

There are no items in your cart
Add More
Add More
| Item Details | Price | ||
|---|---|---|---|
In the rapidly evolving landscape of artificial intelligence and machine learning, developing powerful models is only half the battle. The true challenge lies in reliably deploying, scaling, and maintaining these models in real-world production environments. This is precisely where MLOps, or Machine Learning Operations, enters the picture. MLOps is not just a buzzword; it represents a fundamental shift in how organizations approach the entire machine learning lifecycle, transforming experimental endeavors into robust, operationalized systems.
This detailed guide aims to demystify MLOps for intermediate learners, exploring its core principles, maturity levels, essential components, and popular tools. By understanding these deeper concepts, practitioners can bridge the gap between ML development and operations, ensuring their AI initiatives deliver sustained value.
MLOps is an engineering discipline designed to unify the development (Dev) and operations (Ops) of machine learning systems. Its primary objective is to standardize and streamline the continuous delivery of high-performing models in production environments.
This approach signifies more than just adopting new software tools; it represents a profound cultural and organizational transformation. It necessitates a fundamental change in how data scientists, ML engineers, and operations teams collaborate and perceive their roles within the ML lifecycle. The focus shifts from isolated model development to a shared responsibility for integrated, production-ready systems. This broader implication means that organizations embarking on an MLOps journey must invest not only in the right technologies but also in fostering cross-functional collaboration, dismantling traditional silos, and cultivating a collective understanding of the end-to-end ML system. This cultural alignment often presents a more significant hurdle than the technical implementation itself.
Despite the significant investment in data science, a substantial number of machine learning projects—approximately 75%—never successfully transition from experimental stages to full production, or they incur considerable resource and time overruns.
Traditional data science workflows often involve manual, experimental work conducted within isolated Jupyter notebooks. This approach frequently leads to several critical issues, including models remaining perpetually in development environments, manual and error-prone retraining processes, a complete lack of traceability for data and models, and significant difficulties in scaling experiments or fostering effective team collaboration.
The core challenges that MLOps seeks to address are multifaceted:
These challenges collectively represent what has been termed "hidden technical debt" in machine learning systems.
While ML systems are, at their core, software systems that can significantly benefit from established DevOps practices like continuous integration (CI) and continuous delivery (CD), they possess unique characteristics that necessitate a specialized approach. MLOps shares foundational similarities with DevOps but diverges in several critical areas:
Similarities:
Crucial Differences:
Continuous Practices (CI/CD/CT):
The fundamental difference between MLOps and DevOps lies in the "data-centric" nature of ML systems. Unlike traditional software, where code is the primary artifact that changes and drives updates, ML systems are fundamentally driven by data. Changes in data distribution, quality, or volume directly impact model performance, even if the underlying code remains static. This inherent data-centricity necessitates continuous monitoring of data and models in production, automated retraining, and robust data versioning—practices that are not as central or complex in traditional DevOps. The paradigm shift, where data effectively "writes" the software, makes the operationalization of ML systems uniquely challenging and distinct.
Effective MLOps is built upon a set of foundational principles that guide the development, deployment, and maintenance of machine learning systems. These principles ensure reliability, reproducibility, and continuous improvement.
MLOps embraces an iterative-incremental development process, mirroring agile methodologies to adapt to the experimental nature of machine learning. This process is structured into three broad, interconnected phases: "Designing the ML-powered application," "ML Experimentation and Development," and "ML Operations".
These three phases are profoundly interconnected, with decisions made in one stage propagating and influencing subsequent stages. For instance, an architectural decision made during the design phase will inevitably impact the experimentation process and ultimately shape the deployment options during operations.
Automation is the cornerstone of MLOps, serving as the engine that drives efficiency, velocity, and reliability throughout the machine learning lifecycle. The overarching objective is to automate all steps of the ML workflow, eliminating manual intervention and significantly increasing the speed at which new models can be trained and deployed . This automation can be triggered by various events, including scheduled calendar events, messages from other systems, monitoring alerts (e.g., performance degradation), or changes in data, model training code, or application code .
