehensive data validation
validation_results = perform_comprehensive_validation(datasets)
# Merge datasets
training_data = merge_datasets(datasets)
return {
'training_data': training_data.to_dict('records'),
'data_validation': validation_results,
'extraction_metadata': {
'extraction_time': datetime.now().isoformat(),
'data_version': generate_data_version_hash(datasets),
'source_counts': {k: len(v) for k, v in datasets.items()}
}
}
@task
def advanced_feature_engineering(data_package: Dict[str, Any]):
"""Advanced feature engineering with automated selection"""
df = pd.DataFrame(data_package['training_data'])
logging.info(f"Starting feature engineering on {len(df)} records...")
# Temporal feature engineering
df = create_temporal_features(df)
# User behavioral features
df = create_user_behavioral_features(df)
# Product interaction features
df = create_product_interaction_features(df)
# Advanced statistical features
df = create_statistical_features(df)
# Automated feature selection
selected_features, feature_importance = automated_feature_selection(
df, target_column='target'
)
# Feature validation and quality assessment
feature_quality = assess_feature_quality(df[selected_features])
return {
'engineered_data': df.to_dict('records'),
'selected_features': selected_features,
'feature_importance': feature_importance,
'feature_quality': feature_quality,
'feature_metadata': {
'total_features_created': len(df.columns),
'features_selected': len(selected_features),
'selection_method': 'recursive_feature_elimination',
'engineering_timestamp': datetime.now().isoformat()
}
}
@task.expand(model_type=['random_forest', 'xgboost', 'neural_network'])
def train_model_parallel(processed_data: Dict[str, Any], model_type: str):
"""Parallel model training with different algorithms"""
df = pd.DataFrame(processed_data['engineered_data'])
feature_cols = processed_data['selected_features']
X = df[feature_cols]
y = df['target']
# Stratified train-validation-test split
X_train, X_temp, y_train, y_temp = train_test_split(
X, y, test_size=0.4, random_state=42, stratify=y
)
X_val, X_test, y_val, y_test = train_test_split(
X_temp, y_temp, test_size=0.5, random_state=42, stratify=y_temp
)
# MLflow experiment tracking
with mlflow.start_run(run_name=f"{model_type}_training"):
# Hyperparameter optimization
model, best_params, cv_scores = optimize_hyperparameters(
model_type, X_train, y_train, X_val, y_val
)
# Train final model
model.fit(X_train, y_train)
# Comprehensive evaluation
metrics = evaluate_model_comprehensively(
model, X_train, y_train, X_val, y_val, X_test, y_test
)
# Log everything to MLflow
mlflow.log_params(best_params)
mlflow.log_metrics(metrics)
mlflow.sklearn.log_model(model, f"{model_type}_model")
return {
'model_type': model_type,
'model_uri': mlflow.get_artifact_uri(f"{model_type}_model"),
'metrics': metrics,
'hyperparameters': best_params,
'cv_scores': cv_scores,
'training_timestamp': datetime.now().isoformat()
}
@task
def select_champion_model(model_results: List[Dict[str, Any]]):
"""Intelligent model selection using multiple criteria"""
# Multi-criteria decision matrix
selection_criteria = {
'test_f1': 0.4, # Primary metric weight
'test_precision': 0.2, # Business importance
'test_recall': 0.2, # Coverage importance
'training_time': 0.1, # Efficiency
'model_size': 0.1 # Deployment consideration
}
model_scores = {}
for model_result in model_results:
model_type = model_result['model_type']
metrics = model_result['metrics']
# Calculate weighted score
score = 0
for criterion, weight in selection_criteria.items():
if criterion in metrics:
# Normalize and weight the score
normalized_score = normalize_metric(criterion, metrics[criterion])
score += weight * normalized_score
model_scores[model_type] = {
'total_score': score,
'metrics': metrics,
'model_result': model_result
}
# Select champion model
champion_model_type = max(model_scores.items(), key=lambda x: x[1]['total_score'])[0]
champion_model = model_scores[champion_model_type]['model_result']
# Champion/challenger analysis
sorted_models = sorted(model_scores.items(), key=lambda x: x[1]['total_score'], reverse=True)