Continuous Integration (CI) for ML
In the context of machine learning, Continuous Integration (CI) extends beyond traditional software CI practices. It involves regularly merging code changes into a shared repository, followed by automated testing to ensure that new code integrates seamlessly with the existing codebase . For ML, this means CI encompasses not only testing and validating code and components but also the critical validation of data, data schemas, and the models themselves.
The CI process in MLOps typically includes:
This expanded CI acts as a vital quality gate early in the development cycle. By automating rigorous tests for code, data quality, and model integrity before any deployment, it significantly reduces the risk of errors propagating downstream into production. This "shifting left" of quality assurance is paramount for achieving higher reliability and drastically cutting down on debugging time later in the process.
Continuous Delivery (CD) in MLOps differs from traditional software CD in its scope. It concerns the delivery of an ML training pipeline that automatically deploys another service—specifically, the ML model prediction service.
Key aspects of CD in MLOps include:
CD serves as the critical mechanism that translates the potential of a trained ML model into tangible business impact. Models that remain stuck in development notebooks provide no value.
Continuous Training (CT) is a property unique to machine learning systems, distinguishing MLOps from traditional DevOps. It focuses on the automatic retraining and serving of ML models . Models inherently need to be retrained to maintain their accuracy and relevance over time, as the underlying data they operate on continuously changes (known as data drift or concept drift) .
Retraining can be triggered in several ways:
CT ensures that the model in production makes the most accurate predictions possible with the most up-to-date data. It adapts the model to current data profiles, thereby maintaining its effectiveness, without necessarily changing the core parameters or underlying algorithm . This continuous adaptation transforms a static deployed model into an "adaptive intelligence" system that can continuously learn and improve. This capability is paramount for maintaining a competitive edge and ensuring reliable decision-making in dynamic, data-driven applications, serving as the ML system's self-correction mechanism.
Continuous Monitoring (CM) is indispensable in MLOps. It involves the ongoing monitoring of production data and the performance metrics of deployed ML models, often directly linked to key business metrics .
Key aspects continuously monitored include:
When issues are detected, alerts can be triggered, prompting actions such as model rollbacks or notifications to relevant teams . CM functions as an "early warning system" for the health of the ML system. It provides proactive detection of issues that can degrade model performance and negatively impact business outcomes. This proactive stance allows teams to intervene before major problems escalate, minimizing downtime, preventing potential financial losses, and maintaining user trust, making it an indispensable component for robust ML operations.
Versioning in MLOps is a critical principle that aims to treat all components of the machine learning system—training scripts, ML models, and data sets—as first-class citizens within version control systems . This comprehensive approach ensures the auditable and reproducible training of ML models.
Robust version control is crucial for several reasons:
Tools such as Data Version Control (DVC) and MLflow are widely used to manage data and model versioning, often integrating seamlessly with standard code version control systems like Git . Versioning serves as the bedrock of reproducibility and auditability in ML. Without comprehensive versioning of all ML artifacts—code, data, models, hyperparameters, and environments—reproducing a specific model's behavior or effectively debugging a production issue becomes nearly impossible. This lack of clear lineage renders ML systems opaque and untrustworthy. Therefore, versioning is not merely a best practice; it is a fundamental requirement for building auditable, trustworthy, and debuggable ML systems, particularly in regulated industries, and it instills scientific rigor into the engineering process.
Machine learning development is inherently iterative and research-centric, often involving the execution of multiple parallel experiments.
Effective experiment tracking involves logging and querying a wide array of information:
Hyperparameters: The configuration parameters used during model training. Metrics: Performance indicators such as accuracy, precision, recall, F1-score, loss, etc.. Code Versions: The specific version of the training code used for each experiment . Output Files: Generated artifacts like trained model weights, evaluation reports, and visualizations . Datasets: The specific versions or subsets of data used for training and validation .
This comprehensive logging helps in comparing different experimental runs, visualizing their outcomes, and ultimately selecting the best-performing model based on predefined criteria.
Experiment tracking functions as the "memory" of ML development. Without it, data scientists can easily lose track of which configurations led to successful results, or why a particular experiment yielded certain outcomes. This can lead to wasted effort, difficulty in reproducing "successful" models, and a fragmented understanding of the development process. By providing a systematic record, experiment tracking enables data scientists to efficiently manage the vast number of trials, compare outcomes effectively, and understand the lineage of their models, thereby accelerating the discovery of optimal solutions and fostering more effective collaboration within teams.
Testing in MLOps is significantly more complex and multifaceted than in traditional software development, primarily due to the dynamic nature of data and the probabilistic behavior of machine learning models.
A "ML Test Score System" can be used to measure the overall readiness of the ML system for production, providing a quantifiable assessment of its robustness.
Reproducibility in MLOps means that every phase of data processing, ML model training, and ML model deployment should consistently produce identical results given the same input conditions . This principle is fundamental for building trustworthy, auditable, and debuggable machine learning systems.
Achieving reproducibility involves meticulously addressing challenges across the entire ML lifecycle:
Reproducibility is the "scientific method" applied to ML engineering. In scientific research, reproducibility is foundational for validating findings and building upon previous work. Similarly, for ML systems to be reliable and trustworthy, they must adhere to this standard. It allows teams to verify past results, debug issues by re-running specific conditions, and build new models with confidence that their foundational components are stable. It elevates ML development from an art to a more rigorous, engineering discipline.
A core principle in MLOps is the adoption of a loosely coupled architecture, which promotes modularity within the ML system. This architectural approach enables different teams to work independently on specific components or services, allowing them to test and deploy these parts without strong dependencies on other teams' work.
While achieving true loose coupling can be challenging in ML systems due to the often interleaved dependencies between various ML components (e.g., a feature engineering module directly impacting a model training module), establishing standard project structures and clear interfaces can significantly help.
Modularity serves as a key enabler of scalability and agility. As ML initiatives grow within an organization, multiple teams often need to collaborate on different aspects of the same or related ML pipelines. A loosely coupled architecture prevents bottlenecks and single points of failure that typically arise from tightly coupled systems. It facilitates parallel development, enables faster iteration cycles, and simplifies maintenance, all of which are critical for scaling ML operations across an organization and adapting quickly to new requirements or technological advancements.
| Principle |
Purpose/Definition | Why it Matters in MLOps |
| Iterative-Incremental Development |
An agile approach to ML, structured in design, experimentation, and operations phases. | Allows continuous refinement and adaptation of ML solutions to evolving needs and data. |
| Automation (CI/CD/CT/CM) | Automating the entire ML workflow, including code, data, model integration, delivery, training, and monitoring. | Increases velocity, reduces manual errors, ensures consistent and rapid deployment of models. |
| Versioning | Tracking and controlling changes to all ML artifacts: code, data, models, and parameters. | Guarantees reproducibility, enables traceability, facilitates collaboration, and allows for reliable rollbacks. |
| Experiment Tracking | Systematically logging and managing parameters, metrics, and artifacts from ML experiments. | Provides a "memory" for ML development, enabling efficient comparison, selection, and reproduction of models. |
| Robust Testing | Comprehensive validation of data integrity, model quality, performance, and ethical considerations. | Ensures reliability, identifies biases, validates model behavior, and builds trust in AI systems. |
| Reproducibility | The ability to consistently achieve identical results from every phase of the ML lifecycle given the same inputs. | Fundamental for debugging, auditing, and ensuring the consistency and trustworthiness of ML models. |
| Loosely Coupled Architecture | Designing ML systems with independent, interchangeable components and clear interfaces | Enhances scalability, promotes agility, enables parallel development, and simplifies maintenance and updates. |
MLOps maturity models provide a structured framework for organizations to assess their current state of machine learning operationalization and plan their strategic advancement. Google's model, one of the earliest and most widely recognized, outlines three distinct levels of MLOps maturity.