selection_summary = {
'champion_model': champion_model,
'model_ranking': [(model, score['total_score']) for model, score in sorted_mo
'selection_criteria': selection_criteria,
'selection_timestamp': datetime.now().isoformat(),
'performance_gap': sorted_models[^2_4]['total_score'] - sorted_models[^2_4][^
}
return selection_summary
@task
def comprehensive_model_validation(champion_model: Dict[str, Any]):
"""Comprehensive model validation before deployment"""
validation_tests = {
'performance_validation': validate_model_performance(champion_model),
'bias_fairness_test': test_model_bias_fairness(champion_model),
'robustness_test': test_model_robustness(champion_model),
'interpretability_test': test_model_interpretability(champion_model),
'business_validation': validate_business_metrics(champion_model),
'security_scan': perform_security_scan(champion_model),
'compliance_check': check_regulatory_compliance(champion_model)
}
# Overall validation status
validation_passed = all(test['passed'] for test in validation_tests.values())
validation_score = sum(test.get('score', 0) for test in validation_tests.values())
if not validation_passed:
failed_tests = [name for name, test in validation_tests.items() if not test['passed']]
raise AirflowFailException(f"Model validation failed: {failed_tests}")
return {
'champion_model': champion_model,
'validation_results': validation_tests,
'validation_passed': validation_passed,
'validation_score': validation_score,
'validation_timestamp': datetime.now().isoformat()
}
@task
def deploy_to_staging_environment(validated_model: Dict[str, Any]):
"""Deploy model to staging with comprehensive monitoring"""
staging_config = {
'environment': 'staging',
'model_version': f"v{datetime.now().strftime('%Y%m%d_%H%M%S')}",
'deployment_strategy': 'blue_green',
'health_check_config': {
'initial_delay': 60,
'check_interval': 30,
'failure_threshold': 3,
'success_threshold': 2
},
'monitoring_config': {
'performance_sla': {'p95_latency': 100, 'accuracy_threshold': 0.85},
'alerting_channels': ['slack://ml-staging-alerts'],
'dashboard_url': f"https://monitoring.company.com/staging/{validated_mode}"
}
}
# Deploy to staging
staging_deployment = deploy_model_to_environment(
validated_model['champion_model'],
staging_config
)
# Run comprehensive staging tests
staging_test_results = run_staging_tests(staging_deployment)
if not staging_test_results['all_tests_passed']:
raise AirflowFailException(f"Staging tests failed: {staging_test_results['fai")
return {
'validated_model': validated_model,
'staging_deployment': staging_deployment,
'staging_tests': staging_test_results,
'staging_config': staging_config
}
@task
def production_deployment_with_monitoring(staging_result: Dict[str, Any]):
"""Production deployment with advanced monitoring and rollback"""
production_config = {
'environment': 'production',
'model_version': staging_result['staging_config']['model_version'],
'deployment_strategy': 'canary',
'canary_config': {
'initial_traffic': 5,
'traffic_ramp_schedule': [5, 10, 25, 50, 100],
'ramp_interval_minutes': 30,
'success_criteria': {
'min_accuracy': 0.85,
'max_latency_p95': 100,
'min_success_rate': 0.999,
'max_error_rate': 0.001
},
'rollback_triggers': {
'accuracy_drop': 0.05,
'latency_spike': 2.0,
'error_rate_spike': 0.01,
'business_metric_drop': 0.10
}
},
'monitoring_config': {
'real_time_monitoring': True,
'drift_detection': True,
'performance_tracking': True,
'business_impact_tracking': True,
'alert_channels': ['pagerduty://ml-production', 'slack://ml-alerts'],
'dashboard_url': f"https://monitoring.company.com/production/{staging_res
}
}
# Execute canary deployment
production_deployment = execute_canary_deployment(
staging_result['validated_model']['champion_model'],
production_config
)
# Set up comprehensive monitoring
monitoring_setup = setup_production_monitoring(
production_deployment,
production_config['monitoring_config']
)
return {
'production_deployment': production_deployment,
'monitoring_setup': monitoring_setup,
'deployment_config': production_config,