This is the most basic level of MLOps maturity, characterized by entirely manual processes for building and deploying machine learning models.
The manual, disconnected nature of Level 0 directly contributes to the high failure rate of ML projects, where a significant percentage never make it to production.
The primary goal of MLOps Level 1 is to achieve Continuous Training (CT) by automating the entire ML pipeline, which in turn leads to the continuous delivery of the model prediction service.
Level 1 directly addresses the dynamic nature of ML models, which require frequent updates due to changing data. By automating the core training and deployment loop, it significantly reduces manual effort, improves model freshness, and ensures that models can adapt to evolving data. This moves organizations beyond static, brittle deployments. However, a limitation at this level is that manual testing and deployment of new pipeline implementations are still common. While suitable for continuously updating existing models with new data, it is not optimized for rapid deployment of entirely new ML ideas or for efficiently managing a large portfolio of diverse pipelines.
MLOps Level 2 represents the highest maturity level, introducing a robust automated CI/CD system specifically designed for rapid and reliable updates of the ML pipelines themselves in production.
Level 2 addresses the challenge of managing a growing number of ML models and pipelines at scale. By automating the deployment and updates of the entire ML pipeline itself, organizations can rapidly iterate on new ML ideas, deploy new models, and manage complex portfolios of AI solutions with high reliability and efficiency. This level is essential for organizations where ML is a core business function and needs to scale across numerous applications and teams.
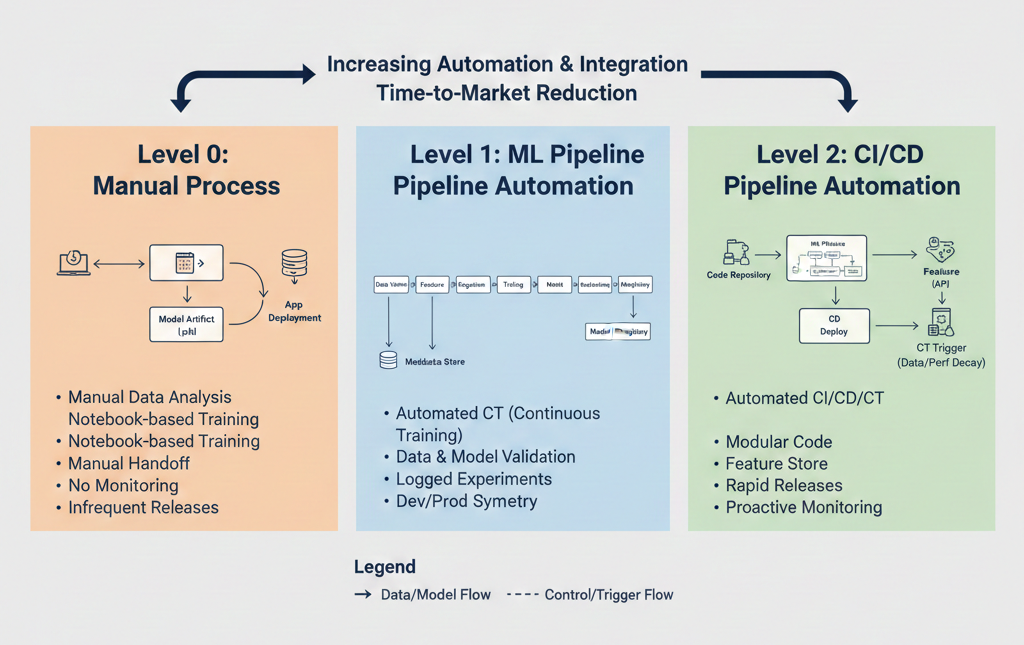
Diagram: MLOps Maturity Levels Progression. A block diagram illustrating the progression from Level 0 (Manual) to Level 1 (ML Pipeline Automation) and Level 2 (CI/CD Pipeline Automation). Each level highlights increasing degrees of automation and integration.
A robust MLOps architecture brings together various specialized components that work in harmony to manage the entire machine learning lifecycle. Think of these as the building blocks that enable automation, collaboration, and continuous improvement.
Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the industry's standard dummy text ever since the 1500s, when an unknown printer took a galley of type and scrambled it to make a type specimen book.
A crucial component that often integrates with the data pipeline is the Feature Store.
Model RegistryOnce you've trained a model, you need a place to store, track, and manage it. That's where the Model Registry comes in.
ML Pipeline OrchestrationAutomating the entire ML workflow requires a conductor, and that's the role of the ML Pipeline Orchestrator .
Once a model is trained and validated, it needs to be made available for use by applications and end-users. This is the role of Model Serving .
Deploying a model isn't the end; it's just the beginning of its life in production. Monitoring and Alerting are critical for ensuring the model continues to perform as expected .
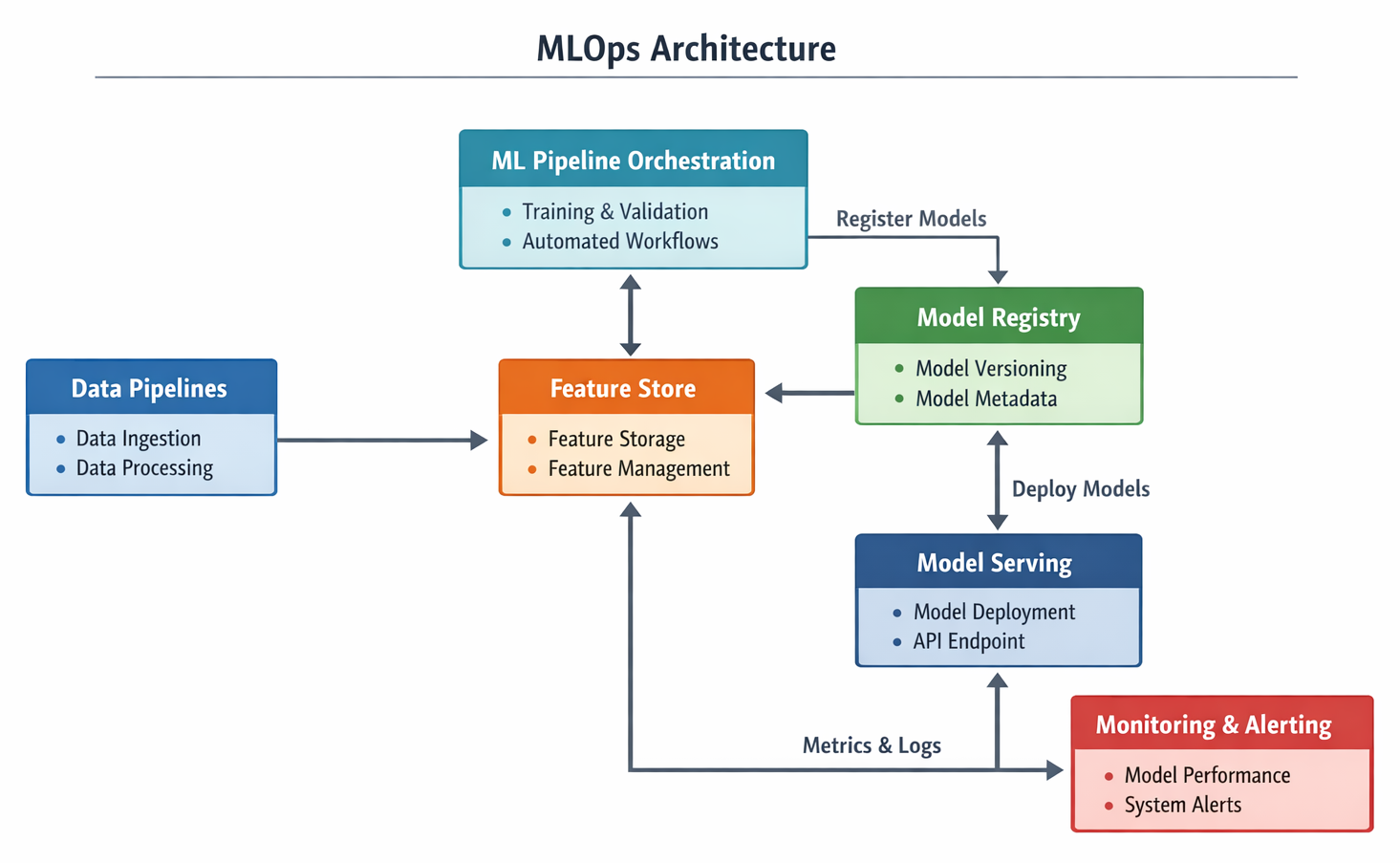
Diagram: Conceptual MLOps Architecture with Key Components. A block diagram illustrating the interconnected components of an MLOps architecture, including Data Pipelines, Feature Store, ML Pipeline Orchestration, Model Registry, Model Serving, and Monitoring & Alerting, showing the flow of data and models.
The MLOps ecosystem is rich with tools and platforms, ranging from comprehensive cloud-native solutions to flexible open-source frameworks. Choosing the right tools depends on your organization's specific needs, existing infrastructure, and team expertise.
Major cloud providers offer integrated MLOps platforms that provide end-to-end capabilities, often with deep integration into their broader cloud ecosystems.
pip and conda dependencies for consistent builds.For those seeking more control, flexibility, or on-premises deployments, a robust ecosystem of open-source MLOps tools is available.