'deployment_timestamp': datetime.now().isoformat()
}
@task
def send_comprehensive_notifications(deployment_result: Dict[str, Any]):
"""Send detailed deployment notifications to all stakeholders"""
model_version = deployment_result['deployment_config']['model_version']
champion_metrics = deployment_result['production_deployment']['champion_model'][
# Prepare comprehensive notification
notification_payload = {
'deployment_success': True,
'model_version': model_version,
'deployment_timestamp': deployment_result['deployment_timestamp'],
'performance_summary': {
'test_accuracy': f"{champion_metrics['test_accuracy']:.4f}",
'test_precision': f"{champion_metrics['test_precision']:.4f}",
'test_recall': f"{champion_metrics['test_recall']:.4f}",
'test_f1': f"{champion_metrics['test_f1']:.4f}"
},
'deployment_details': {
'environment': 'production',
'strategy': 'canary',
'monitoring_dashboard': deployment_result['monitoring_setup']['dashboard_'],
'api_endpoint': deployment_result['production_deployment']['api_endpoint']
},
'next_actions': [
'Monitor canary deployment metrics for 4 hours',
'Review business impact metrics in 24 hours',
'Schedule model performance review in 1 week',
'Plan next model training cycle based on performance'
]
}
# Send notifications to different channels
send_slack_notification('ml-announcements', notification_payload)
send_email_notification('ml-stakeholders@company.com', notification_payload)
update_deployment_dashboard(notification_payload)
log_deployment_event(notification_payload)
return notification_payload
# Define the complete DAG workflow
data_ready = wait_for_data
data_sources_valid = validate_data_sources()
training_data = extract_and_validate_training_data(data_sources_valid)
engineered_features = advanced_feature_engineering(training_data)
# Parallel model training
trained_models = train_model_parallel(engineered_features)
# Model selection and validation
champion_model = select_champion_model(trained_models)
validated_model = comprehensive_model_validation(champion_model)
# Deployment pipeline
staging_deployment = deploy_to_staging_environment(validated_model)
production_deployment = production_deployment_with_monitoring(staging_deployment)
# Notifications and reporting
notifications = send_comprehensive_notifications(production_deployment)
# Set up task dependencies
data_ready >> data_sources_valid >> training_data >> engineered_features
engineered_features >> trained_models >> champion_model >> validated_model
validated_model >> staging_deployment >> production_deployment >> notifications
return notifications
# Instantiate the production DAG
production_mlops_dag = production_mlops_workflow()
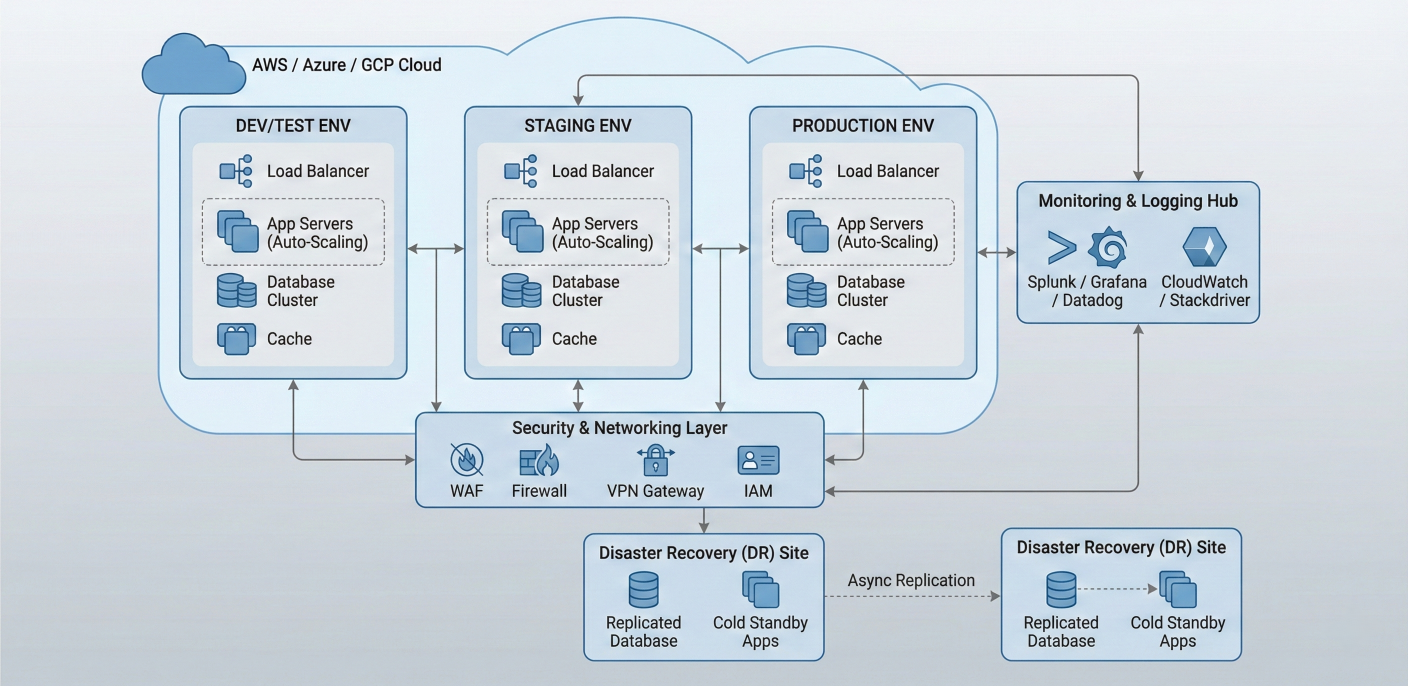
Detailed description about picture/Architecture/Diagram: Production infrastructure diagram showing multi-environment setup, security layers, monitoring integration, and scaling mechanisms. Include cloud provider integrations and disaster recovery components.
Modern MLOps increasingly relies on sophisticated feature stores that Airflow can orchestrate effectively:
Apache Airflow has evolved far beyond simple task scheduling to become the cornerstone of modern MLOps infrastructure. Its Python-native approach, robust orchestration capabilities, and extensive ecosystem of integrations make it the ideal platform for building scalable, reliable ML operations.
Ready to transform your machine learning operations? Here's how to get started:
1. Start Small: Begin with a simple training pipeline and gradually add complexity
2. Embrace Infrastructure as Code: Version control everything—DAGs, configurations, and infrastructure
3. Invest in Monitoring: Set up comprehensive observability from day one
4. Build for Scale: Design pipelines that can handle enterprise-level workloads
5. Stay Current: Keep up with the latest Airflow features and MLOps best practices
The future of machine learning belongs to organizations that can operationalize AI at scale. With Apache Airflow as your MLOps foundation, you're ready to build that future

{{AUTHOR}}
 Launch your Graphy
Launch your Graphy