.dvc files) that Git versions, while the actual data is stored externally (e.g., cloud storage) .dvc.yaml that connect stages like preprocessing and training .Other notable open-source MLOps tools include Pachyderm (version control for data and ML projects on Docker/Kubernetes), Metaflow (Netflix's platform for building and managing enterprise data science projects), Seldon Core (streamlines ML workflows with logging, metrics, and model serving), and Feast (a feature store) .
Let's walk through a simplified MLOps workflow, from an initial notebook experiment to an automated production system, including how automated retraining might be triggered.
Many ML projects start in a Jupyter Notebook, where data scientists explore data, experiment with algorithms, and tune hyperparameters.
1. Notebook Experimentation:
RandomForestClassifier), and tune hyperparameters. Focus on getting the model to perform well on your test data.# In your Jupyter Notebook (initial exploration)
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# Load your data (e.g., from a CSV)
data = pd.read_csv("your_dataset.csv")
X = data.drop("target", axis=1)
y = data["target"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Train a simple model
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Evaluate
predictions = model.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
print(f"Initial Model Accuracy: {accuracy}")
my_ml_project directory):# Initialize Git and DVC
git init
dvc init
git commit -m "Initialize DVC"
# Add your dataset to DVC (e.g., a 'data' directory)
dvc add data/
git add data/.dvc.gitignore
git commit -m "Add initial dataset with DVC"
# Define your ML pipeline in dvc.yaml
# This tells DVC how to run your training script and what its dependencies/outputs are
# dvc.yaml example:
# stages:
# train:
# cmd: python train.py
# deps:
# - data/
# - train.py
# outs:
# - model.joblib
# metrics:
# - accuracy.json:
# cache: false
# Run the DVC pipeline (this will execute train.py)
dvc repro
# Commit the pipeline definition and model metadata to Git
git add .
git commit -m "Add training pipeline and initial model"
This dvc.yaml defines a train stage that runs train.py, depends on data/ and train.py, and outputs model.joblib and accuracy.json .
train.py:import mlflow
import mlflow.sklearn
import joblib
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import pandas as pd
# Assume data loading and splitting happens here
data = pd.read_csv("data/your_dataset.csv") # DVC ensures this is the correct version
X = data.drop("target", axis=1)
y = data["target"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
with mlflow.start_run():
# Log hyperparameters
n_estimators = 100
mlflow.log_param("n_estimators", n_estimators)
# Train model
model = RandomForestClassifier(n_estimators=n_estimators, random_state=42)
model.fit(X_train, y_train)
# Evaluate and log metrics
predictions = model.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
mlflow.log_metric("accuracy", accuracy)
# Save model artifact
mlflow.sklearn.log_model(model, "random_forest_model")
joblib.dump(model, "model.joblib") # For DVC tracking
print(f"Model trained with accuracy: {accuracy}")
#.github/workflows/mlops_pipeline.yaml (simplified)
name: MLOps CI/CD Pipeline
on:
push:
branches:
- main
paths:
- 'src/**' # Trigger on code changes
- 'data/**' # Trigger on data changes (via DVC.dvc files)
jobs:
# CI Job: Build, Test, Package
integration:
runs-on: ubuntu-latest
steps:
- name: Checkout Code
uses: actions/checkout@v3
- name: Set up Python
uses: actions/setup-python@v4
with:
python-version: '3.9'
- name: Install Dependencies
run: pip install -r requirements.txt dvc mlflow scikit-learn pandas
- name: Pull DVC Data
run: dvc pull # Ensure correct data version is pulled
- name: Run Unit Tests
run: python -m unittest discover tests/unit # Test feature engineering, model logic
- name: Run Model Training & Log with MLflow
run: python src/train.py # This script trains model and logs to MLflow
- name: Evaluate Model Performance
run: python src/evaluate.py # Script to run performance tests, e.g., accuracy, bias
- name: Build Docker Image
run: docker build -t my-ml-model:latest .
- name: Push Docker Image to Registry
#... (e.g., to ECR, GCR, Azure Container Registry)
# CD Job: Deploy Model
deployment:
needs: integration # Depends on CI job
runs-on: self-hosted # Or cloud-managed runner
steps:
- name: Pull Docker Image
#... (pull image from registry)
- name: Deploy Model to Production
#... (e.g., update Kubernetes deployment, SageMaker endpoint, Vertex AI endpoint)
- name: Run Post-Deployment Tests (Canary/A/B)
#... (monitor live traffic, compare performance)
- name: Register Model in Model Registry
#... (e.g., MLflow Model Registry, SageMaker Model Registry)
This YAML outlines a basic CI/CD pipeline. The integration job handles code and data validation, model training, and containerization. The deployment job then takes the validated artifacts and deploys them to production .
A key advantage of MLOps is the ability to automatically retrain models when their performance degrades in production, often due to data drift.
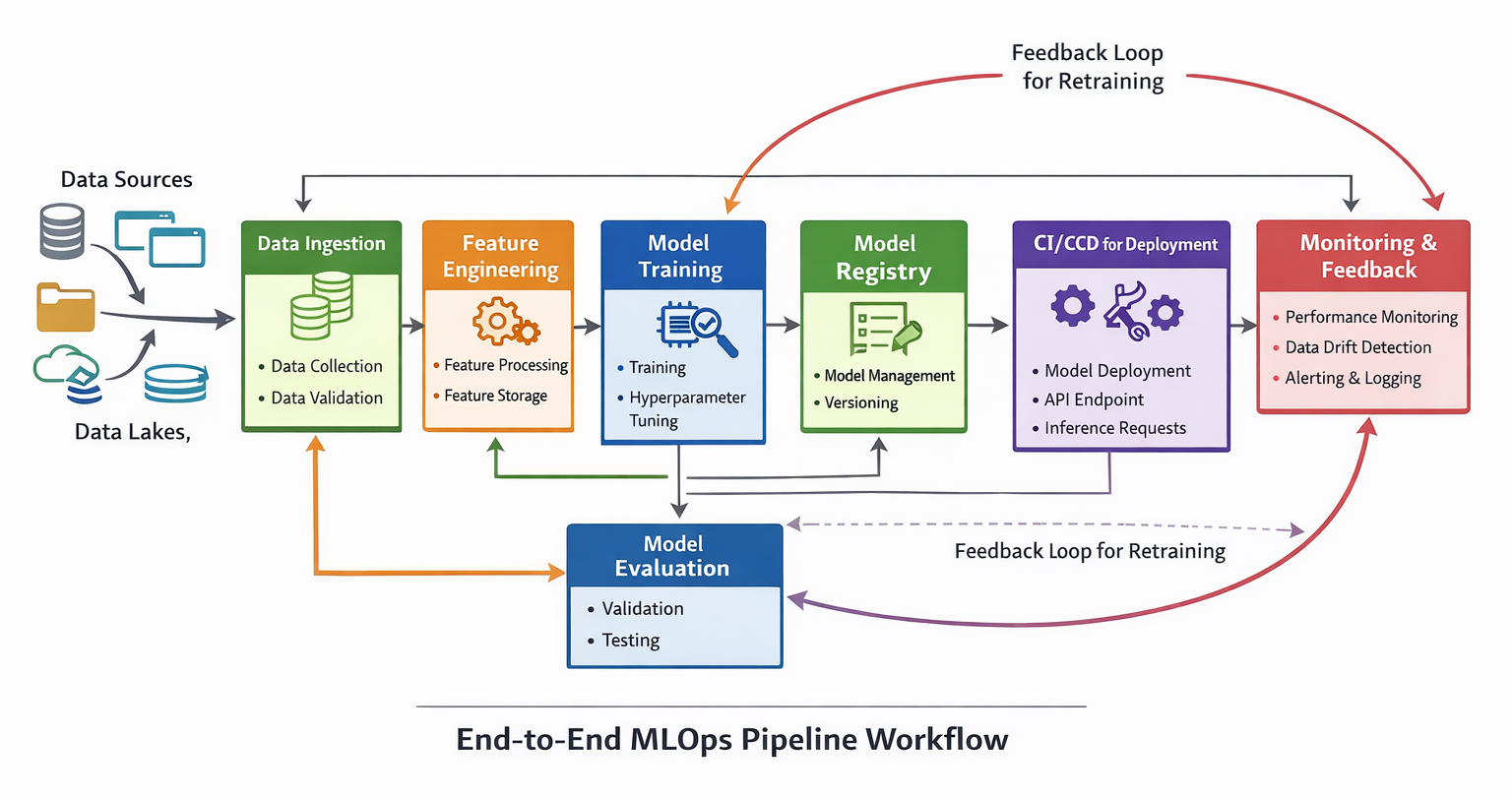
Diagram: End-to-End MLOps Pipeline Workflow. A detailed block diagram illustrating the end-to-end MLOps pipeline, starting from data ingestion, through feature engineering, model training, evaluation, model registry, CI/CD for deployment, model serving, and continuous monitoring with a feedback loop triggering retraining.
We've covered a lot of ground, from the fundamental definition of MLOps and its crucial differences from traditional DevOps, to its core principles, maturity levels, essential architectural components, and popular tools. The takeaway is clear: MLOps is no longer a luxury but a necessity for organizations serious about leveraging machine learning at scale.
By embracing MLOps, you can:
The journey to full MLOps maturity is iterative, but every step you take towards automation, versioning, and continuous practices will bring significant returns on your AI investments.
Ready to operationalize your machine learning? Start by assessing your current MLOps maturity, then pick one core principle—like versioning your data and models with DVC and MLflow, or setting up a simple CI/CD pipeline for your training code. Experiment with cloud-native services like AWS SageMaker, Azure ML, or Google Cloud Vertex AI to see how they can streamline your workflows. The future of AI is operational, and MLOps is your roadmap to getting there.
 Launch your Graphy
Launch your Graphy